 AI悦创
AI悦创




▲ 点击上方第二个“AI悦创”关注公众号
回复“3”加微信入群

办公自动化 丨作者 / AI悦创 排版 / 悦创
这几篇的阅读量很一般,还是希望大家多多转发分享,我将持续分享。这也是我的动力!
1. 读取 docx 所需库
自动生成《背影》word 文档,以及自动生成日期的脚本代码已经完成。
本文的主要内容,是自动的读取 word 文档的内容,将 word 中的表格、段落文字,以及图片全部读取出来。
这里需要用到的库,是前面用到的 python-docx 库,以及额外的一个 docx2python。
安装命令:
pip install python-docx docx2python
2. 段落的输出
安装好之后,先使用 python-docx 库,读取 word 文件的段落内容,如下代码:
from docx import Document
document = Document('背影-read.docx')
for paragraph in document.paragraphs:
print(paragraph.text)
这段代码,就是针对 document 文档的段落进行并输出,就是文档的全部文字内容,没有任何的格式。
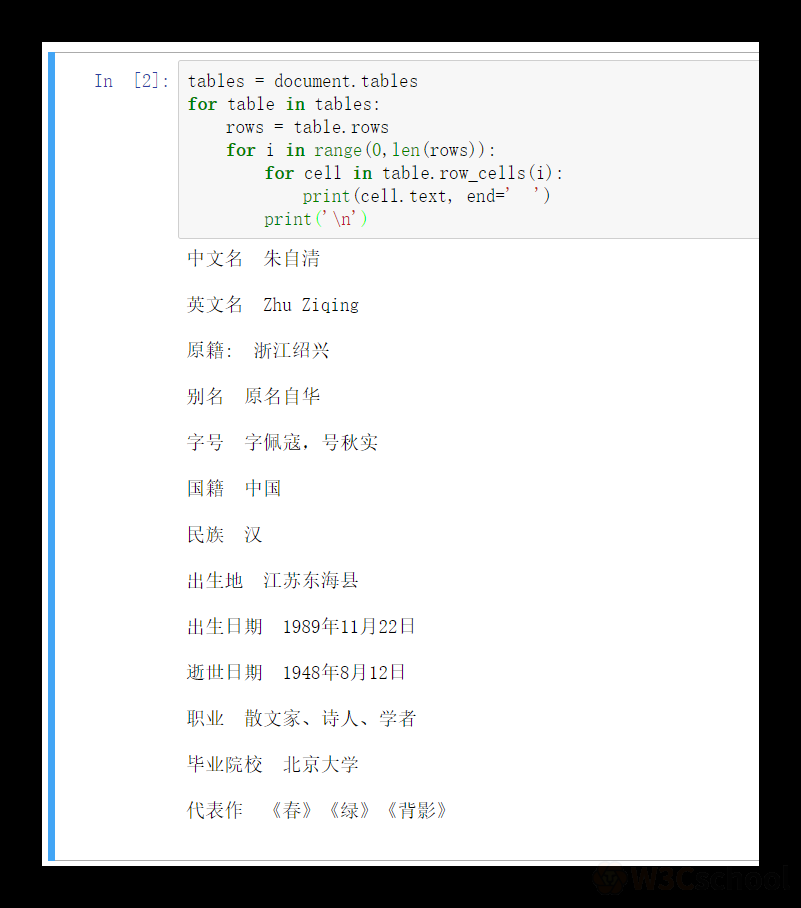
3. 表格的输出
然后是表格的输出,如下代码:
tables = document.tables
for table in tables:
rows = table.rows
for i in range(0, len(rows)):
for cell in table.row_cells(i):
print(cell.text, end=' ')
print('\n')
详细的代码介绍:
document.tables 是获取文档的全部表格,然后进入第一个 for 循环,逐个表格取出并处理 table.rows 是获取行对象,使用len()函数,就可以取到行数 然后循环,从 0 取到最后一行 使用 table.row_cells(i) 获取当前行的所有 cell 单元格,使用 for 循环获取每个 cell 然后输出所有 cell 单元格的文本内容,并且换行是空字符串,这是为了将每行的内容,输出时也是一样 然后在一行输出结束时,加换行,将每行内容都分开
以上是表格的代码部分,如下输出结果:
4. 图片的获取和保存
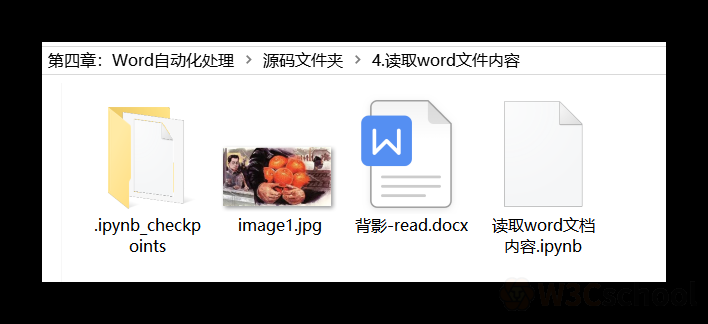
最后一个是读取图片,由于在命令行中,无法输出图片,所以这里的操作,是将所有的图片保存到word文档旁边,如下代码:
from docx2python import docx2python
document2 = docx2python('背影-read.docx')
for name, imageData in document2.images.items():
with open(name, 'wb') as fp:
fp.write(imageData)
这里使用的是 docx2python 库,这个属于一个 docx 的拓展库。
打开文件,读取文档的全部图片名和字节,然后保存即可,如下效果:
背景-read.docx 是目标文档。
读取word文档内容.ipynb 是课程源码,启动 jupyter 即可查看源码并运行。「点击阅读原文,即可获取源码」




