
我用24小时、8块GPU、400美元在云上完成训练BERT!
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
大型语言模型BERT,熟悉NLP领域的同学没人不知道它的名气吧?
只可惜它太太太贵了!
之前有做过统计,使用谷歌云TPU或英伟达GPU训练完整个模型需要虽然只需1个小时,但是上千块TPU/GPU均需耗价上万美元。
只有少数“富贵人家”的行业实验室才能够负担得起。
为了降低成本,来自以色列的科学家们结合已有的技术对BERT做了多方面优化,只需24小时、8个12GB内存的云GPU,一次几百美元就能在加快训练过程的同时,还能保证准确性几乎不损失。
终于,“普通家庭”也不怕“囊中羞涩”了。
24小时、8个云GPU(12GB内存)、$300-400
为了模拟一般初创公司和学术研究团队的预算,研究人员们首先就将训练时间限制为24小时,硬件限制为8个英伟达Titan-V GPU,每个内存为12GB。
参考云服务的市场价格,每次训练的费用大约在300到400美元之间。
此前很多人尝试用最新的算法(eg.clark-etal-2020-learning等)来减少训练BERT所需的计算过程。
而这批研究人员们选择回归BERT模型本身进行优化。
他们结合了各种最新的技术来优化掩码语言模型(masked language model)。虽然这些技术以前都被使用过,但这是它们首次作为一个统一的框架组合出现。
五点优化:将训练时间缩短了1/3
首先分别进行了以下五点优化:
数据:由于研究人员的重点是句子分类,他们便将整个预训练过程的序列长度限制为128个标记。并使用单序列训练。为了减少在验证集上计算性能所花费的时间,只保留0.5%的数据(80MB),并且每30分钟计算一次验证损失(validation loss)。
模型:训练了一个大模型,因为在相同的挂钟时间Li2020TrainLT下,较大的模型往往比较小的模型获得更好的性能。
优化程序:研究人员借鉴了RoBERTa的优化,采用如下参数:β1 = 0.9, β2 = 0.98, ε = 1e-6, 权重衰减 = 0.01, dropout = 0.1, attention dropout = 0.1。
软件:使用的是DeepSpeed软件包,修改了部分实现,将掩码语言模型的预测头替换为稀疏标记预测。
I/O:为了减少I/O瓶颈,研究人员采用devlin-etal-2019-bert的技术并将原始语料库的10个副本预屏蔽(pre-mask)。
将优化后的框架和官方发布实现比较后发现:
使用官方代码训练基本模型需要近6天的时间,训练大型模型需要多达26天。
相比之下,研究人员优化后显著加快了训练速度,将训练大型模型的时间缩短了2/3(8天)。如果扩大batch size,则只需不到3天。

超参数调优:MLM损耗更低
超参数配置是提高深度学习模型和NLP的性能关键。
为了适应该项目的低配设置,研究人员参考的此前的一些技术实现对4个超参数进行了调优。
1、Batch Size (bsz):由于每个GPU上显存有限,分别设置为4096、8192和16384。
2、峰值学习率(lr):使用线性学习速率,从0开始,预热到最高学习速率后衰减到0。分别设置为5e-4、1e-3和2e-3。
3、预热学习率(wu):分别设置为0%、2%、4%和6%,成比例“预热”。
4、总天数(days):学习率调度器衰减回0所需的总天数。分别设置为1、3、9。
依据以上的超参数配置,最终筛选出的能够在24小时之内完成训练的配置参数。
下表是按MLM损耗计算的最佳配置。
MLM:masked language modeling掩码语言模型
可以发现,该团队的优化后的性能远远高于使用BERT默认超参数。

最后,选择性能最佳的优化模型“Search #1”将其命名为“24hBERT”,与BERT模型先前配置的学习曲线进行比较也能发现,24hBERT收敛明显提前, MLM损耗更低。
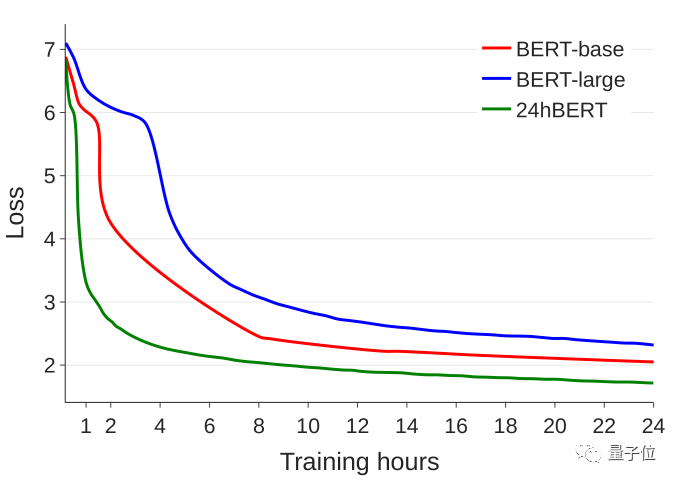
最后,研究人员表示该优化方法可能需要一段时间来适应目前的硬件和时间限制。
他们也希望这次研究能让更多的人参与进来,让训练BERT模型这件“核弹级别”的操作变得更“接地气儿”。
GitHub传送门:https://github.com/peteriz/academic-budget-bert
参考链接:
[1]https://arxiv.org/abs/2104.07705
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。

点个在看 paper不断!