 大邓和他的Python
大邓和他的Python




本文转载自
https://aistudio.baidu.com/aistudio/projectdetail/507159
转载过程中,文章内很多链接变为文字,失去了跳转功能。如果对图像处理感兴趣的同学,请收藏上方链接
OCR中文识别快速在线体验
https://www.paddlepaddle.org.cn/hub/scene/ocr
引入
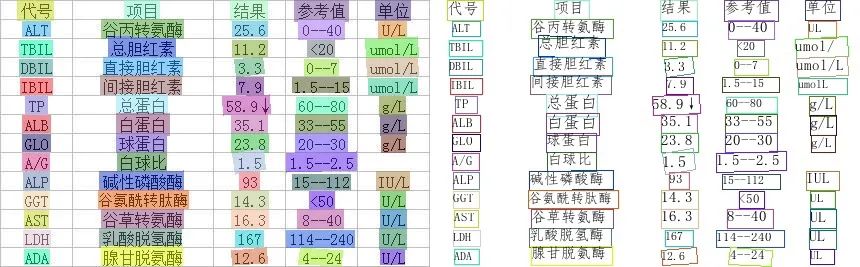
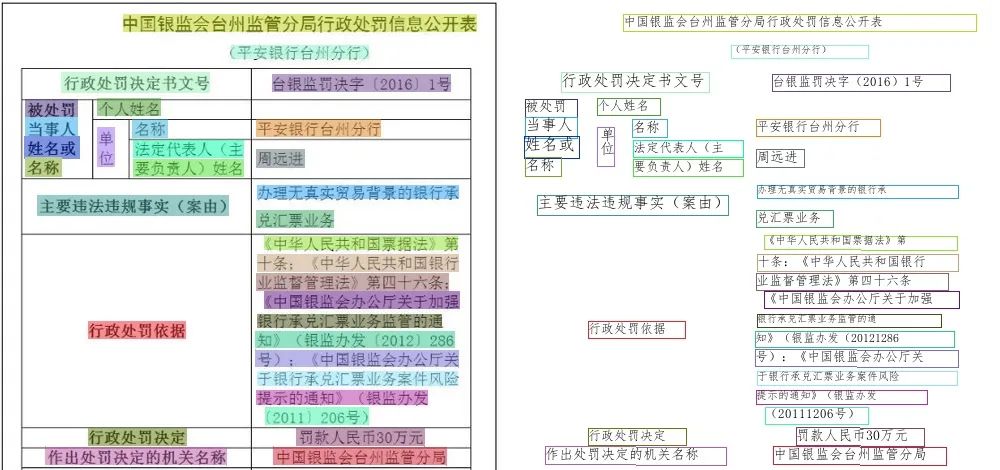
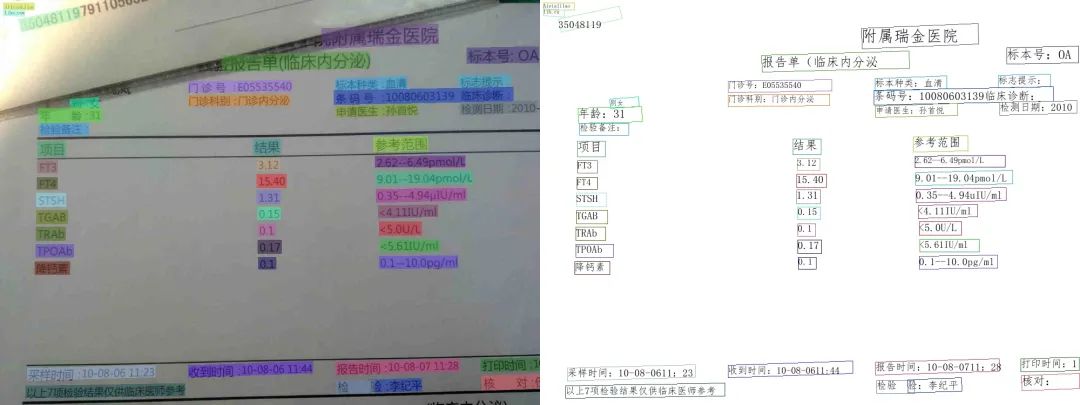
光学字符识别(Optical Character Recognition, OCR)是指对文本材料的图像文件进行分析识别处理,以获取文字和版本信息的过程。也就是说将图象中的文字进行识别,并返回文本形式的内容。例如(该预测效果基于PaddleHub一键OCR中文识别效果展示):
(1) 
(2) 
(3) 
(4) 
(5) 
(6) 
PaddleHub现已开源OCR文字识别的预训练模型(2020/09/21更新超轻量ppocrmobile系列和通用ppocrserver系列中英文ocr模型,媲美商业效果。)
移动端的超轻量模型:超轻量ppocr_mobile移动端系列:检测(2.6M)+方向分类器(0.9M)+ 识别(4.6M)= 8.1M,仅有8.1M。chinese_ocr_db_crnn_mobile(1.1.0最新版)。
模型地址
https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_crnn_mobile&en_category=TextRecognition
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
模型地址
https://www.paddlepaddle.org.cn/hubdetail?name=chinese_ocr_db_crnn_server&en_category=TextRecognition
该 Module 用于识别图片当中的汉字、数字、字母。如果仅需要检测,也可单独使用chinese_text_detection_db_server或者chinese_text_detection_db_mobile得到检测结果的文本框
开发者可以基于PaddleHub提供的OCR中文识别Module,实现一键文字识别,适用于常见的OCR应用场景中。
注:本教程主要针对需要一键预测文字识别的用户使用,如果需要自定义数据集重新训练或者Finetuning的,可以参考PaddleOCR了解更多。
前要
OCR的应用场景
根据OCR的应用场景而言,我们可以大致分成识别特定场景下的专用OCR以及识别多种场景下的通用OCR。就前者而言,证件识别以及车牌识别就是专用OCR的典型案例。针对特定场景进行设计、优化以达到最好的特定场景下的效果展示。那通用的OCR就是使用在更多、更复杂的场景下,拥有比较好的泛性。在这个过程中由于场景的不确定性,比如:图片背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等等问题,会带来极大的挑战。现PaddleHub为大家提供的是超轻量级中文OCR模型,聚焦特定的场景,支持中英文数字组合式别、竖排文字识别、长文本识别场景。
OCR的技术路线
典型的OCR技术路线如下图所示:

其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。PaddleHub为大家开源的预训练模型的网络结构是Differentiable Binarization+ CRNN,基于icdar2015数据集下进行的训练。
首先,DB是一种基于分割的文本检测算法。在各种文本检测算法中,基于分割的检测算法可以更好地处理弯曲等不规则形状文本,因此往往能取得更好的检测效果。但分割法后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。因此作者提出一个可微的二值化模块(Differentiable Binarization,简称DB),将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。DB算法最终在5个数据集上达到了state-of-art的效果和性能。参考论文:Real-time Scene Text Detection with Differentiable Binarization
下图是DB算法的结构图:
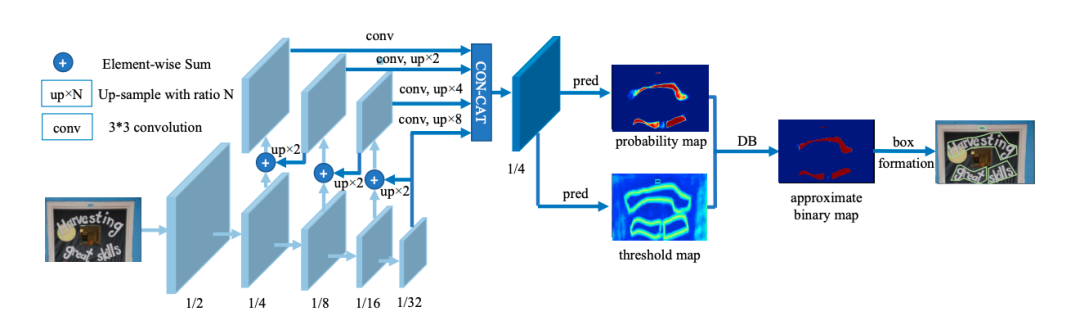
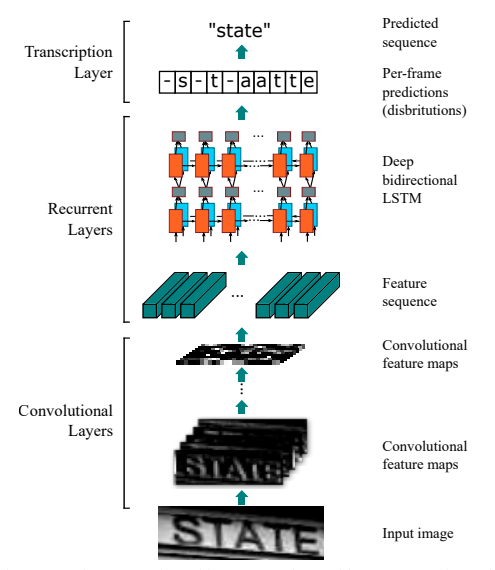
接着,我们使用 CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络,是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。参考论文:An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition
下图是CRNN的网络结构图:
一、定义待预测数据
以本示例中文件夹下图片为待预测图片。本教程为大家总共提供了5个具体场景下的ocr识别,分别是「身份证识别」、「火车票识别」、「快递单识别」、「广告信息识别」、「网络图片文字识别」。
注:该 Moudle 目前只支持一键预测,这五个场景是预测效果比较好的应用场景,大家也可以自己去尝试在感兴趣的场景下使用
In [1]
#需要将PaddleHub和PaddlePaddle统一升级到2.0版本
!pip install paddlehub==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddlepaddle==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
#该Module依赖于第三方库shapely、pyclipper,使用该Module之前,请先安装shapely、pyclipper
!pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simpleIn [2]
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 待预测图片
test_img_path = ["./advertisement.jpg", "./pics.jpg", "./identity_card.jpg", "./express.jpg", "./railway_ticket.jpg"]
# 展示其中广告信息图片
img1 = mpimg.imread(test_img_path[0])
plt.figure(figsize=(10,10))
plt.imshow(img1)
plt.axis('off')
plt.show()若是待预测图片存放在一个文件中,如左侧文件夹所示的test.txt。每一行是待预测图片的存放路径。
In [3]
!cat test.txtadvertisement.jpg
pics.jpg
identity_card.jpg
express.jpg
railway_ticket.jpg用户想要利用ocr模型识别图片中的文字,只需读入该文件,将文件内容存成list,list中每个元素是待预测图片的存放路径。
In [4]
with open('test.txt', 'r') as f:
test_img_path=[]
for line in f:
test_img_path.append(line.strip())
print(test_img_path)['advertisement.jpg', 'pics.jpg', 'identity_card.jpg', 'express.jpg', 'railway_ticket.jpg']
二、加载预训练模型
PaddleHub提供了以下文字识别模型:
移动端的超轻量模型:仅有8.1M,chinese_ocr_db_crnn_mobile。
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
识别文字算法均采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module支持直接预测。移动端与服务器端主要在于骨干网络的差异性,移动端采用MobileNetV3,服务器端采用ResNet50_vd。
In [5]
import paddlehub as hub
# 加载移动端预训练模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")Download https://bj.bcebos.com/paddlehub/paddlehub_dev/chinese_ocr_db_crnn_mobile_1.1.1.tar.gz
[##################################################] 100.00%
Decompress /home/aistudio/.paddlehub/tmp/tmpfnkr9e05/chinese_ocr_db_crnn_mobile_1.1.1.tar.gz
[##################################################] 100.00%
[2021-03-03 13:59:48,463] [ INFO] - Successfully installed chinese_ocr_db_crnn_mobile-1.1.1
[2021-03-03 13:59:48,473] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
三、预测
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。
In [6]
import cv2
# 读取测试文件夹test.txt中的照片路径
np_images =[cv2.imread(image_path) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.5) # 识别中文文本置信度的阈值;
for result in results:
data = result['data']
save_path = result['save_path']
for infomation in data:
print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])
Download https://bj.bcebos.com/paddlehub/paddlehub_dev/chinese_text_detection_db_mobile_1.0.4.tar.gz
[##################################################] 100.00%
Decompress /home/aistudio/.paddlehub/tmp/tmpi86077qf/chinese_text_detection_db_mobile_1.0.4.tar.gz
[##################################################] 100.00%
[2021-03-03 13:59:50,170] [ INFO] - Successfully installed chinese_text_detection_db_mobile-1.0.4
[2021-03-03 13:59:50,175] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
text: 小度在家1S
confidence: 0.9992504715919495
text_box_position: [[35, 25], [325, 25], [325, 76], [35, 76]]
text: 多功能专属儿童空间一高IQ流畅语音交互
confidence: 0.9422831535339355
text_box_position: [[31, 247], [163, 258], [158, 326], [27, 315]]
text: 小小这个
confidence: 0.8271657228469849
text_box_position: [[236, 249], [316, 249], [316, 261], [236, 261]]
text: 你好啊夏天
confidence: 0.9979197382926941
text_box_position: [[1081, 150], [1550, 321], [1520, 418], [1051, 246]]
text: 喝一杯压压惊
confidence: 0.9926337599754333
text_box_position: [[14, 764], [442, 660], [455, 728], [26, 832]]
text: 姓名徐乐
confidence: 0.9993003606796265
text_box_position: [[1612, 1944], [2609, 1955], [2609, 2064], [1612, 2053]]
text: 10010301110403F067846北京南售
confidence: 0.9994041323661804
text_box_position: [[1160, 2113], [2777, 2129], [2777, 2239], [1160, 2222]]
recognize_text()接口返回结果results说明:
results (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
text(str): 识别得到的文本
confidence(float): 识别文本结果置信度
text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标 如果无识别结果则data为[]
data (list[dict]): 识别文本结果,列表中每一个元素为 dict,各字段为:
save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为''
四、效果展示
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。在完成第三部分的一键OCR预测之后,由于我们设置了visualization=True,所以我们会自动将识别结果保存为图片文件,并默认保存在ocr_result文件夹中。刷新即可获取到新生成的ocr_result文件夹。
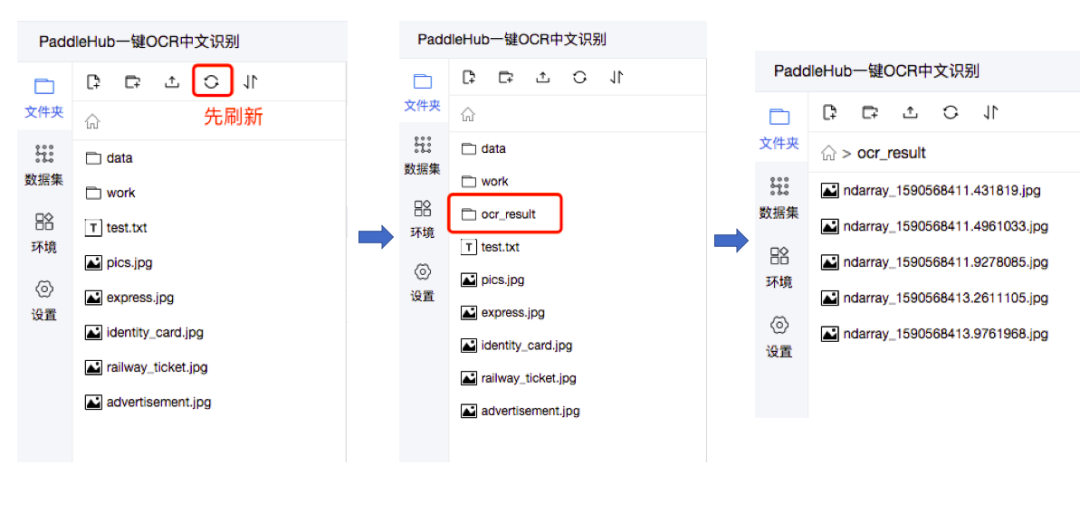
「身份证识别」、「火车票识别」、「快递单识别」、「广告信息识别」、「网络图片文字识别」五个场景下的效果展示



同时,作为一项完善的开源工作,除了本地推断以外,PaddleHub还支持将该预训练模型部署到服务器或移动设备中。
由于AIStudio不支持ip访问,以下代码仅做示例,如有需要,请在本地机器运行。
五、部署服务器
借助 PaddleHub,服务器端的部署也非常简单,直接用一条命令行在服务器启动文字识别OCR模型:
$ hub serving start -m chinese_ocr_db_crnn_mobile -p 8866
是的,在服务器端这就完全没问题了。相比手动配置各种参数或者调用各种框架,PaddleHub 部署服务器实在是太好用了。
只要在服务器端完成部署,剩下在客户端调用就不会有多大问题了。如下百度展示了调用服务器做推断的示例:制定要预测的图像列表、发出推断请求、返回并保存推断结果。
# coding: utf8
import requests
import json
import cv2
import base64
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_mobile"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])
相信只要有一些 Python 基础,在本地预测、以及部署到服务器端都是没问题的,飞桨的 PaddleHub 已经帮我们做好了各种处理过程。
六、结合PaddleHub其他预训练模型,尝试更多应用
OCR中文识别+文本审核模型 = 更酷炫鉴黄应用!!
PaddleHub作为预训练模型应用工具,在大家使用了OCR中文识别的任务之后,是不是可以在尝试结合Hub其他预训练模型,搭配使用来做更多有意义的事情呢?在这里,PaddleHub官方为大家提供了一个可行思路。在获取图片中的文字信息之后,可以进行黄色文本的审核,这块Hub也提供了几个鉴黄模型:porn_detection_lstm、porn_detection_gru、porn_detection_cnn 。这里就不做效果展示了,大家可以自行尝试结合,来鉴别下图片文字识别中到底有没有低俗信息
OCR中文识别+ ERNIE优化快递单信息抽取 = 更垂类的快递单信息抽取应用!!
PaddleHub为大家提供的语义预训练模型ERNIE,可以助力完成从快递单中抽取姓名、电话、省、市、区、详细地址等内容,形成结构化信息。辅助物流行业从业者进行有效信息的提取,从而降低客户填单的成本。使用PaddleHub语义预训练模型ERNIE优化快递单信息抽取
七、更多PaddleHub信息内容
PaddleHub全模型介绍文档、在线体验地址:PaddleHub官网
PaddleHub官方维护的课程内容,涵盖CV/NLP创意赛内容:PaddleHub官方课程
PaddleHub GitHub:https://github.com/PaddlePaddle/PaddleHub
PaddleHub使用过程中有任何问题欢迎在GitHub提issue
飞桨PaddleHub技术交流群(微信)

如扫码失败,请添加微信15711058002,并备注“Hub”,运营同学会邀请您入群。
八、更多PaddleOCR信息内容
PaddleOCR本次开源内容除了8.1M超轻量模型,同时提供了2种文本检测算法、4种文本识别算法,并发布了相应的4种文本检测模型、8种文本识别模型,用户可以在此基础上打造自己的超轻量模型。
想要使用自定义数据训练超轻量模型的小伙伴,可以参考8.6M超轻量模型的打造方式,从PaddleOCR提供的基础算法库中选择适合自己的文本检测、识别算法,进行自定义的训练。
PaddleOCR项目地址 https://github.com/PaddlePaddle/PaddleOCR
精选文章
系列视频|Python网络爬虫与文本数据分析 B站视频 | Python自动化办公 SciencePlots | 科研样式绘图库 使用streamlit上线中文文本分析网站 bsite库 | 采集B站视频信息、评论数据 texthero包 | 支持dataframe的文本分析包 爬虫实战 | 采集&可视化知乎问题的回答 reticulate包 | 在Rmarkdown中调用Python代码 plydata库 | 数据操作管道操作符>> plotnine: Python版的ggplot2作图库 读完本文你就了解什么是文本分析 文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用 plotnine: Python版的ggplot2作图库 Wow~70G上市公司定期报告数据集 漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
“分享”和“在看”是更好的支持


