
24.分布式系统的困境与NPC性别研究

1 楔子
最近每天晚上听凯叔西游记,我发现一个很有趣的事情:每当孙悟空要打听小道消息的时候,都会找当地的NPC(土地)。可见NPC这种角色自古有之,并不是网游里的特产,他们平时不怎么起眼,但关键时刻总能挺身而出,或者背后捅刀子。
不要问我为啥要听凯叔,都是为了知识,知识懂不~
不过今天,NPC可是我们的主角,它指代分布式系统中三个重要角色:N(Network网络)、P(Process进程)、C(Clock时钟)
2 Network
网络模型
年轻的时候看小电影,平时感觉还凑合的网络,关键时刻总是一卡一卡的,让人火大。即便这样,我觉得网络是底限的,虽然慢但好赖是靠谱的。直到我后来当了程序员,我才发现年轻的时候果然还是太年轻了。
程序员通常把两个节点之前的Point-to-Point通信叫link或channel,根据人品价格不同,至少可以分为三类:
Reliable (perfect) links:消息有可能乱序,但是不重不丢。不重不丢也就算了,但是『可能乱序』是个什么鬼?
Fair-loss links:消息可重、可丢、可乱序,但是只要发送端够努力,不断的retry,早晚能把消息发过去。请注意,这里我使用了早晚这个词。语文老师经常给我们讲『这个晚字用得好』。某条从济南发给北京的消息可能会先去泰国做了SPA,这中间会磨蹭多长时间完全看人品,几分钟到几小时都不是梦。
Arbitray links:消息可能被恶意窃听、篡改、丢弃,总之,你摊上事儿了。这年头,谁心里还没有一点儿小秘密?
我曾天真地以为网络都是Reliable的,是现实教会了我Point-to-Point就是P2P,而P2P是会跑路和暴雷的。在一个稍具规模的公司里,拔网络和贴胶带都是运维工程师的基本操作,不然你以为他们凭什么拿这么高的薪水?而在某些非社会主义国家的特殊日子,网络时好时坏已经是业内规则。
不要问我为啥了解P2P,这叫知识,知识懂么~
还好我是认识鲁迅的人,我知道:软件工程里,没有什么问题是不可以通过增加一个中间层来解决的。
retry+dedup:通过不断的重试+去重,我们可以把Fair-loss links转化成Reliable links。
TLS:通过某种形式的加密(比如:TLS),我们可以把Arbitrary links转化成Fair-loss links。
CAP与PACELC
还有一种经常被拎出来单独讨论网络异常现象是Network Partition(网络分区)。它特指由于交换机失败,导致整个网络被分割成多个子网络分区的情况。分区内的网络节点可以相互通信,但分区间的网络节点相互失联。
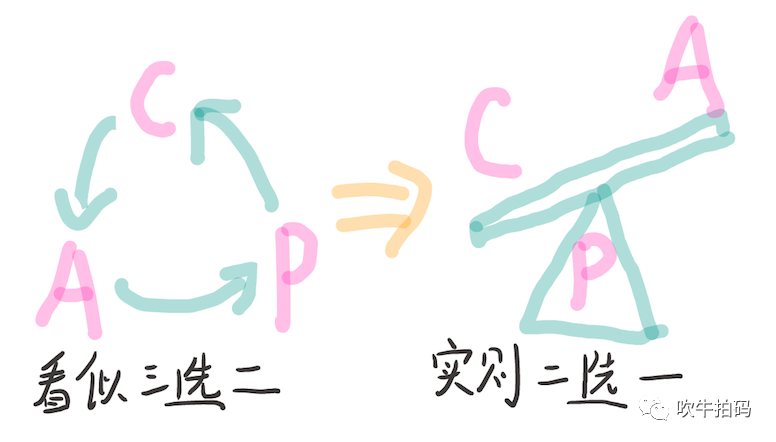
网络分区之所以被大家广为知晓,很可能是因为跟它相关的CAP的定理特别出名,尽管这个定理没啥用。CAP定理中的三个字母分别代表:C(Consistency,一致性,其实是指Linearizabilty,线性一致性),A(Availability,可用性),P(Partition Tolerance,分区容忍性)。CAP号称三选二,但在分布式系统中其实只能在一致性和可用性之间二选一,通常只用于面试或对萌新妹子吹牛,对实际系统开发指导能力有限。
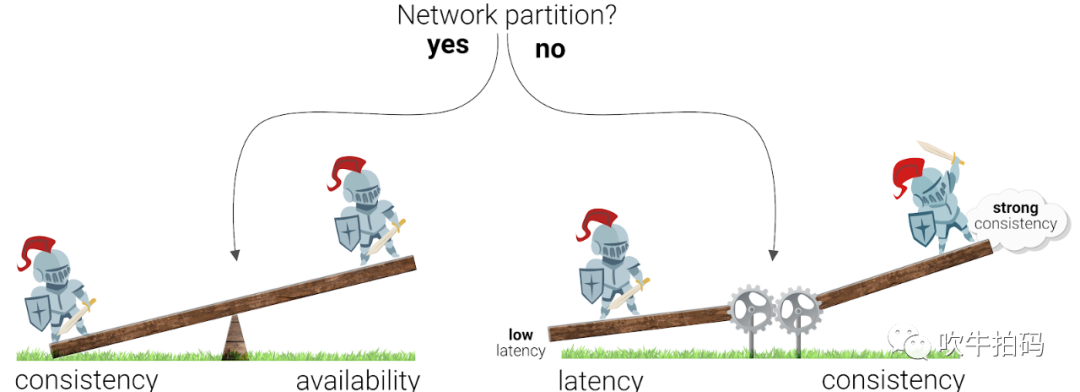
另外,还有一个PACELC理论,它是加强版的CAP定理,却因为名字起得不好,导致鲜为人知。PACELC强调它的后三个字母ELC,即Else Latency Consistency,指在没有发生网络分区的情况下,分布式系统需要处理好『延迟』和『一致性』的关系。简而言之:一个具有N个节点的分布式系统,达成一致的节点越多,则返回响应越慢。
同志们呐,给孩子起个好记的名字是多么的重要。
3 Process
失败模型
我们通常把运行中的计算机(节点)抽象为进程,进程可能发生各种奇奇怪怪的问题。除去跟代码逻辑密切相关的问题,在通用层面上进程(节点)可能出现的问题至少包括:
Crash-stop(fail-stop):进程可随时崩溃并停止响应,不再恢复,永远消失。这可能会伴随着物理硬件的损坏或丢失,比如你上洗手间的时候把手机洗了。
Omissions:进程不接受其它节点的请求或者不返回响应(注意,其它节点无法区分这两种情况)。从其它节点的角度看,就是懒政、不作为。
Crash-recovery(fail-recovery):进程可随时崩溃,但在一段时间后可以恢复并再次响应。在该模型中,经过持久化(到非易失性存储)的数据可以恢复,但在内存中的状态则可能会丢失。
Byzantine(fail-arbitrary):拜占庭将军问题,问题进程可以干任何事情,包括试图作弊和欺骗其它节点。
一个有趣的现象是,很多时候问题节点并不会(或不能)主动通知其它节点它出问题了,甚至有些节点会主动隐藏自己的行为。就像病人需要看医生一样,这时可能需要通过系统中的其它节点,感知问题节点的状态。比如通过docker或supervisor自动重启意外crash的进程,通过heartbeat或ping/pong机制探测某个节点是否工作正常。虽然不是所有的解决方案都简单直接,但更加完善和细致的监控,确实有利于我们及时发现和排查问题。
脑裂
另一个也许值得探讨的问题是:当你周围所有的人都认为你疯了的时候,你如何证明自己没有?类似的,当医生判断你已经要玩完的时候,你如何争取再抢救一下?以及,当所有其它节点都觉得某个节点已经僵死的时候,被观察的节点如何自证清白?
也许,这个进程只是打了个盹,比如发生Full GC了,结果一觉醒来就变成了千夫所指。也许,只是其它节点观察它的方式不对,比如发生网络分区了。但无论如何,嗓子哑了喊不出来,与喊的很大声但别人却听不见,这两者在别人的眼中并无本质的区别。
这种被孤立的进程(节点),客观上有效,但主观上已经被宣布社会性死亡。这对于无状态集群来说,可能伤害性不大。可以简单的切换到对等节点上,对外提供几乎一样的服务,只是集群中少了一个劳动力而已。但对于有状态存储,伤害就比较大。比如MySQL主从集群中,leader节点被宣布死亡,可能会导致集群切换leader节点。但更糟糕的情况是:万一旧的leader节点又复活了呢?现在集群中同时存在两个leader节点,听谁的?会不会脑裂?

这个问题被称为分布式共识问题,这个看似简单的问题实际上远比我们简单脑补出来的要复杂的多。真实情况是,长久以来,学术界都没能找到一种逻辑正确的算法解决这个问题。而直到Paxos算法出现近20年之后,工业界才慢慢理解了这个算法并有了相对稳定的实现。直到近些年,相对简化的Raft等算法才开始在Etcd, TiDB等分布式存储系统中应用开来。
4 Clock
时钟和计时是如此重要,即使在跟时间无关的业务中也会大量使用到,比如:
什么时候发送提醒邮件?
缓存何时过期?
日志的时间戳是多少?
某个请求是否超时了。
某个服务的9分位响应时间是多少?
在过去的5分钟内,服务的QPS是多少?
但你有没有想过,你使用的系统时间,可能是不准的?
你可能会想,这怎么可能?操作系统不是会使用NTP协议校对时间吗?但有没有一种可能,正是因为NTP对表导致时间更错乱了呢?
前面示例中,1~3描述是瞬时时间(时间点),4~6描述是持续时间(时间差)。要正确的计算它们,需要分别使用计算机中两种不太一样的时钟:墙上时钟和单调时钟。
时钟还要分两种嘛?是的,现实世界只有一种,计算机世界却有两种?我能说什么,我也很无奈啊~
墙上时钟
墙上时钟根据某个日历返回当前的日期和时间。linux使用clock_gettime(CLOCK_REALTIME),java使用System.currentTimeMillis()会返回自纪元1970年1月1日(UTC)以来的秒数和毫秒数,不含闰秒。
墙上时钟可以与NTP同步。但是,如果本地时钟远快于NTP服务器,强行重置之后会导致本地时钟跳回到之前的某个时间点。这种不稳定性,导致墙上时钟不太适当测量时间差。

单调时钟
单调时钟的名字来源于它总是单调增加,而不会出现类似于墙上时钟的回拨现象。它通常是计算机启动之后经历的纳秒数(或其它数值),因此单调时钟的绝对值没有任何意义,但特别适合测量时间差。linux使用clock_gettime(CLOCK_MONOTONIC),java使用System.nanoTime()获取单调时钟。
NTP时间同步并不会直接修改单调时钟的绝对值,但这并不代表NTP不会影响单调时钟。如果NTP检测到本地石英钟比时间服务器上的更快或更慢,NTP会调整本地时间的震动频率,以加快或减慢单调时钟步进的速度。
这年头,连时钟都不守时了
计算机中的石英钟不够精确。是的,先生,刚买的、还没用过的、一万块钱的计算机上的时钟也不精确,经常漂移(步进速度会加快或减慢)。时钟漂移主要取决于机器的温度。按google的说法,如果服务器的时钟偏移为200ppm(百万分之一)。那么,如果每30s同步一次,则可能出现的最大偏差为6ms;而如果一天同步一次,则最大偏差为17秒。

闰秒是指一分钟有59s或61s的现象。很神奇吧?想想我们每隔几年还来一次闰月,是不是觉得闰秒正常多了?然而,闰秒会使一些毫无防范的系统混乱,甚至崩溃。处理闰秒的推荐方式是,不管NTP服务器具体如何实现,在NTP服务器汇报时间时故意做些调整,目的是在一天的周期内逐步调整闰秒(称为拖尾)。
全民上云的时代,应用已经很难保证自己是运行在物理机还是虚拟机中。在虚拟机中,由于硬件时钟也是被虚拟化的,这对于需要精确计时的应用程序提出了额外的挑战。当虚拟机共享一个CPU核时,每个虚拟机会出现数十毫秒的暂停以便切换客户虚机。但从应用的角度来看,这种停顿会表现为时钟突然向前跳跃。
时钟虽然看起来简单,但仍然有不少使用上的陷阱:一天可能并不总是86400s,时钟会向前向后回拨,一个节点上的时间可能会另一个节点上的时间完全不同。跟网络和进程问题相比,时钟问题更加隐蔽,不容易被及时发现。如果石英时钟有bug,或NTP客户端配置错误,最后出现了时间偏差,对大多数功能可能影响不大。但对于一些调试依赖于精确计时的软件,可能会出现一些隐式的后果,比如丢失数据而不是突然崩溃。
因此,如果应用确实需要精确同步的时钟,最好仔细监控所有节点上的时钟偏差。如果某个节点上的时钟漂移超出上限,应将其宣告为失效,并从集群中移除。这样可能确保在出现重大损失之前及早发现并处理。
5 男人都是大猪蹄子
Network网络、Process进程、Clock时钟,本来还想给它们中的一个加加薪,结果仔细琢磨了一下,就没有一个是靠谱的。
这不禁让我想起孔子的一句名言:男人都是大猪蹄子。我孟子忍不住要补一句:孔子说得对啊,这年头,还是公众号『吹牛拍码』最靠谱啊~
6 参考文献
Designing Data-Intensive Applications 数据密集型应用系统设计
Distributed Systems 2.3: System models Martin Kleppmann的讲座
Distributed algorithms - Chapter 3 : Group Communications 法国尼斯大学的pdf讲稿
Consistent Backends and UX: Why Should You Care? 这个系列有4篇文章,这是第一篇
Why are Distributed Systems so hard? A network partition survival guide - Denise Yu 很有趣的演讲
https://deniseyu.io/art/ 我喜欢这个女生的漫画
分布式理论最新提出的PACELC理论作为CAP理论的扩展。具体补充了哪些内容?
FAILURE MODES IN DISTRIBUTED SYSTEMS
Modes of Failure (Part 1)