
摆脱FM!推荐算法一次重要迭代,用户时序模型
点击上方蓝字,关注并星标,和我一起学技术。
大家好,今天我们继续来聊推荐系统。
之前我们介绍了推荐当中应用得非常广泛的FM大家族,从FM这个模型衍生出了一系列的模型,从纯FM,到AFM、FFM、DeepFM等等一系列的FM模型,最后的终极版本是xDeepFM。这个模型非常复杂,可以说是把FM魔改到了极致,今天这篇文章先不讨论这个,等以后论文解析的时候好好介绍一下这个模型。
现在回过头来看的话,会发现FM模型的各种魔改其实是一种探索,当时还不知道未来的出路在哪里,也不知道深度学习在推荐领域能够带来什么变化。前人尝试出来FM模型效果不错,那么最简单的办法当然是在FM上各种魔改。魔改多了之后,逐渐探索出了方法论,那么就有了下一次的迭代升级。
FM的下一个迭代版本是什么呢?其实不再是单纯的某一个或者是某一种模型,而是一种思想和方法。我们之前的文章也提到过,也就是应用Embedding向量的方法,基于Embedding向量的应用,到这里有衍生出了许多个分支,有了更细维度的拆分。比如有的继续研究传统CTR的提升,有的研究模型的多任务学习,可以让模型同时优化几个指标,有的研究强化学习,想要训练出更加智能的模型等等。
今天我们还是先来聊聊最传统的CTR优化的方向,给大家介绍几个相对来说比较前沿的模型和方法。
用户时序特征
之前在介绍FM模型的时候,曾经提到过它有一个巨大的问题,就是模型的输入的维度是固定的,也就是说我们生成的特征也是固定的。看起来这个没什么问题,因为无论机器学习还是深度学习,它们的模型基本上参数空间都是固定的,至少大小是固定的。
问题不在于模型,而在于应用的时候,我们还是以电商场景举例,大家都知道在电商场景当中,有的用户活跃,行为多,有的用户相对不那么活跃,比较冷淡,偶尔来买点东西。对于这两种不同的用户来说,显然前者的行为更多,传递的信息也就更多。这个也很好理解,用户行为越多,喜好越明显,相反如果用户缺什么来买什么就很难猜测喜好。
但由于模型的输入是固定的,过去买过100件商品和没买过商品的用户,他们的特征加工完了之后是同样的维度,显然这会导致前者丢失大量的信息。另外一个问题是FM模型本身没有时序处理的部分,它肯定就学不到时序的一些信息。比如张三一周之前想买袜子,于是点击了很多袜子,前两天又对一款游戏感兴趣,点击了几次游戏。可能总体上来说游戏点击的次数不如袜子多,但显然由于游戏点击的行为发生地距离现在更近,他之后会点击游戏的概率要大于袜子。如果只是单纯的制作一个用户过去最经常点击的类别,那么对于张三来说这个类别显然是袜子,但是这个信息肯定是不准确的。
早年的算法工程师们也不傻,也都知道要把用户行为的特征着重研究,应用进模型。但这里有两个问题,第一个问题是用户的行为数量是不同的,有的用户行为多有的行为少,但模型的参数往往是固定的。第二个问题是FM模型没有时序的处理逻辑,它不能处理时间上的先后关系以及这个关系带来的影响。
由于这两个问题的存在,导致了我们仅仅制作特征是不够的,包含的信息往往比较片面,我们还需要模型层面的改进。
怎么改进呢,其实很简单,不是说了FM本身没有时序处理的部分,导致它学不到先后逻辑上的关联么。那什么领域的模型主要研究时序?NLP,因为语句是有先后顺序的,无论是文本分析还是机器翻译都需要考虑上下文,所以NLP是最早使用RNN、LSTM等时序模型的领域。
NLP先行一步,推荐也紧跟而上,尝试着将NLP的一些技术和思想应用到推荐模型当中来,由此诞生了许许多多的模型。在这里承志着重挑选了这两年效果不俗得到广泛认可的模型给大家简单介绍一下。
DIN
关于DIN模型的论文解析上周已经写过了,大家想看的话可以点击下方的传送门进行访问。
整体上来说DIN模型的原理并不复杂,相反还很简单。它的本身其实就是一个Embedding + MLP的结构,只不过在其中加上了DIN模块。也就是下图红框当中的部分。
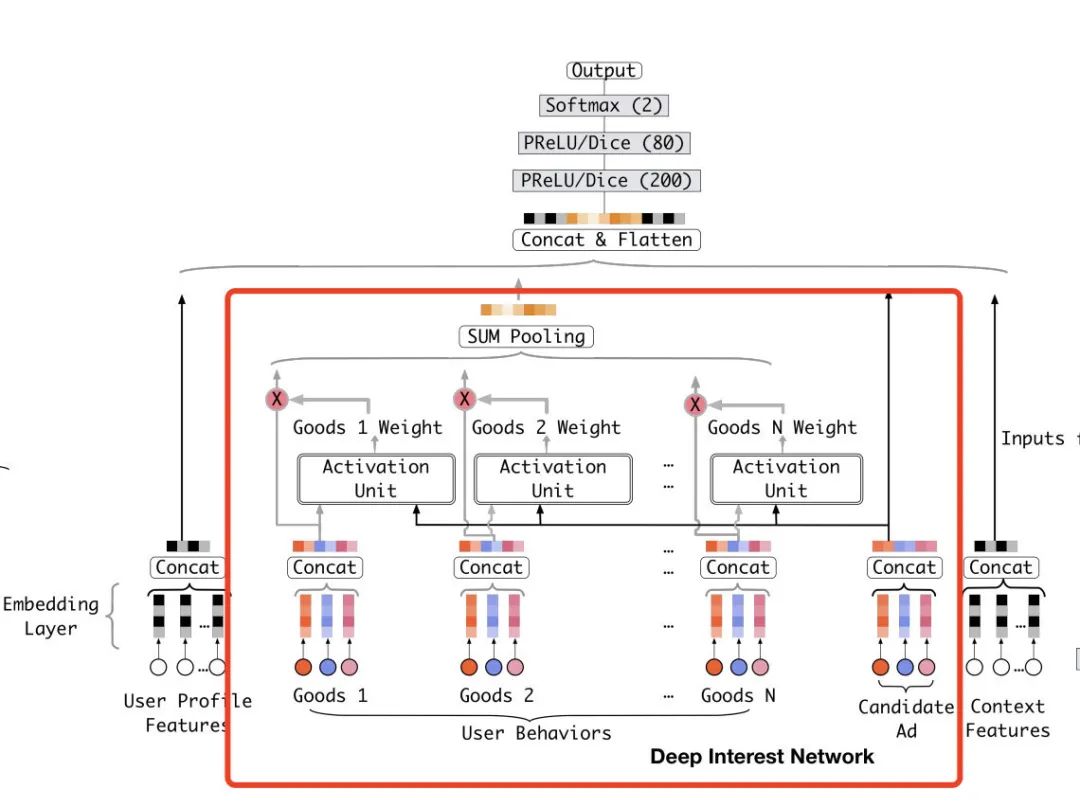
红框当中的Goods1到Goods N表示的用户历史的行为数据,也就是用户和哪些商品有过交互。对于用户交互过的每一个商品,我们都通过Activation Unit计算它和当前将要预测的候选商品的权重。这个权重也可以理解成相似度,也就是用户交互的商品和候选的商品的相似度。然后我们把序列里所有商品都通过这个方式得到权重,并且对它们的Embedding表示通过sum pooling进行加权求和,最后我们把这么一个加权求和得到的向量输入DNN。
这里的精髓有两个,一个是sum pooling可以解决有的用户行为多有的行为少的问题,因为sum到一起了之后长度就固定了。第二个是这里的权重要经过一次softmax运算,这样可以保证所有权重之和为1。
Transformer
第二个要介绍的模型叫做transformer,如果说DIN只是借鉴了NLP当中时序模型的一些处理逻辑和思想的话,那么transformer几乎就是实打实的直接搬运了。
transformer原本是NLP领域的模型,尤其在机器翻译上获得了非常好的效果。它本质上是一个encoder和decoder的结合,也就是一个编码器和解码器的结合。也就是说通过编码和解码的过程,让模型学到两个序列之间的映射或者是内在关系。
它的整个模型结构图如下所示:
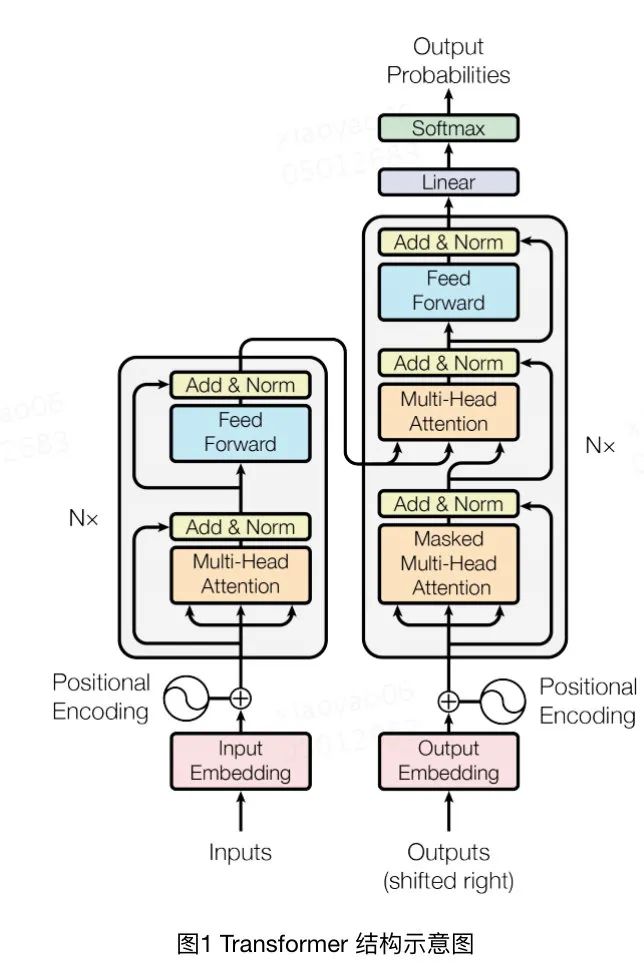
上图当中左边一列是编码器,也就是将input通过Multi-Head Attention、Add & Norm等操作最后输入到解码器decoder当中。解码器会对output做同样的编码操作,然后再学习两个编码之间的交叉信息。至于Multi-Head Attention、Add & Norm这些子模块当中究竟进行了什么样的操作,这里就不多做赘述了,有很多复杂的实现细节,大家感兴趣的话可以去阅读论文原文。
正是因为它开创性地对输入和输出都做了编码和解码的操作,使得它在机器翻译的领域大放异彩,获得了非常好的效果。对于推荐领域来说,它不需要预测一个序列,只需要预测当前item的CTR。所以它主要被用来处理用户行为序列这个特征,利用transformer结构对用户行为序列当中的item以及目标item进行encoding和decoding运算,得到一个定长的向量。
这里我们可以看下transformer在美团推荐场景下的应用,我找来了博客里的图。
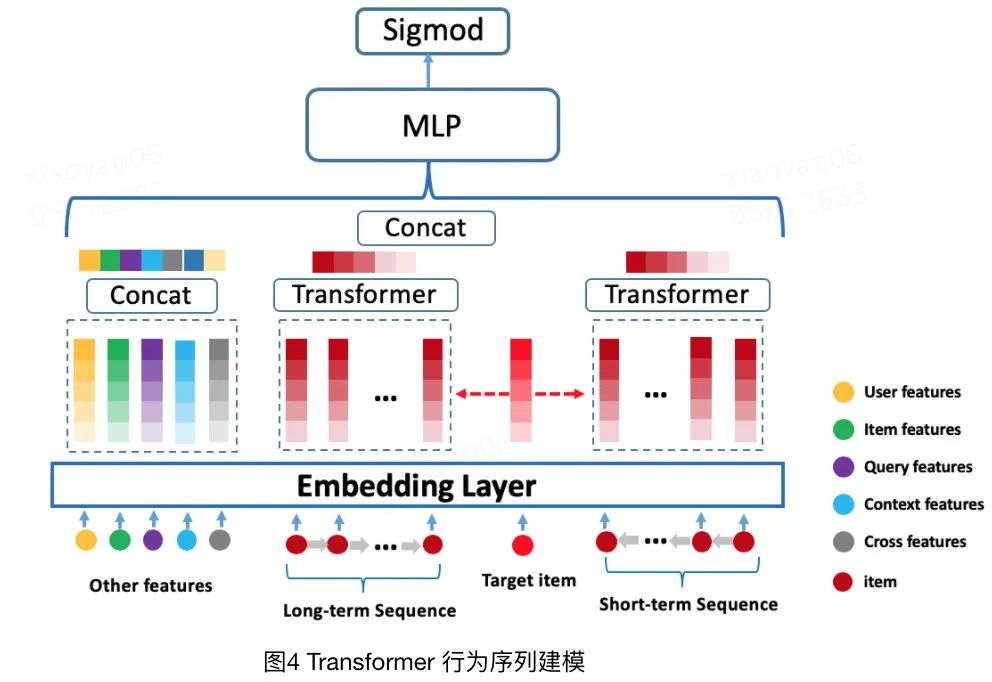
从图中可以看得出来,它的结构和DIN没有什么本质上的区别,无非是把用户行为序列按照时间长短分成了两个部分。然后多个Embedding归并的方法不再是sum pooling而是transformer而已。
总结
在推荐场景,尤其是电商场景下,用户的历史行为数据至关重要,它能直接反应用户的兴趣以及偏好。尤其是当用户行为序列很长的时候,还能反应出用户历史行为以及消费能力的变化,使得模型的预测能够更加精准。淘宝的首页推荐能做得这么好,总能推出很吸引人耳目一新的商品,和用户行为序列特征的深度挖掘和使用脱不开干系。
DIN和BST(Transformer)这两篇论文分别发表于18和19年,它的作者都是阿里巴巴,应该算是推荐领域比较前沿尖端的论文了。非常推荐给想要从事推荐算法领域的小伙伴。
好了,今天的文章就到这里,感谢阅读,喜欢的话不要忘了三连。