
FM模型的原理(下) | 推荐系统
七月在线实验室
共 8978字,需浏览 18分钟
· 2021-04-12

文 | 七月在线
编 | 小七
解析:
如何优化FM的计算效率
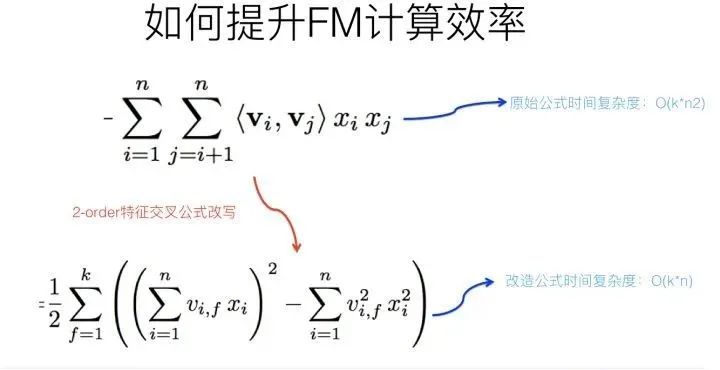
再说回来,FM如今被广泛采用并成功替代LR模型的一个关键所在是:它可以通过数学公式改写,把表面貌似是的复杂度降低到
,其中n是特征数量,k是特征的embedding size,这样就将FM模型改成了和LR类似和特征数量n成线性规模的时间复杂度了,这点非常好。那么,如何改写原始的FM数学公式,让其复杂度降下来呢?因为原始论文在推导的时候没有给出详细说明,我相信不少人看完估计有点懵,所以这里简单解释下推导过程,数学公式帕金森病患者可以直接跳过下面内容往后看,这并不影响你理解本文的主旨。
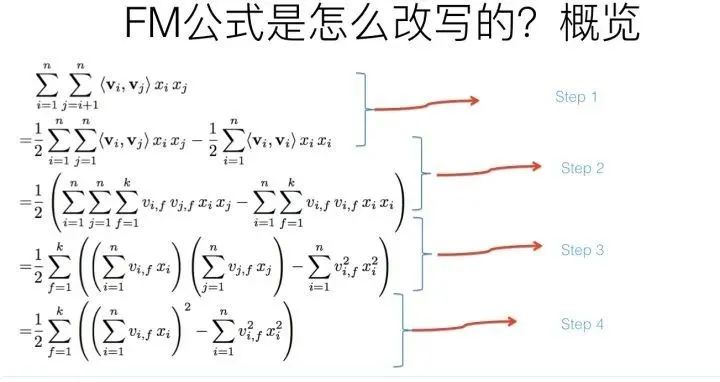
上图展示了整个推导过程,我相信如果数学基础不太扎实的同学看着会有点头疼,转换包括四个步骤,下面分步骤解释下。
第一个改写步骤及为何这么改写参考上图,比较直观,不解释了;
第二步转换更简单,更不用解释了。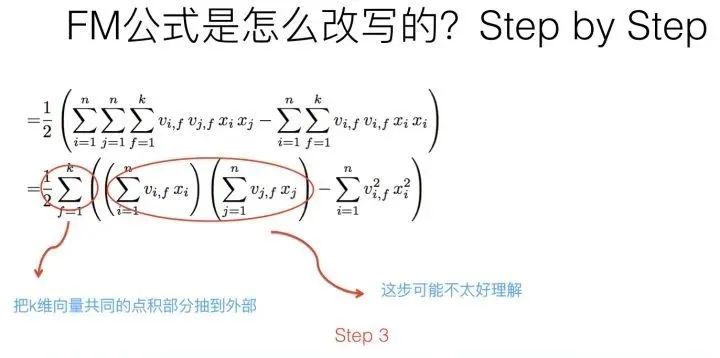
第三步转换不是太直观,可能需要简单推导一下,很多人可能会卡在这一步,所以这里解释解释。
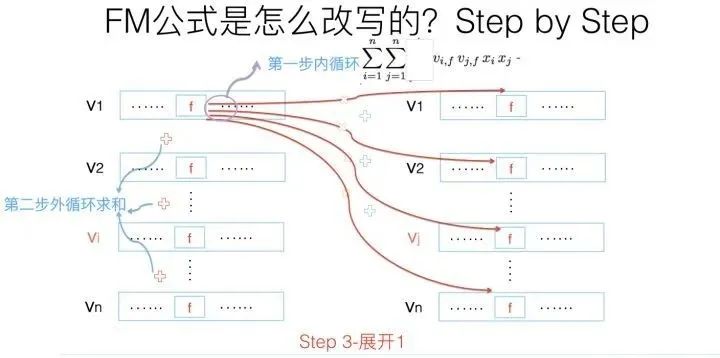
其实吧,如果把k维特征向量内积求和公式抽到最外边后,公式就转成了上图这个公式了(不考虑最外边k维求和过程的情况下)。它有两层循环,内循环其实就是指定某个特征的第f位(这个f是由最外层那个k指定的)后,和其它任意特征对应向量的第f位值相乘求和;而外循环则是遍历每个的第f位做循环求和。这样就完成了指定某个特征位f后的特征组合计算过程。最外层的k维循环则依此轮循第f位,于是就算完了步骤三的特征组合。
对上一页公式图片展示过程用公式方式,再一次改写(参考上图),其实就是两次提取公共因子而已,这下应该明白了吧?要是还不明白,那您的诊断结果是数学公式帕金森晚期,跟我一个毛病,咱俩病友同病相怜,我也没辙了。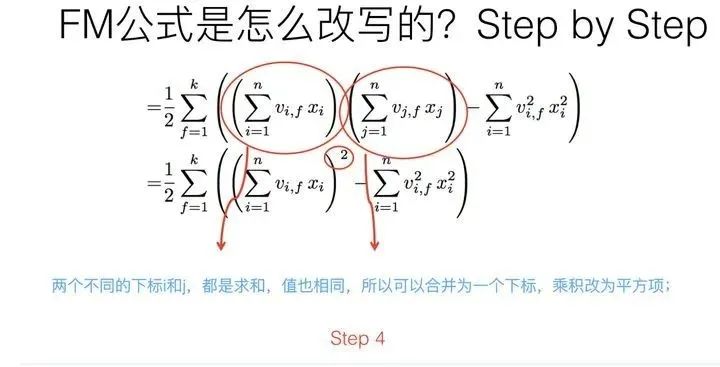
第四步公式变换,意思参考上图,这步也很直白,不解释。于是,通过上述四步的公式改写,可以看出在实现FM模型时,时间复杂度就降低到了
这里需要强调下改写之后的FM公式的第一个平方项,怎么理解这个平方项的含义呢?这里其实蕴含了后面要讲的使用FM模型统一多路召回的基本思想,所以这里特殊提示一下。
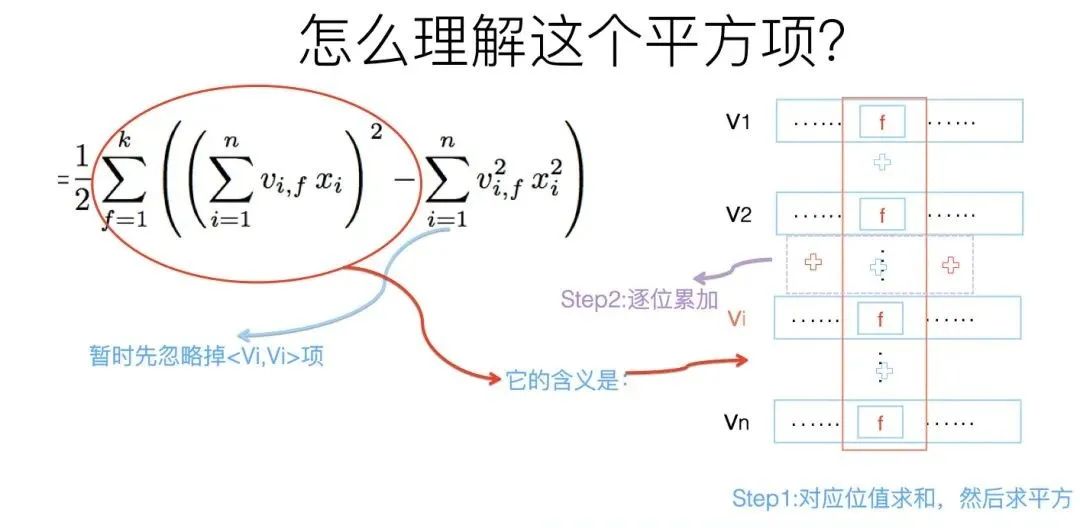
参考上图,你体会下这个计算过程。它其实等价于什么?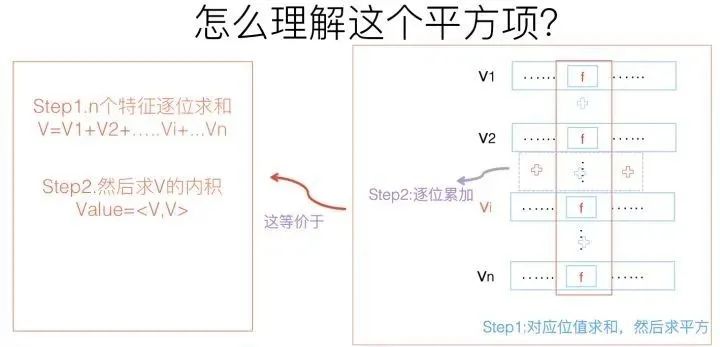
这个平方项,它等价于将FM的所有特征项的embedding向量累加,之后求内积。我再问下之前问过的问题:“我们怎样利用FM模型做统一的召回?”这个平方项的含义对你有启发吗?你可以仔细想想它们之间的关联。
如何利用FM模型做统一的召回模型
上文书提到过,目前工业界推荐系统在召回阶段,大多数采用了多路召回策略,比如典型的召回路有:基于用户兴趣标签的召回;基于协同过滤的召回;基于热点的召回;基于地域的召回;基于Topic的召回;基于命名实体的召回等等,除此外还有很多其它类型的召回路。
现在我们来探讨下第一个问题:在召回阶段,能否用一个统一的模型把多路召回招安?就是说改造成利用单个模型,单路召回的模式?具体到这篇文章,就是说能否利用FM模型来把多路召回统一起来?在回答上述问题之前,我估计你会提出疑问:目前大家用多路召回用的好好的,为啥要多此一举,用一个模型把多路召回统一起来呢?这个问题非常好,我们确实应该先看这么做的必要性。
统一召回和多路召回优缺点比较
我们先来说明下统一召回和多路召回各自的优缺点,我觉得使用统一召回模式,相对多路召回有如下优点:
首先,采用多路召回,每一路召回因为采取的策略或者模型不同,所以各自的召回模型得分不可比较,比如利用协同过滤召回找到的候选Item得分,与基于兴趣标签这一路召回找到的候选Item得分,完全是不可比较的。这也是为何要用第二阶段Ranking来将分数统一的原因。而如果采取统一的召回模型,比如FM模型,那么不论候选项Item来自于哪里,它们在召回阶段的得分是完全可比的。
其次,貌似在目前“召回+Ranking”两阶段推荐模型下,多路召回分数不可比这个问题不是特别大,因为我们可以依靠Ranking阶段来让它们可比即可。但是其实多路召回分数不可比会直接引发一个问题:对于每一路召回,我们应该返回多少个Item是合适的呢?如果在多路召回模式下,这个问题就很难解决。既然分数不可比,那么每一路召回多少候选项K就成为了超参,需要不断调整这个参数上线做AB测试,才能找到合适的数值。而如果召回路数特别多,于是每一路召回带有一个超参K,就是这一路召回多少条候选项,这样的超参组合空间是非常大的。所以到底哪一组超参是最优的,就很难定。其实现实情况中,很多时候这个超参都是拍脑袋上线测试,找到最优的超参组合概率是很低的。
而如果假设我们统一用FM模型来做召回,其实就不存在上面这个问题。这样,我们可以在召回阶段做到更好的个性化,比如有的用户喜欢看热门的内容,那么热门内容在召回阶段返回的比例就高,而其它内容返回比例就低。所以,可以认为各路召回的这组超参数就完全依靠FM模型调整成个性化的了,很明显这是使用单路单模型做召回的一个特别明显的好处。
再次,对于工业界大型的推荐系统来说,有极大的可能做召回的技术人员和做Ranking的技术人员是两拨人。这里隐含着一个潜在可能会发生的问题,比如召回阶段新增了一路召回,但是做Ranking的哥们不知道这个事情,在Ranking的时候没有把能体现新增召回路特性的特征加到Ranking阶段的特征中。这样体现出来的效果是:新增召回路看上去没什么用,因为即使你找回来了,而且用户真的可能点击,但是在排序阶段死活排不上去。也就是说,在召回和排序之间可能存在信息鸿沟的问题,因为目前召回和排序两者的表达模式差异很大,排序阶段以特征为表达方式,召回则以“路/策略/具体模型”为表达方式,两者之间差异很大,是比较容易产生上述现象的。
但是如果我们采用FM模型来做召回的话,新增一路召回就转化为新增特征的问题,而这一点和Ranking阶段在表现形式上是相同的,对于召回和排序两个阶段来说,两者都转化成了新增特征问题,所以两个阶段的改进语言体系统一,就不太容易出现上述现象。
上面三点,是我能想到的采用统一召回模型,相对多路召回的几个好处。但是是不是多路召回一定不如统一召回呢?其实也不是,很明显多路召回这种策略,上线一个新召回方式比较灵活,对线上的召回系统影响很小,因为不同路召回之间没有耦合关系。但是如果采用统一召回,当想新增一种召回方式的时候,表现为新增一种或者几种特征,可能需要完全重新训练一个新的FM模型,整个召回系统重新部署上线,灵活性比多路召回要差。
上面讲的是必要性,讲完了必要性,我们下面先探讨如何用FM模型做召回,然后再讨论如何把多路召回改造成单路召回,这其实是两个不同的问题。
如何用FM模型做召回模型
如果要做一个实用化的统一召回模型,要考虑的因素有很多,比如Context上下文特征怎么处理,实时反馈特征怎么加入等。为了能够更清楚地说明,我们先从极简模型说起,然后逐步加入必须应该考虑的元素,最后形成一个实用化的统一召回模型。不论是简化版本FM召回模型,还是复杂版本,首先都需要做如下两件事情:
第一,离线训练。这个过程跟在排序阶段采用FM模型的离线训练过程是一样的,比如可以使用线上收集到的用户点击数据来作为训练数据,线下训练一个完整的FM模型。在召回阶段,我们想要的其实是:每个特征和这个特征对应的训练好的embedding向量。这个可以存好待用。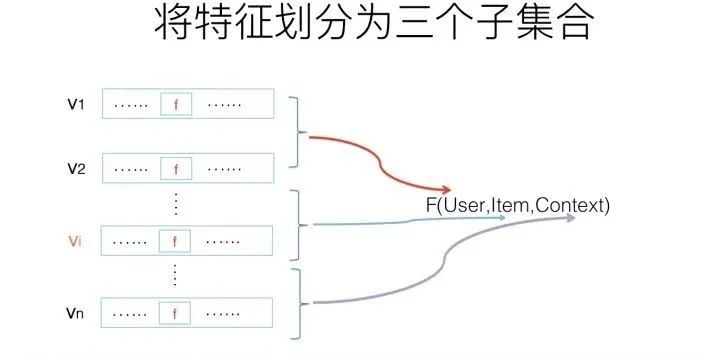
第二,如果将推荐系统做个很高层级的抽象的话,可以表达成学习如下形式的映射函数:

意思是,我们利用用户(User)相关的特征,物品(Item)相关的特征,以及上下文特征(Context,比如何时何地用的什么牌子手机登陆等等)学习一个映射函数F。学好这个函数后,当以后新碰到一个Item,我们把用户特征,物品特征以及用户碰到这个物品时的上下文特征输入F函数,F函数会告诉我们用户是否对这个物品感兴趣。如果他感兴趣,就可以把这个Item作为推荐结果推送给用户。
说了这么多,第二个我们需要做的事情是:把特征划分为三个子集合,用户相关特征集合,物品相关特征集合以及上下文相关的特征集合。而用户历史行为类特征,比如用户过去点击物品的特征,可以当作描述用户兴趣的特征,放入用户相关特征集合内。至于为何要这么划分,后面会讲。做完上述两项基础工作,我们可以试着用FM模型来做召回了。
极简版FM召回模型
我们先来构建一个极简的FM召回模型,首先,我们先不考虑上下文特征,晚点再说。
第一步,对于某个用户,我们可以把属于这个用户子集合的特征,查询离线训练好的FM模型对应的特征embedding向量,然后将n个用户子集合的特征embedding向量累加,形成用户兴趣向量U,这个向量维度和每个特征的维度是相同的。类似的,我们也可以把每个物品,其对应的物品子集合的特征,查询离线训练好的FM模型对应的特征embedding向量,然后将m个物品子集合的特征embedding向量累加,形成物品向量I,这个向量维度和每个特征的维度也是是相同的。对于极简版FM召回模型来说,用户兴趣向量U可以离线算好,然后更新线上的对应内容;物品兴趣向量I可以类似离线计算或者近在线计算,问题都不大。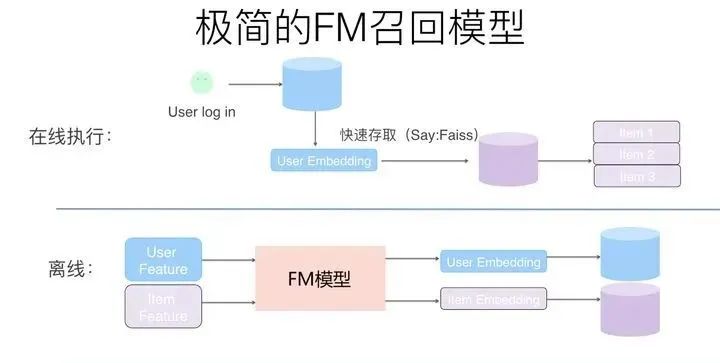
第二步,对于每个用户以及每个物品,我们可以利用步骤一中的方法,将每个用户的兴趣向量离线算好,存入在线数据库中比如Redis(用户ID及其对应的embedding),把物品的向量逐一离线算好,存入Faiss(Facebook开源的embedding高效匹配库)数据库中。
当用户登陆或者刷新页面时,可以根据用户ID取出其对应的兴趣向量embedding,然后和Faiss中存储的物料embedding做内积计算,按照得分由高到低返回得分Top K的物料作为召回结果。提交给第二阶段的排序模型进行进一步的排序。这里Faiss的查询速度至关重要,至于这点,后面我们会单独说明。
这样就完成了一个极简版本FM召回模型。但是这个版本的FM召回模型存在两个问题。
问题一:首先我们需要问自己,这种累加用户embedding特征向量以及累加物品embedding特征向量,之后做向量内积。这种算法符合FM模型的原则吗?和常规的FM模型是否等价?我们来分析一下。这种做法其实是在做用户特征集合U和物品特征集合I之间两两特征组合,是符合FM的特征组合原则的,考虑下列公式是否等价就可以明白了:
(公式1)
(公式2)
其实两者是等价的,建议您可以推导一下(这其实不就是上面在介绍FM公式改写的第三步转换吗?当然,跟完全版本的FM比,我们没有考虑U和I特征集合内部任意两个特征的组合,等会会说这个问题)。
也可以这么思考问题:在上文我们说过,FM为了提升计算效率,对公式进行了改写,改写后的高效计算公式的第一个平方项其实等价于:把所有特征embedding向量逐位累加成一个求和向量V,然后自己和自己做个内积操作< V,V>。这样等价于根据FM的原则计算了任意两个特征的二阶特征组合了。而上面描述的方法,和标准的FM的做法其实是一样的,区别无非是将特征集合划分为两个子集合U和I,分别代表用户相关特征及物品相关特征。而上述做法其实等价于在用户特征和物品特征之间做两两特征组合,只是少了U内部之间特征,及I内部特征之间的特征组合而已。一般而言,其实我们不需要做U内部特征之间以及I内部特征之间的特征组合,对最终效果影响很小。于是,沿着这个思考路径,我们也可以推导出上述做法基本和FM标准计算过程是等价的。
第二个问题是:这个版本FM是个简化版本模型,因为它没考虑场景上下文特征,那么如果再将上下文特征引入,此时应该怎么做呢?
加入场景上下文特征
上面叙述了如何根据FM模型做一个极简版本的召回模型,之所以说极简,因为我们上面说过,抽象的推荐系统除了用户特征及物品特征外,还有一类重要特征,就是用户发生行为的场景上下文特征(比如什么时间在什么地方用的什么设备在刷新),而上面版本的召回模型并没有考虑这一块。
之所以把上下文特征单独拎出来,是因为它有自己的特点,有些上下文特征是近乎实时变化的,比如刷新微博的时间,再比如对于美团嘀嘀这种对地理位置特别敏感的应用,用户所处的地点可能随时也在变化,而这种变化在召回阶段就需要体现出来。所以,上下文特征是不太可能像用户特征离线算好存起来直接使用的,而是用户在每一次刷新可能都需要重新捕获当前的特征值。动态性强是它的特点。
而考虑进来上下文特征,如果我们希望构造和标准的FM等价的召回模型,就需要多考虑两个问题:
问题一:既然部分上下文特征可能是实时变化的,无法离线算好,那么怎么融入上文所述的召回计算框架里?
问题二:我们需要考虑上下文特征C和用户特征U之间的特征组合,也需要考虑C和物品特征I之间的特征组合。上下文特征有时是非常强的特征。那么,如何做能够将这两对特征组合考虑进来呢?
我们可以这么做: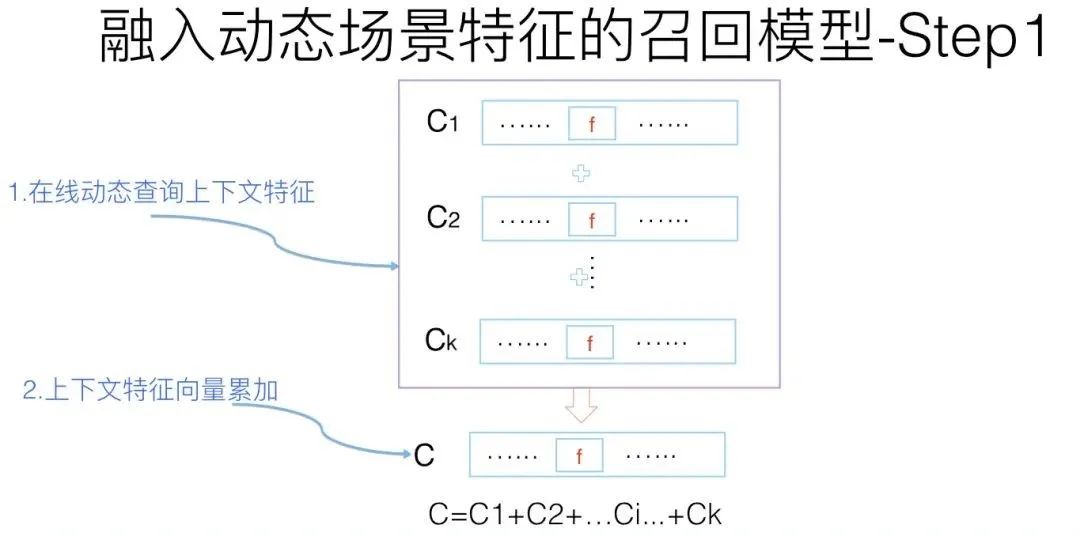
首先,由于上下文特征的动态性,所以给定用户UID后,可以在线查询某个上下文特征对应的embedding向量,然后所有上下文向量求和得到综合的上下文向量C。这个过程其实和U及I的累加过程是一样的,区别无非是上下文特征需要在线实时计算。而一般而言,场景上下文特征数都不多,所以在线计算,速度方面应可接受。
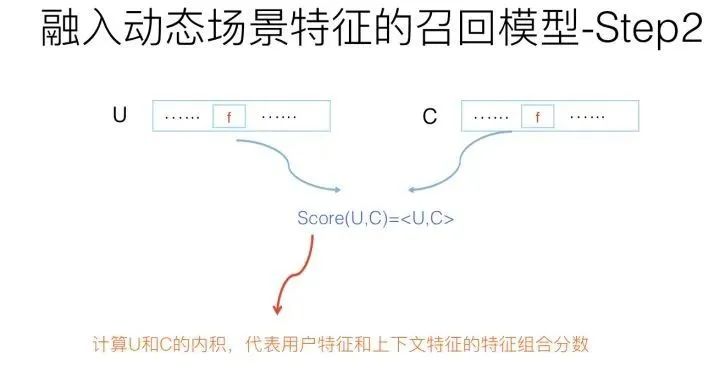
然后,将在线算好的上下文向量C和这个用户的事先算好存起来的用户兴趣向量U进行内积计算Score=< U,C>。这个数值代表用户特征和上下文特征的二阶特征组合得分,算好备用。至于为何这个得分能够代表FM中的两者(U和C)的特征组合,其实道理和上面讲的U和I做特征组合道理是一样的。
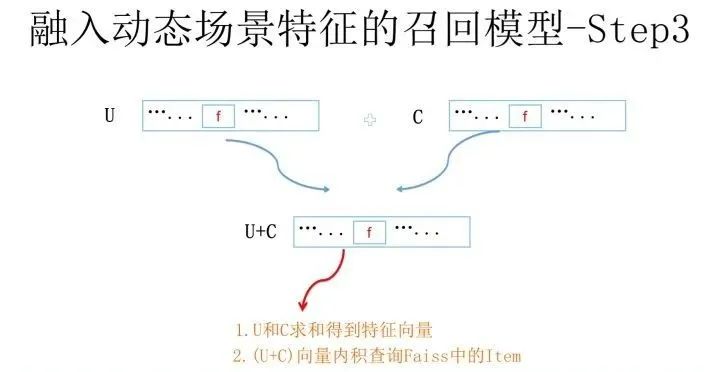
再然后,将U和C向量累加求和,利用(U+C)去Faiss通过内积方式取出Top K物品,这个过程和极简版是一样的,无非查询向量由U换成了(U+C)。通过这种方式取出的物品同时考虑到了用户和物品的特征组合< U,I>,以及上下文和物品的特征组合< C,I>。道理和之前讲的内容是类似的。
假设返回的Top K物品都带有内积的得分Score1,再考虑上一步< U,C>的得分Score,将两者相加对物品重排序(< U,C>因为跟物品无关,所以其实不影响物品排序,但是会影响最终得分,FM最外边的Sigmoid输出可能会因为加入这个得分而发生变化),就得到了最终结果,而这个最终结果考虑了U/I/C两两之间的特征组合。于是我们通过这种手段,构造出了一个完整的FM召回模型。这个召回模型通过构造user embedding,Context embedding和Item embedding,以及充分利用类似Faiss这种高效embedding计算框架,就构造了高效执行的和FM计算等价的召回系统。
如何将多路召回融入FM召回模型
上文所述是如何利用FM模型来做召回,下面我们讨论下如何将多路召回统一到FM召回模型里来。我们以目前不同类型推荐系统中共性的一些召回策略来说明这个问题,以信息流推荐为例子,传统的多路召回阶段通常包含以下策略:协同过滤,兴趣分类,兴趣标签,兴趣Topic,兴趣实体,热门物品,相同地域等。这些不同角度的召回策略都是较为常见的。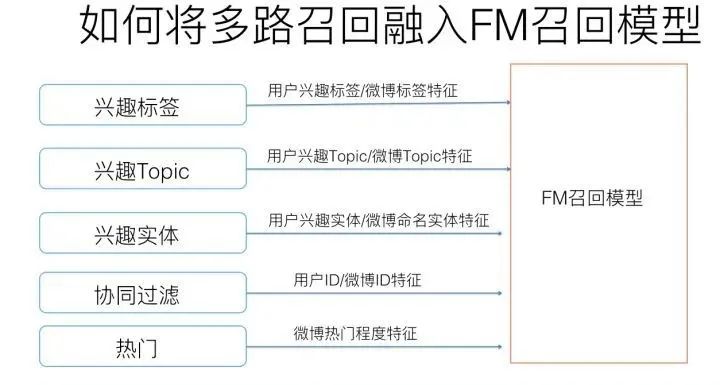
我们再将上述不同的召回路分为两大类,可以把协同过滤作为一类,其它的作为一类,协同过滤相对复杂,我们先说下其它类别。
对于比如兴趣分类,兴趣标签,热门,地域等召回策略,要把这些召回渠道统一到FM模型相对直观,只需要在训练FM模型的时候,针对每一路的特性,在用户特征端和物品特征端新增对应特征即可。比如对于地域策略,我们可以把物品所属地域(比如微博所提到的地域)和用户的感兴趣地域都作为特征加入FM模型即可。兴趣标签,Topic,兴趣实体等都是类似的。所以大多数情况下,在多路召回模式下你加入新的一路召回,在FM统一召回策略下,对应地转化成了新增特征的方式。
然后我们再说协同过滤这路召回。其实本质上也是将一路召回转化为新加特征的模式。我们上文在介绍FM模型和MF模型关系的时候提到过:本质上MF模型这种典型的协同过滤策略,是FM模型的一个特例,可以看作在FM模型里只有User ID和Item ID这两类(Fields)特征的情形。意思是说,如果我们将user ID和Item ID作为特征放入FM模型中进行训练,那么FM模型本身就是包含了协同过滤的思想的。当然,对于超大规模的网站,用户以亿计,物品可能也在千万级别,如果直接把ID引入特征可能会面临一些工程效率问题以及数据稀疏的问题。对于这个问题,我们可以采取类似在排序阶段引入ID时的ID 哈希等降维技巧来进行解决。
所以综合来看,在多路召回下的每一路召回策略,绝大多数情况下,可以在FM召回模型模式中转化为新增特征的方式。
在具体实施的时候,可以沿着这个路径逐步替换线上的多路召回:先用FM模型替换一路召回,线上替换掉;再新加入某路特征,这样上线,就替换掉了两路召回;如此往复逐渐把每一路召回统一到一个模型里。这是比较稳的一种替换方案。当然如果你是个猛人,直接用完整的FM召回模型一步替换掉线上的各路召回,也,未尝不可。只要小流量AB测试做好也没啥。
FM模型能否将召回和排序阶段一体化
前文有述,之所以目前常见的工业推荐系统会分为召回排序两个阶段,是因为这两个阶段各司其职,职责分明。召回主要考虑泛化性并把候选物品集合数量降下来;排序则主要负责根据用户特征/物品特征/上下文特征对物品进行精准排名。
那么,我们现在可以来审视下本文开头提出的第二个问题了:FM模型能否将常见的两阶段模型一体化?即是否能将实用化的推荐系统通过FM召回模型简化为单阶段模型?意思是推荐系统是否能够只保留FM召回这个模块,扔掉后续的排序阶段,FM召回按照得分排序直接作为推荐结果返回。我们可以这么做吗?
这取决于FM召回模型是否能够一并把原先两阶段模型的两个职责都能承担下来。这句话的意思是说,FM召回模型如果直接输出推荐结果,那么它的速度是否足够快?另外,它的精准程度是否可以跟两阶段模型相媲美?不会因为少了第二阶段的专门排序环节,而导致推荐效果变差?如果上面两个问题的答案都是肯定的,那么很明显FM模型就能够将现有的两阶段推荐过程一体化。
我们分头来分析这个问题的答案:准确性和速度。先从推荐精准度来说明,因为如果精准度没有办法维持,那么速度再快也没什么意义。
所以现在的第一个子问题是:FM召回模型推荐结果的质量,是否能够和召回+排序两阶段模式接近?我们假设一个是FM统一召回模型直接输出排序结果;而对比模型是目前常见的多路召回+FM模型排序的配置。从上文分析可以看出,尽管FM召回模型为了速度够快,做了一些模型的变形,但是如果对比的两阶段模型中的排序阶段也采取FM模型的话,我们很容易推理得到如下结论:如果FM召回模型采用的特征和两阶段模型的FM排序模型采用相同的特征,那么两者的推荐效果是等价的。这意味着:只要目前的多路召回都能通过转化为特征的方式加入FM召回模型,而且FM排序阶段采用的特征在FM召回模型都采用。那么两者推荐效果是类似的。这意味着,从理论上说,是可以把两阶段模型简化为一阶段模型的。
既然推理的结论是推荐效果可以保证,那么我们再来看第二个问题:只用FM召回模型做推荐,速度是否足够快?
我们假设召回阶段FM模型对User embedding和Item embedding的匹配过程采用Facebook的Faiss系统,其速度快慢与两个因素有关系:
物品库中存储的Item数量多少,Item数量越多越慢;
embedding大小,embedding size越大,速度越慢;
微博机器学习团队18年将Faiss改造成了分布式版本,并在业务易用性方面增加了些新功能,之前我们测试的查询效率是:假设物品库中存储100万条微博embedding数据,而embedding size=300的时候,TPS在600左右,平均每次查询小于13毫秒。而当库中微博数量增长到200万条,embedding size=300的时候,TPS在400左右,平均查询时间小于20毫秒。这意味着如果是百万量级的物品库,embedding size在百级别,一般而言,通过Faiss做embedding召回速度是足够实用化的。如果物品库大至千万量级,理论上可以通过增加Faiss的并行性,以及减少embedding size来获得可以接受的召回速度。
当然,上面测试的是纯粹的Faiss查询速度,而事实上,我们需要在合并用户特征embedding的时候,查询用户特征对应的embedding数据,而这块问题也不太大,因为绝大多数用户特征是静态的,可以线下合并进入用户embedding,Context特征和实时特征需要线上在线查询对应的embedding,而这些特征数量占比不算太大,所以速度应该不会被拖得太慢。
综上所述,FM召回模型从理论分析角度,其无论在实用速度方面,还是推荐效果方面,应该能够承载目前“多路召回+FM排序”两阶段推荐模式的速度及效果两方面功能,所以推论它是可以将推荐系统改造成单模型单阶段模式的。当然,上面都是分析结果,并非实测,所以不能确定实际应用起来也能达到上述理论分析的效果。
总结
最后我简单总结一下,目前看貌似利用FM模型可以做下面两个事情:
首先,我们可以利用FM模型将传统的多路召回策略,改为单模型单召回的策略,传统的新增一路召回,可以转换为给FM召回模型新增特征的方式;
其次,理论上,我们貌似可以用一个FM召回模型,来做掉传统的“多路召回+排序”的两项工作,可行的原因上文有分析。
精品好课推荐
评论