
我们为什么要分库分表?
Hollis
共 4360字,需浏览 9分钟
· 2021-04-12
在文章开头先抛几个问题:
(1)什么时候才需要分库分表呢?我们的评判标准是什么?
(2)一张表存储了多少数据的时候,才需要考虑分库分表?
(3)数据增长速度很快,每天产生多少数据,才需要考虑做分库分表?
这些问题你都搞清楚了吗?相信看完这篇文章会有答案。
为什么要分库分表?
首先回答一下为什么要分库分表,答案很简单:数据库出现性能瓶颈。用大白话来说就是数据库快扛不住了。
数据库出现性能瓶颈,对外表现有几个方面:
大量请求阻塞 在高并发场景下,大量请求都需要操作数据库,导致连接数不够了,请求处于阻塞状态。 SQL 操作变慢 如果数据库中存在一张上亿数据量的表,一条 SQL 没有命中索引会全表扫描,这个查询耗时会非常久。 存储出现问题 业务量剧增,单库数据量越来越大,给存储造成巨大压力。
数据库相关优化方案
SQL 调优
slow_query_log=on
long_query_time=1
slow_query_log_file=/path/to/log
select id, age, gender from user where name = 'AAA';
表结构优化
架构优化
硬件优化
分库分表详解
单应用单数据库
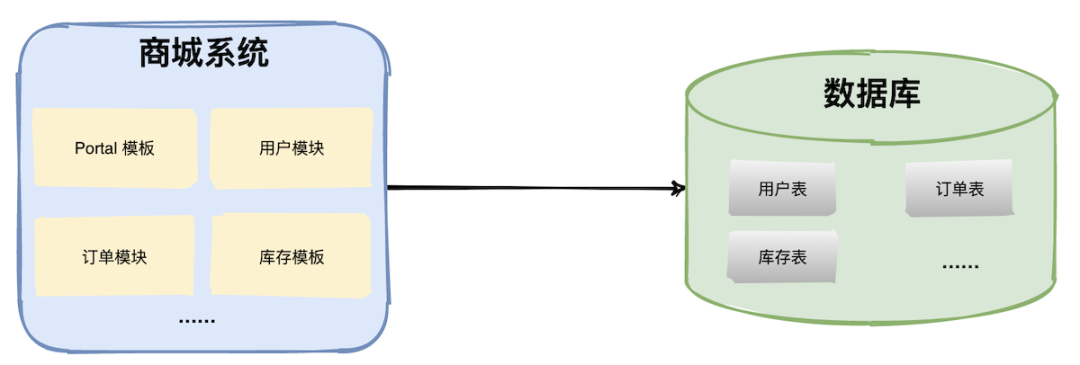
多应用单数据库
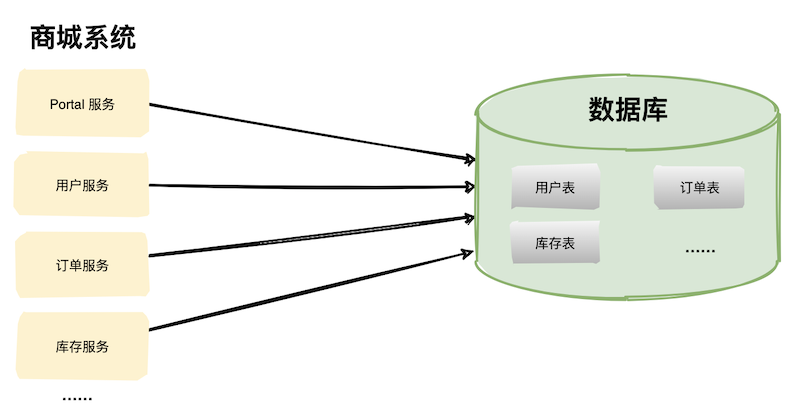
多应用多数据库
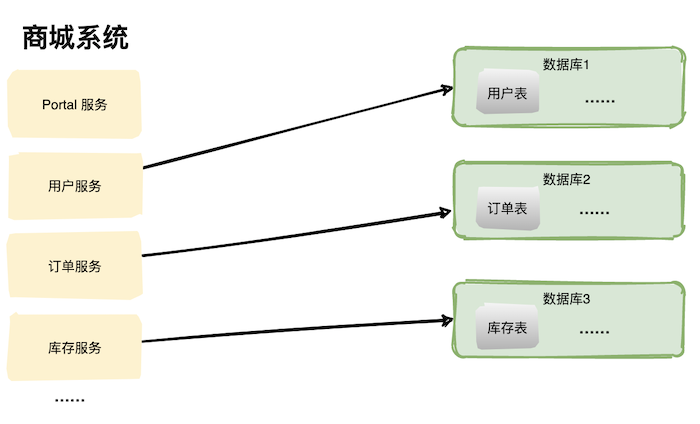
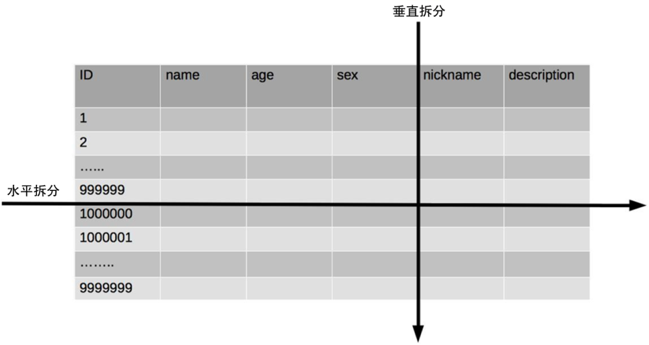
分表
每日表:只存储当天的数据。 每月表:可以起一个定时任务将前一天的数据全部迁移到当月表。 历史表:同样可以用定时任务把时间超过 30 天的数据迁移到 history表。
垂直切分:基于表或字段划分,表结构不同。 水平切分:基于数据划分,表结构相同,数据不同。
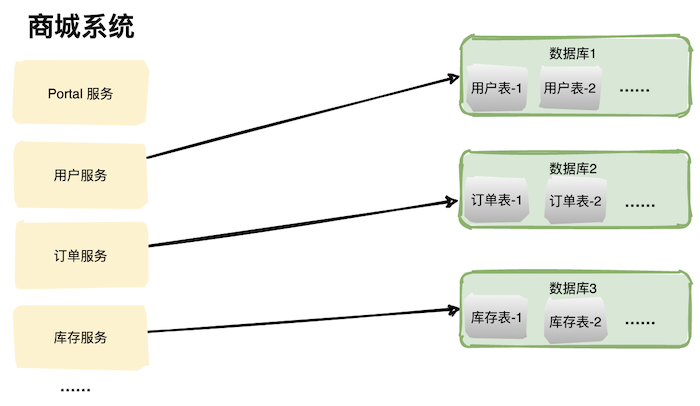
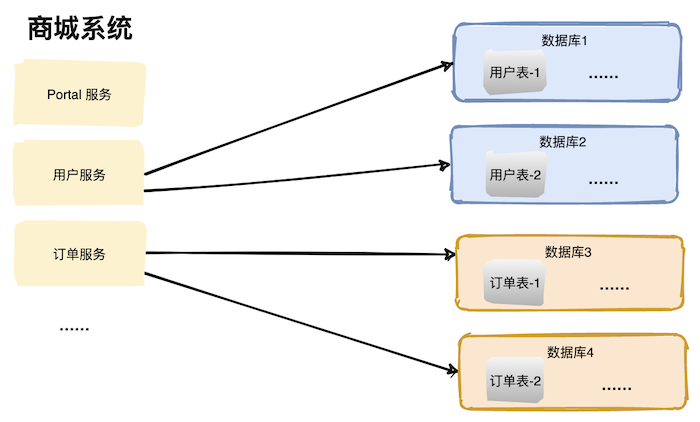
分库分表带来的复杂性
字段冗余:把需要关联的字段放入主表中,避免 join 操作; 数据抽象:通过ETL等将数据汇合聚集,生成新的表; 全局表:比如一些基础表可以在每个数据库中都放一份; 应用层组装:将基础数据查出来,通过应用程序计算组装;
UUID 基于数据库自增单独维护一张 ID表 号段模式 Redis 缓存 雪花算法(Snowflake) 百度uid-generator 美团Leaf 滴滴Tinyid
shardingsphere(前身 sharding-jdbc) Mycat
总结
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️
评论