 程序员的成长之路
程序员的成长之路





阅读本文大概需要 5 分钟。
来自:cnblogs.com/richaaaard/p/5226334.html
摘要
为什么我的搜索 *foo-bar* 无法匹配 foo-bar ?
为什么增加更多的文件会压缩索引(Index)?
为什么ElasticSearch占用很多内存?
版本
图解ElasticSearch
云上的集群
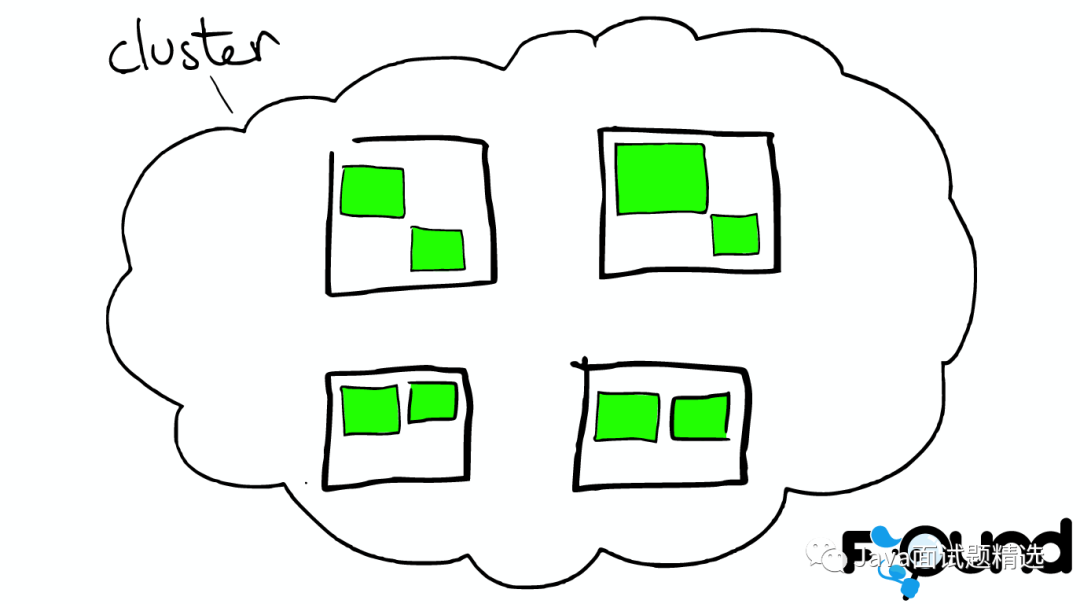
集群里的盒子

节点之间
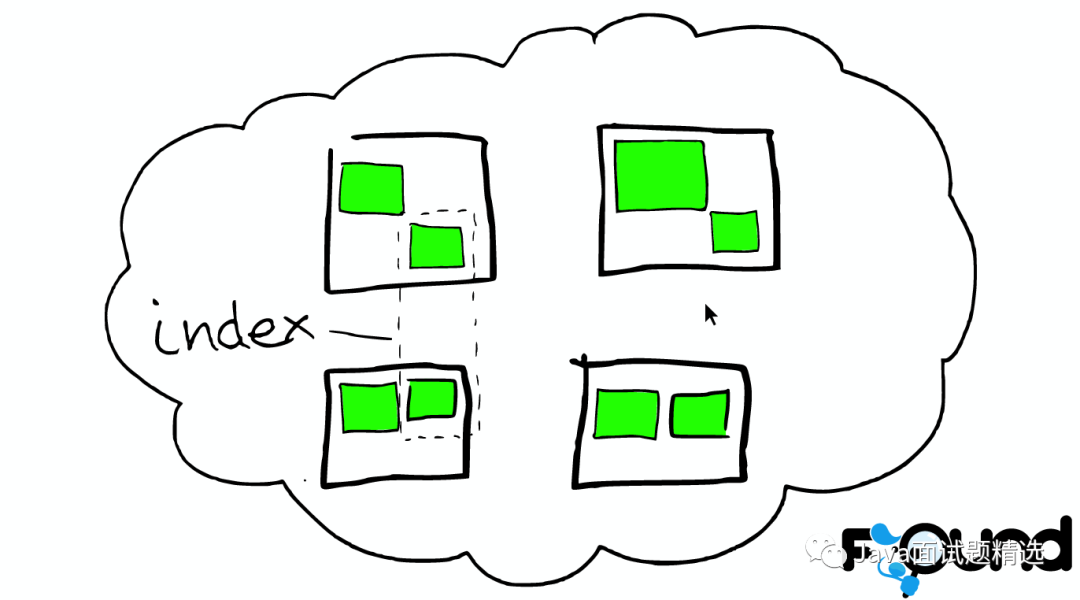
索引里的小方块
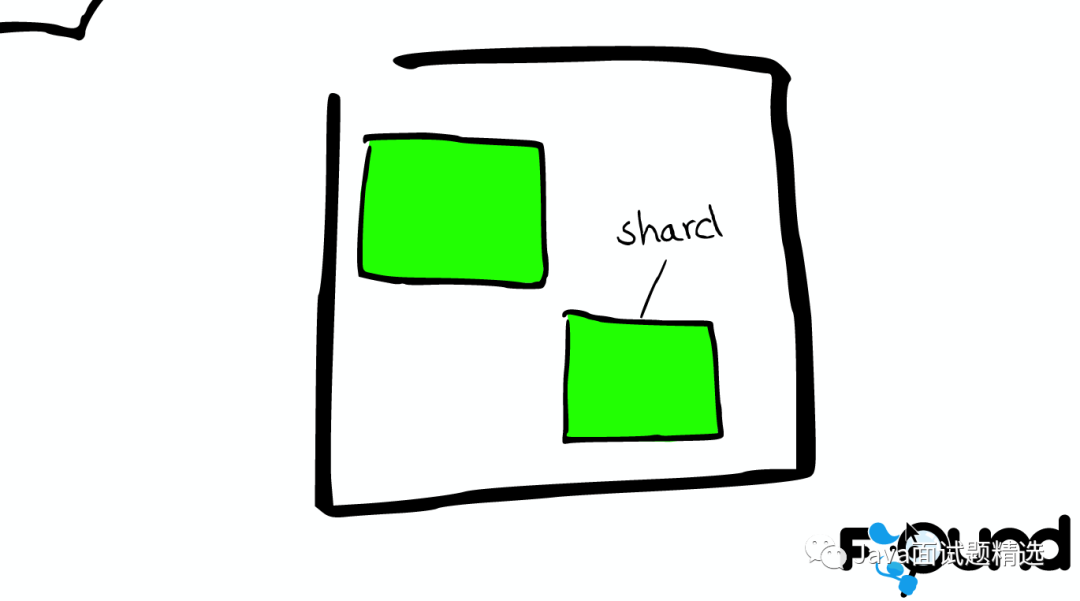
Shard=Lucene Index

图解Lucene
Mini索引——segment
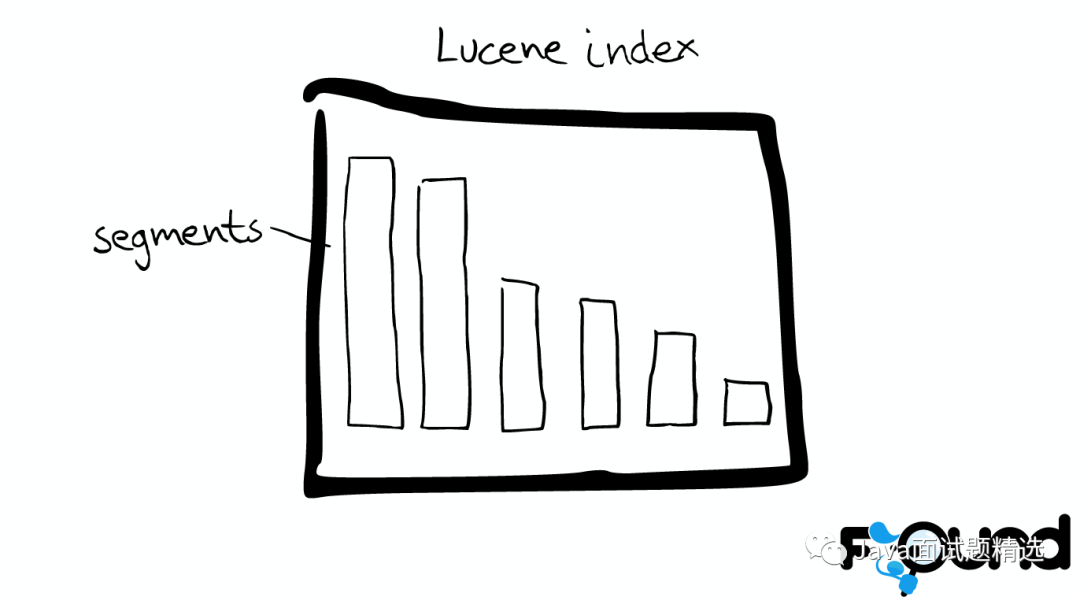
Segment内部
Inverted Index
Stored Fields
Document Values
Cache

最最重要的Inverted Index
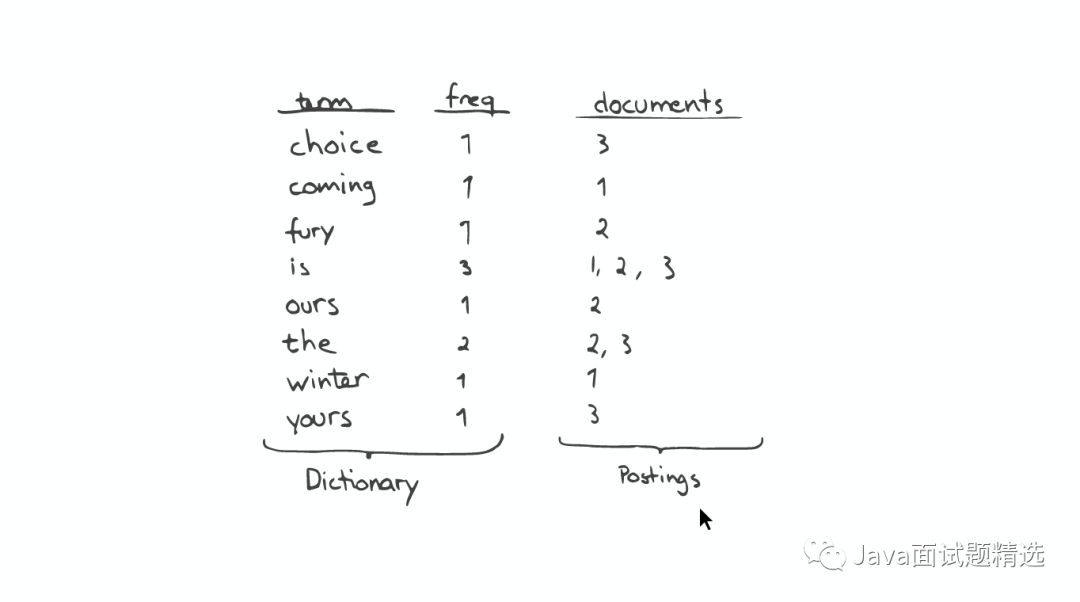
一个有序的数据字典Dictionary(包括单词Term和它出现的频率)。
与单词Term对应的Postings(即存在这个单词的文件)。

查询“the fury”

自动补全(AutoCompletion-Prefix)
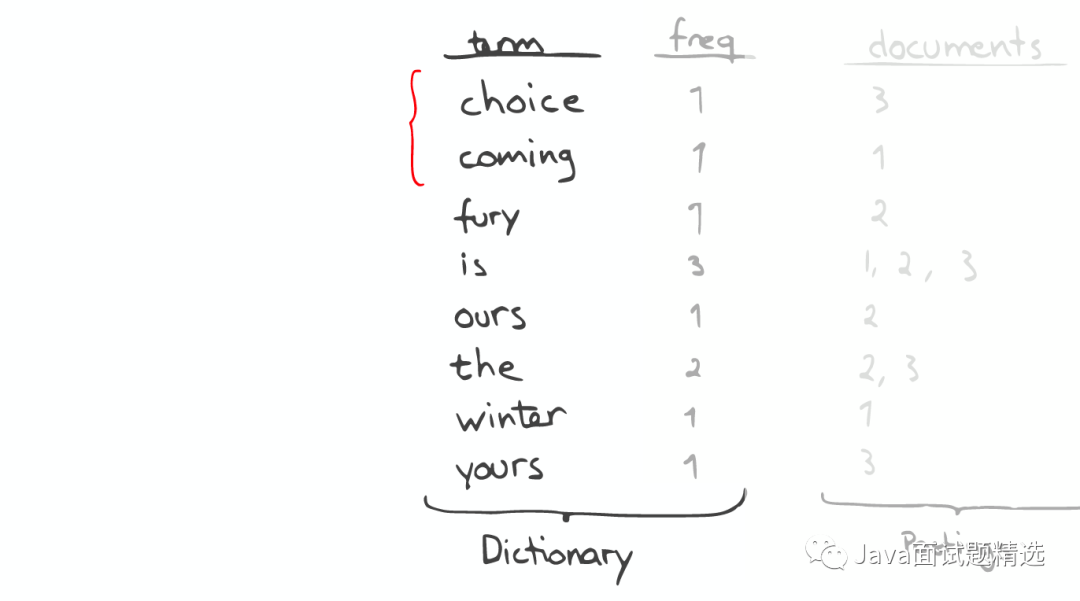
昂贵的查找
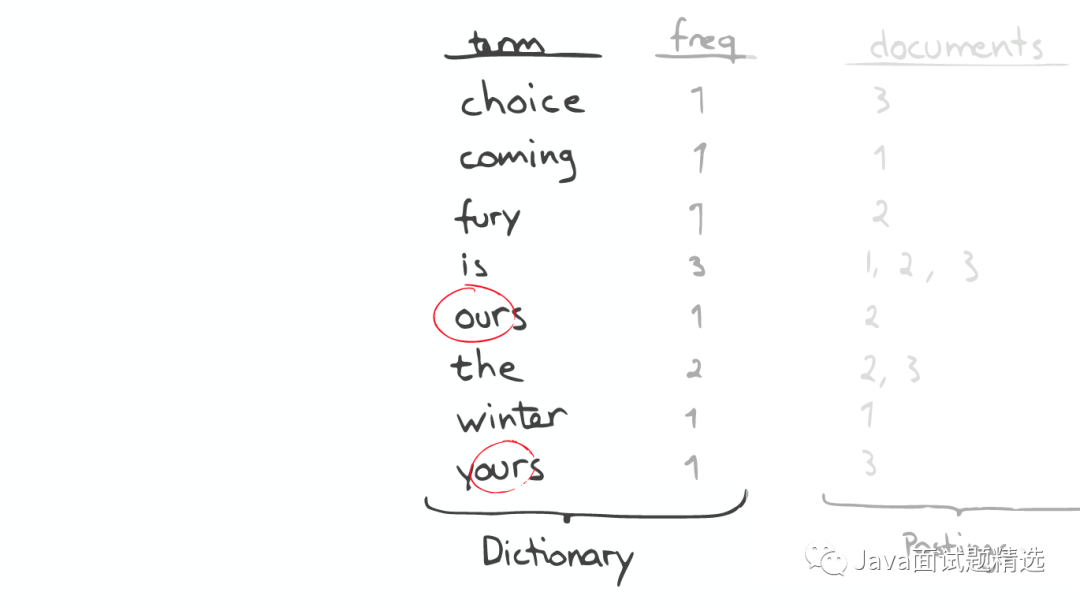
问题的转化

* suffix -> xiffus *
如果我们想以后缀作为搜索条件,可以为Term做反向处理。
(60.6384, 6.5017) -> u4u8gyykk
对于GEO位置信息,可以将它转换为GEO Hash。
123 -> {1-hundreds, 12-tens, 123}
对于简单的数字,可以为它生成多重形式的Term。
解决拼写错误

Stored Field字段查找

Document Values为了排序,聚合

搜索发生时
Segments是不可变的(immutable)
Delete? 当删除发生时,Lucene做的只是将其标志位置为删除,但是文件还是会在它原来的地方,不会发生改变
Update? 所以对于更新来说,本质上它做的工作是:先删除,然后重新索引(Re-index)
随处可见的压缩
Lucene非常擅长压缩数据,基本上所有教科书上的压缩方式,都能在Lucene中找到。
缓存所有的所有
Lucene也会将所有的信息做缓存,这大大提高了它的查询效率。
缓存的故事
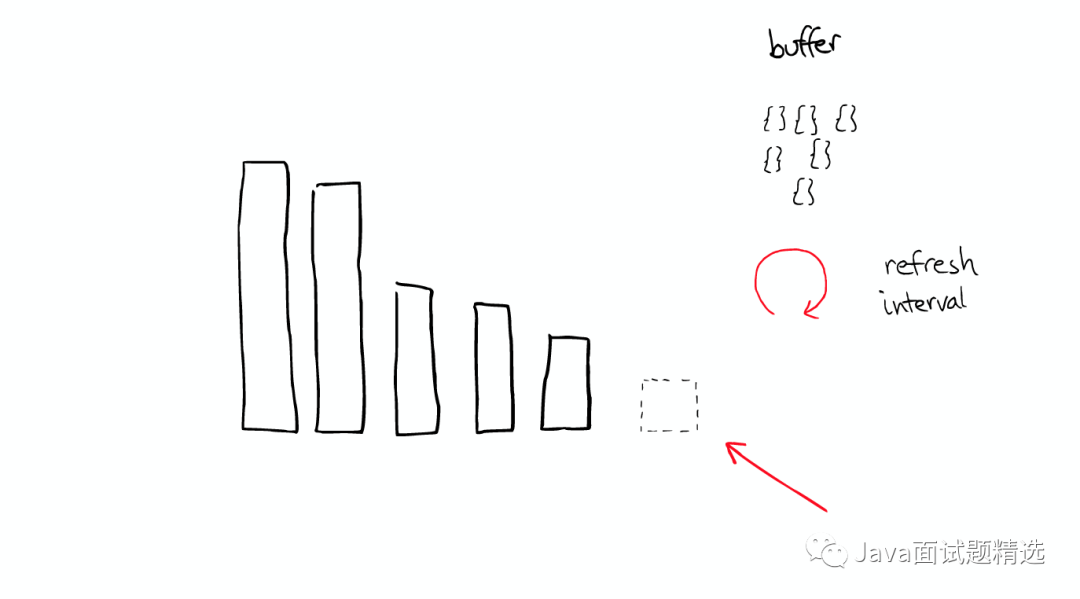
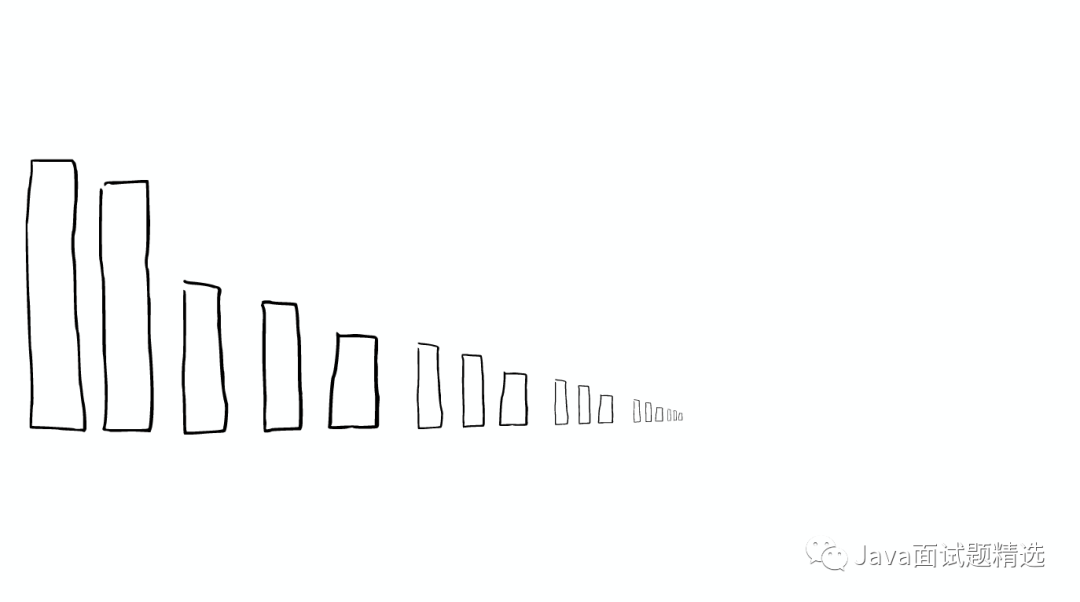

举个栗子



在Shard中搜索


对于日志文件的处理
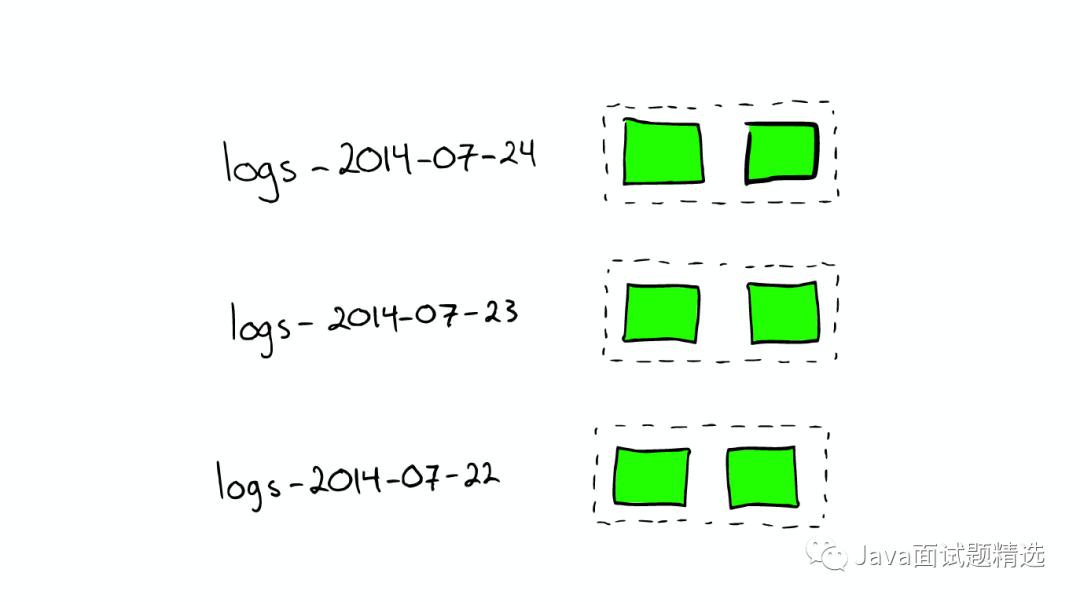
如何Scale
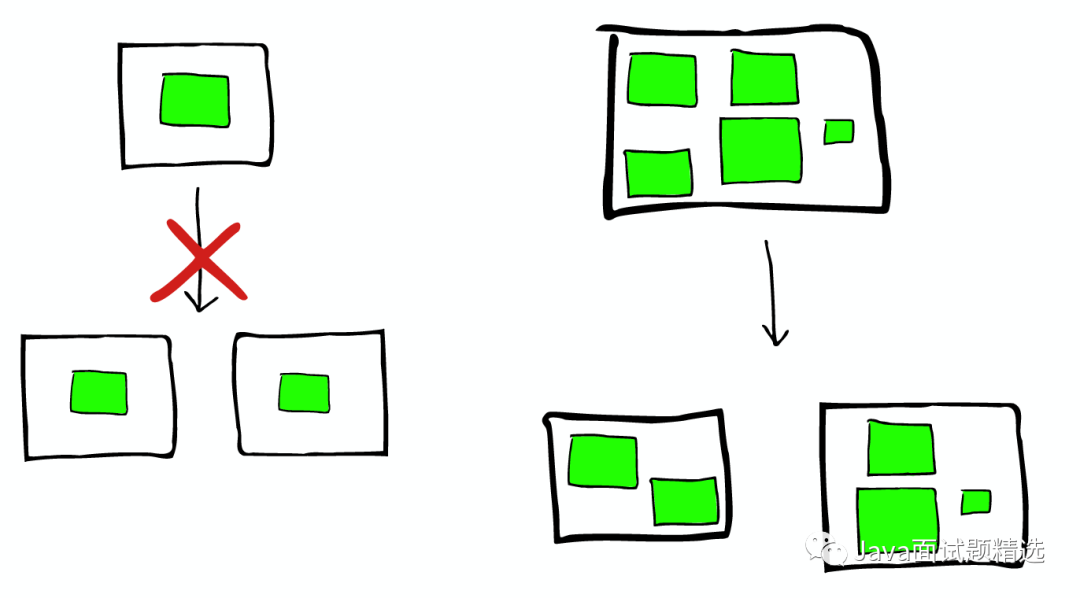
节点分配与Shard优化
为更重要的数据索引节点,分配性能更好的机器
确保每个shard都有副本信息replica
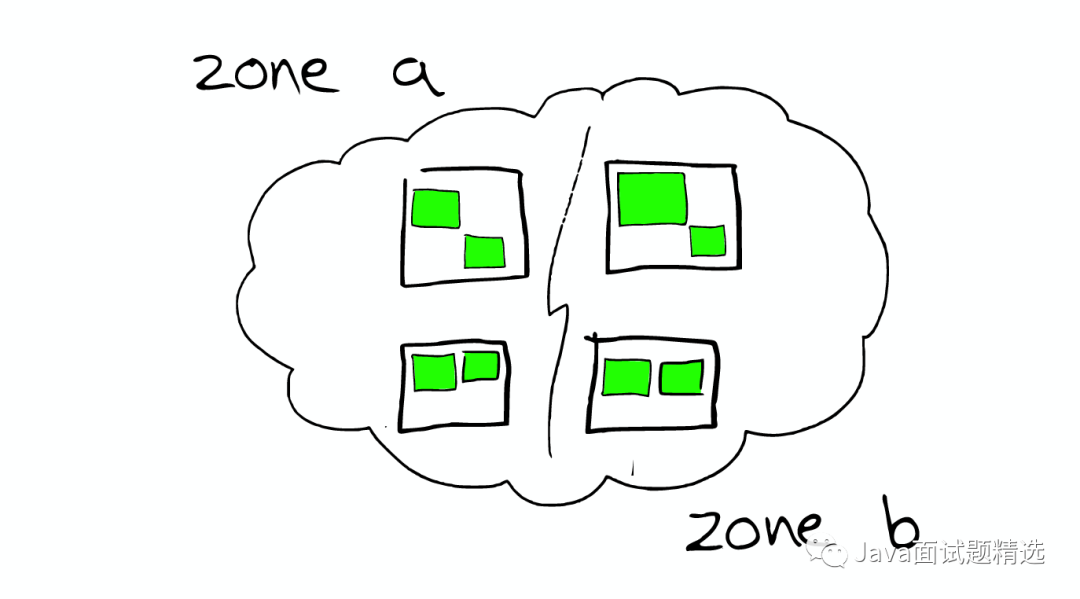
路由Routing
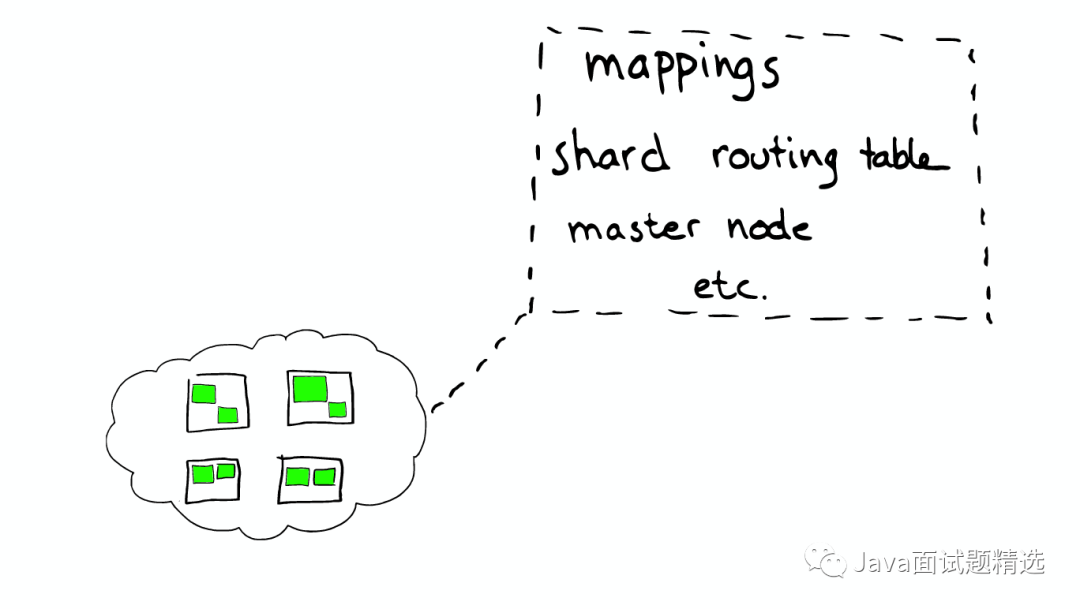
一个真实的请求

Query
Aggregation

请求分发

上帝节点

根据索引信息,判断请求会被路由到哪个核心节点
以及哪个副本是可用的
等等
路由

在真实搜索之前


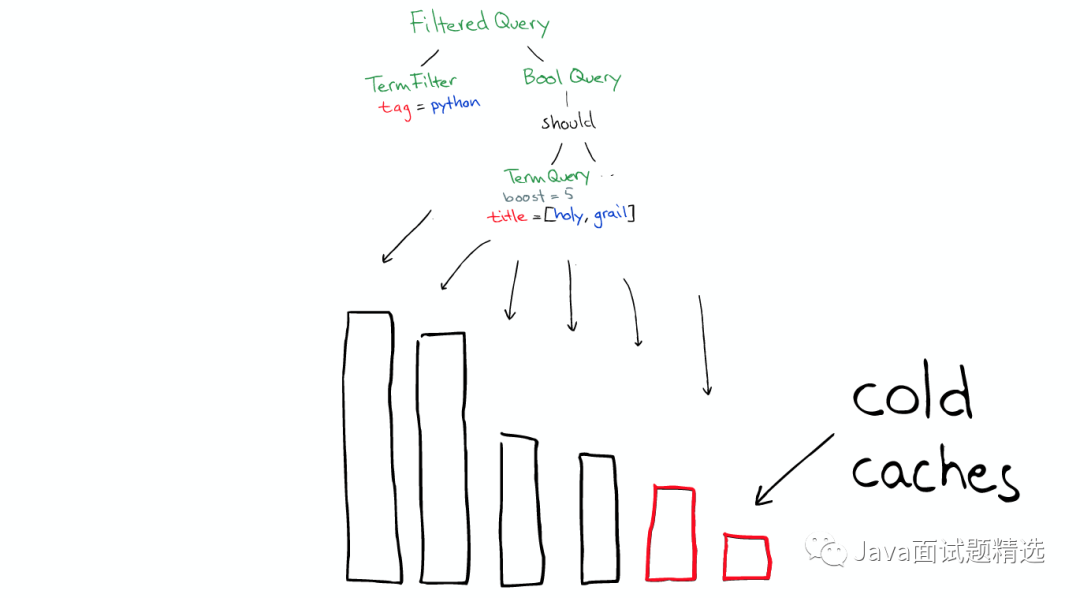

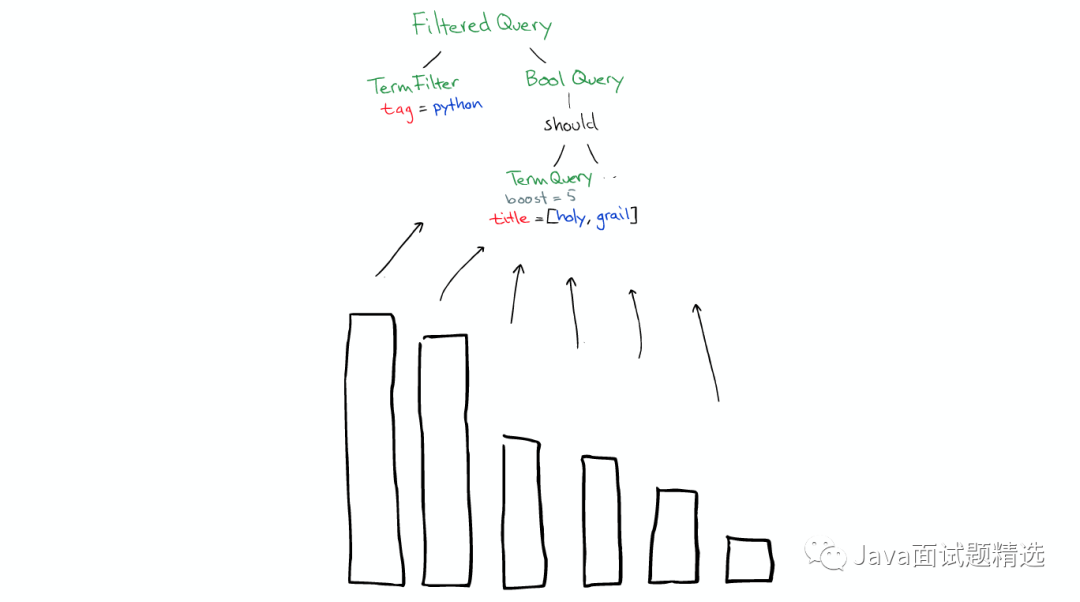
filters可以在任何时候使用
query只有在需要score的时候才使用
返回

扫码加入技术交流群,不定时「送书」

推荐阅读:
吊炸天的 Docker 图形化工具:Portainer,必须推荐给你!
SpringCloud中Hystrix容错保护原理及配置,看它就够了!
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
朕已阅 

