 七月在线实验室
七月在线实验室





本周关键词:ORC算法库、Python高性能CPU、SDV
pytorchOCR 基于pytorch的ocr算法库


已完成模型:
DBnet
PSEnet
PANnet
SASTnet
CRNN
检测模型效果:训练只在ICDAR2015文本检测公开数据集上
模型 | 骨干网络 | precision | recall | Hmean |
DB | ResNet50_7*7 | 85.88% | 79.10% | 82.35% |
DB | ResNet50_3*3 | 86.51% | 80.59% | 83.44% |
DB | MobileNetV3 | 82.89% | 75.83% | 79.20% |
SAST | ResNet50_7*7 | 85.72% | 78.38% | 81.89% |
SAST | ResNet50_3*3 | 86.67% | 76.74% | 81.40% |
PSE | ResNet50_7*7 | 84.10% | 80.01% | 82.01% |
PSE | ResNet50_3*3 | 82.56% | 78.91% | 80.69% |
PAN | ResNet18_7*7 | 81.80% | 77.08% | 79.37% |
PAN | ResNet18_3*3 | 83.78% | 75.15% | 79.23% |
模型压缩剪枝效果:
这里使用mobilev3作为backbone,在icdar2015上测试结果,未压缩模型初始大小为2.4M.
1 . 对backbone进行压缩
模型 | pruned method | ratio | model size(M) | precision | recall | Hmean |
DB | no | 0 | 2.4 | 84.04% | 75.34% | 79.46% |
DB | backbone | 0.5 | 1.9 | 83.74% | 73.18% | 78.10% |
DB | backbone | 0.6 | 1.58 | 84.46% | 69.90% | 76.50% |
2 . 对整个模型进行压缩
模型 | pruned method | ratio | model size(M) | precision | recall | Hmean |
DB | no | 0 | 2.4 | 85.70% | 74.77% | 79.86% |
DB | total | 0.6 | 1.42 | 82.97% | 75.10% | 78.84% |
DB | total | 0.65 | 1.15 | 85.14% | 72.84% | 78.51% |
模型蒸馏:
模型 | teacher | student | model size(M) | precision | recall | Hmean | improve(%) |
DB | no | mobilev3 | 2.4 | 85.70% | 74.77% | 79.86% | - |
DB | resnet50 | mobilev3 | 2.4 | 86.37% | 77.22% | 81.54% | 1.68 |
DB | no | mobilev3 | 1.42 | 82.97% | 75.10% | 78.84% | - |
DB | resnet50 | mobilev3 | 1.42 | 85.88% | 76.16% | 80.73% | 1.89 |
DB | no | mobilev3 | 1.15 | 85.14% | 72.84% | 78.51% | - |
DB | resnet50 | mobilev3 | 1.15 | 85.60% | 74.72% | 79.79% | 1.28 |
项目地址:
https://github.com/BADBADBADBOY/pytorchOCR
clothing-dataset 服装数据集

此数据集可自由用于任何目的,包括商业:例如:
创建教程或课程(免费或付费)
写一本书
Kaggle竞赛(作为外部数据集)
在任何公司培训内部模型
数据文件images.csv包括:
image - 图像的 ID(使用它从images/<ID>.jpg加载图像)
sender_id - 贡献图像的人的 ID
label - 图像的类
kids - 标记为“true”,说明它是孩子们的衣服
项目地址:
https://github.com/wbj0110/clothing-dataset
weibo-public-opinion-datasets 持续维护的微博舆情数据集
新浪微博是中国最大的公共社交媒体平台。最新、最受欢迎的社交活动将尽快在微博上披露和讨论。因此,构建实时、全面的微博民意数据集具有十分重要的意义。
目前,在指定的关键字和指定期限内,构建微博推文数据集的方法有两种:
(1)应用微博给出的高级搜索API:
(2) 浏览所有微博用户,在指定时间段内收集所有推文,然后使用指定的关键字过滤推文。
然而,对于第一种方法,由于微博搜索API的限制,一次性搜索的结果包含多达1000条推文,使得构建大规模数据集变得困难。至于第二种方法,虽然我们可以构建大型数据集,几乎没有遗漏,但穿越所有数十亿的微博用户需要很长的时间和大量的带宽资源。此外,大量微博用户处于非活动状态,浏览其主页是没有意义的,因为他们不得在指定时间段内发布任何推文。
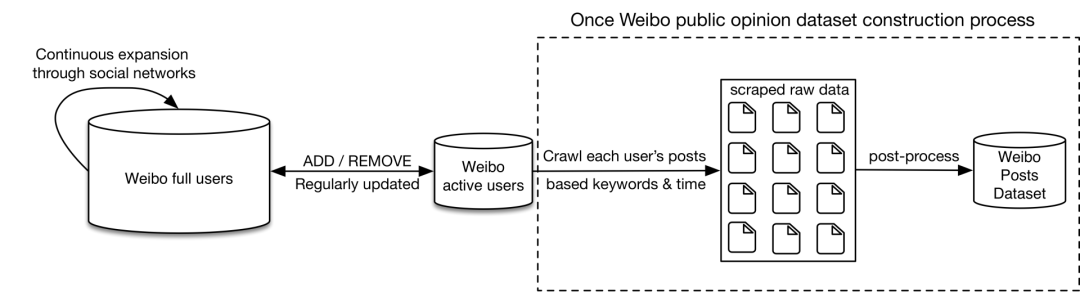
为了缓解这些局限性,我们提出了一种构建微博微博数据集的新方法,可以构建具有高建设效率的大型数据集。具体来说,我们首先构建并动态维护一个高基质微博活动用户池(只是所有用户的一小部分),然后我们只浏览这些用户,并在指定期间使用指定的关键字收集他们所有的推文。
基于种子用户和通过社会关系的持续扩展,我们首先建立了一个包含超过2.5亿用户的微博用户库。活动微博用户池基于微博用户池构建,遵循 4 条规则:
规则 | 规则 | ||
关注人数 | > 50 | 发布数 | > 50 |
粉丝人数 | > 50 | 最近发布 | < 30 天 |
最后,我们构建了一个拥有2000万用户的微博活跃用户库,占微博用户总数的8%。
项目地址:
https://github.com/nghuyong/weibo-public-opinion-datasets
scalene Python 的高性能 CPU 内存分析器
Scalene 是一个 Python 的高性能 CPU 和 内存分析器,它可以做到很多其他Python分析器不能做到的事情。它在能提供更多详细信息的同时,比其他的分析器要快几个数量级。
Scalene 是 很快的。它使用采样的方式而不是直接测量或者依靠Python的追踪工具。它的开销一般不超过10-20% (通常更少)。
Scalene 是 精确的。和大部分其他的Python分析器不同,Scalene 在 行级别 下执行CPU分析,在你的程序中指出对应代码行的执行时间。和大多数分析器所返回的功能级分析结果相比,这种程度的细节可能会更有用。
Scalane 可以区分在Python中运行的时间和在native代码(包括库)中花费的时间。大多数的Python程序员并不会去优化native代码(通常在Python实现中或者所依赖的外部库),所以区分这两种运行时间,有助于开发者能够将优化的工作专注于他们能够实际改善的代码上。
Scalene 可以 分析内存使用情况。除了追踪CPU使用情况,Scalene还指出对应代码行的内存增长。这是通过指定内存分配器来实现的。
Scalene 会生成 每行 的内存分析,以此更容易的追踪内存泄露。
Scalene 会分析 内存拷贝量, 从而易于发现意外的内存拷贝。特别是因为跨越Python和底层库的边界导致的意外 (例如:意外的把 numpy 数组转化成了Python数组,反之亦然)。
功能比较分析:
Profiler | Line-level | CPU | Wall clock vs. CPU time | Python vs. native | Memory | Unmodified code | Threads |
cProfile | ✔ | wall clock | ✔ | ||||
Profile | ✔ | CPU time | ✔ | ||||
pyinstrument | ✔ | wall clock | ✔ | ||||
line_profiler | ✔ | ✔ | wall clock | ||||
pprofile (deterministic) | ✔ | ✔ | wall clock | ✔ | ✔ | ||
pprofile (statistical) | ✔ | ✔ | wall clock | ✔ | ✔ | ||
yappi (CPU) | ✔ | CPU time | ✔ | ✔ | |||
yappi (wallclock) | ✔ | wall clock | ✔ | ✔ | |||
py-spy | ✔ | ✔ | both | ✔ | ✔ | ||
memory_profiler | ✔ | ✔ | |||||
scalene (CPU only) | ✔ | ✔ | both | ✔ | ✔ | ✔ | |
scalene (CPU + memory) | ✔ | ✔ | both | ✔ | ✔ | ✔ | ✔ |
项目地址:
https://github.com/plasma-umass/scalene
SDV 用于表格、关系和时间系列数据的合成数据生成
然后,合成数据可用于补充、增强,在某些情况下,在训练机器学习模型时替换真实数据。此外,它还允许对机器学习或其他数据依赖软件系统进行测试,而不会面临数据披露带来的暴露风险。
项目使用几个概率图形建模和基于深度学习的技术。为了实现各种数据存储结构,我们采用独特的分层生成建模和递归采样技术。
当前功能和特定:
具有以下功能的单台合成数据生成器:
使用基于科普拉斯和深度学习的模型。
以最少的用户输入处理多个数据类型和缺失数据。
支持预定义和自定义约束和数据验证。
合成数据生成器,用于复杂的多表、关系数据集,具有以下功能:
使用自定义和灵活的 JSON 模式定义整个多表数据集元数据集 。
使用科普拉斯和递归建模技术。
合成数据生成器,用于多类型、多变型时间系列,具有以下功能:
使用统计、自动回归和深度学习模型。
基于上下文属性的有条件采样。
项目地址:
https://github.com/sdv-dev/SDV
TensorflowASR 集成Tensorflow 2版本的端到端语音识别模型
参照librosa库,用TF2实现了语音频谱特征提取的层,这样在跨平台部署时会更加容易。
快速使用:
下载预训练模型,修改 am_data.yml/lm_data.yml 里的目录参数(running_config下的outdir参数),并在修改后的目录中添加 checkpoints 目录,
将model_xx.h5(xx为数字)文件放入对应的checkpoints目录中,
修改run-test.py中的读取的config文件(am_data.yml,model.yml)路径,运行run-test.py即可。
C++的demo已经提供。测试于TensorflowC 2.3.0版本
项目地址:
https://github.com/Z-yq/TensorflowASR
回顾精品内容
推荐系统
机器学习
自然语言处理(NLP)
1、AI自动评审论文,CMU这个工具可行吗?我们用它评审了下Transformer论文
2、Transformer强势闯入CV界秒杀CNN,靠的到底是什么"基因"
计算机视觉(CV)
1、9个小技巧让您的PyTorch模型训练装上“涡轮增压”...
GitHub开源项目:
1、火爆GitHub!3.6k Star,中文版可视化神器现身
2、两次霸榜GitHub!这个神器不写代码也可以完成AI算法训练
3、登顶GitHub大热项目 | 非监督GAN算法U-GAT-IT大幅改进图像转换
每周推荐:
1、本周优秀开源项目分享:无脑套用格式、开源模板最高10万赞
七月在线学员面经分享:
1、先工程后算法:美国加州材料博后辞职到字节40万offer

