 NLP情报局
NLP情报局





初号机暴走事件
2015年第三使徒登陆第三新东京市,初号机在面对第三使徒时,由于真嗣首次驾驶EVA作战,战况非常残酷,初号机的头部被第三使徒刺穿,左腕被扯断,导致与初号机保持神经连接的真嗣失去了意识。在这样极限的情况下,初号机开始了暴走状态,使用再生功能修复了左腕,并且徒手撕裂了第三使徒的AT Field,虐杀了第三使徒。
EVA粉丝可以在看完文章后去B站温习一下~

上面这段文本描述了初号机的第二次暴走事件,倘若我们想用人工智能的技术从这段文本中抽取出“初号机暴走事件”,需要用到NLP领域的“事件抽取技术”。
接下来笔者将分别介绍事件定义、任务定义、数据标注、事件抽取模型以及模型demo。
1 事件定义
事件是指在一定时间、地点发生的涉及一个或多个参与者的具体行为,通常可以描述为一种状态的变化[1]。有的情况下,事件的结构是预先定义好的,这类事件属于“封闭领域”事件,比如这里的初号机暴走事件。
事件类型 暴走事件 事件论元 暴走时间:2015年 暴走地点:第三新东京市 暴走原因:真嗣失去了意识 暴走主角:初号机 暴走后果:虐杀了第三使徒
2 事件抽取任务定义
事件抽取的目的是检测文本中存在的事件实例,并且识别出存在的事件类型及所有的参与者和属性。简单的理解就是从非结构化的文本中获取结构化表示的事件实例。
3 数据标注
事件抽取也是一种信息抽取任务,虽然抽取的是一定结构的文本信息,但简单来看也只是抽取出表示事件论元的一些文本片段,以及确定某个事件类型,加上这里仅仅涉及到单事件的抽取,不存在多个事件的论元嵌套问题,而文本片段可以看作是实体,因此可以使用简单的命名实体识别(NER)方法来抽取出事件论元的文本片段。
一段文本中存在的事件类型往往由关键的触发词隐式地表达出来,例如这段文本的“暴走状态”,这种隐式的表达也体现在整段文本的语义表达中,因此可以结合全文的语义编码对事件类型进行分类。总的来说,可以联合预测文本的事件类型以及抽取出事件论元的实体。
所以标注的形式基本可以确定下来,事件类型的标注看作文本分类的标注,把数据集的事件类型转换为数字集合(0,1,2,...,k),获得该文本的事件类型分类标签 L ∈[0, k]。
直接把事件论元作为实体类型,例如暴走时间、暴走地点; 把事件类型和事件论元结合起来作为实体类型,例如暴走事件—暴走时间、暴走事件—暴走原因
后者能够更好的联合文本事件类型分类结果抽取事件实例,因此这里选择后者的标注方式,采用BIO标签对文本进行序列标注(标注样例如下)。

事件抽取模型
这里介绍一种笔者用到的事件抽取模型。

文本输入BERT编码器分别获得句向量编码(batch, hidden_size)和序列编码(batch, sequence_len, hidden_size)。句向量输出用于分类器对事件类型进行分类,编码输出用于BIO序列标注模型抽取实体。
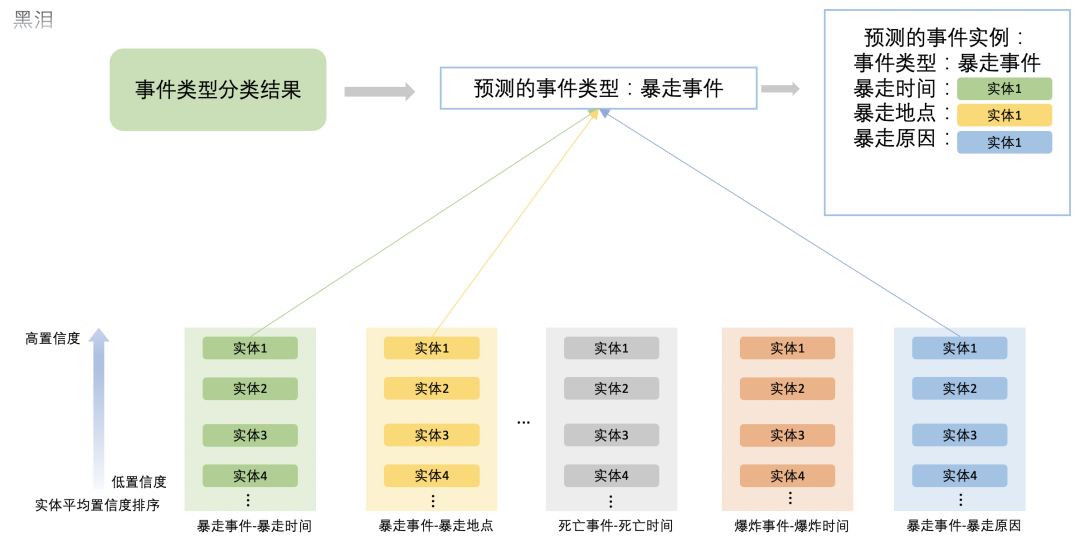
预测过程中,对抽取出的每种”事件类型—论元“实体进行平均置信度排序,筛选出每种“事件类型-论元”中置信度最高的实体,再结合文本预测的事件类型对剩余”事件类型—论元“实体进行筛选,留下与预测的事件类型相匹配的论元实体,组合成预测的事件实例。
筛选过程如下:
模型Demo
from transformers import BertPreTrainedModel, BertModelclass BertForEventExtract(BertPreTrainedModel):def __init__(self, config):super(BertForEventExtract, self).__init__(config)self.bert = BertModel(config) # 定义BERT编码器self.num_labels = config.num_labels #实体BIO标签self.event_type_outputs = nn.Linear(config.hidden_size, 5) # 假设这里一共有5种事件类型,该层用于对文本句向量进行事件类型分类self.dropout = nn.Dropout(config.hidden_dropout_prob)self.BIO_classifier = nn.Linear(config.hidden_size, config.num_labels) # 该层用于对每个字符进行BIO标签分类self.init_weights()def forward(self, input_ids, attention_mask=None, token_type_ids=None, position_ids=None, head_mask=None, labels=None):outputs = self.bert(input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids,head_mask=head_mask) # 获取BERT的输出sequence_output = outputs[0] #序列编码输出pooled_output = outputs[1] #序列句向量输出# 预测BIO实体sequence_output = self.dropout(sequence_output)BIO_logits = self.BIO_classifier(sequence_output)# 预测事件类型pooled_output = self.dropout(pooled_output)event_type_logits = self.event_type_outputs(pooled_output)if labels is not None:BIO_labels, event_type_label = labelsBIO_loss = nn.CrossEntropyLoss(ignore_index=-1)(BIO_logits.view(-1, self.num_labels), BIO_labels.view(-1))event_type_loss = nn.CrossEntropyLoss()(event_type_logits, event_type_label.view(-1))outputs = BIO_loss + event_type_losselse:outputs = (BIO_logits, event_type_logits)return outputs
引用
[1]Ace (Automatic Content Extraction) English Annotation Guidelines for Events, Linguistic Data Consortium, Philadelphia, PA, USA, 2005.

