 Python绿色通道
Python绿色通道




↑ 关注 + 星标 ,每天学Python新技能
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
后台回复【大礼包】送你Python自学大礼包
01
前言
今日次条文章教大家如何学会爬取『京东』商城商品数据。
今天教大家如何爬取『京东』平台里面『各种品牌』笔记本电脑数据约30000条进行统计分析,最后进行可视化展示(各种可视化图表真好看!!)
本文干货内容:
爬取京东商品所有笔记本电脑数据
数据存储到excel
pandas对excel数据进行统计分析
绘制各种可视化图表
02
爬取数据
1.链接分析

之前介绍了爬取其中的一种商品,这里需要爬取『各种品牌』,对应的链接也不一样,需要进行分析。
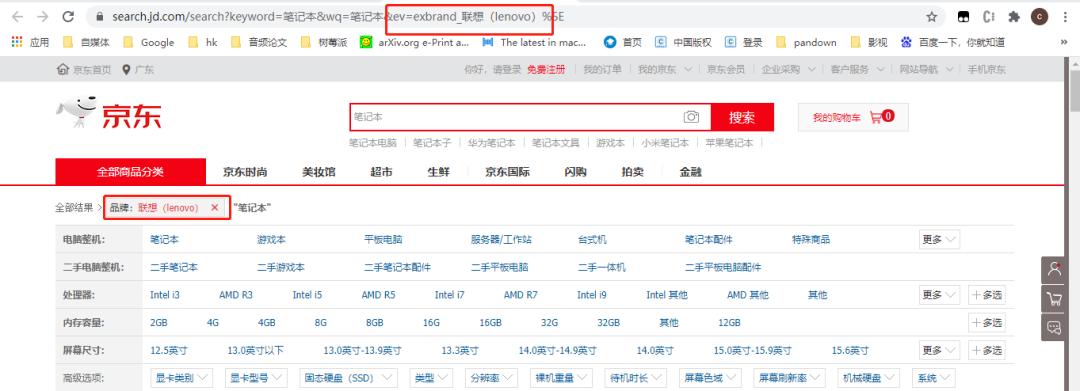
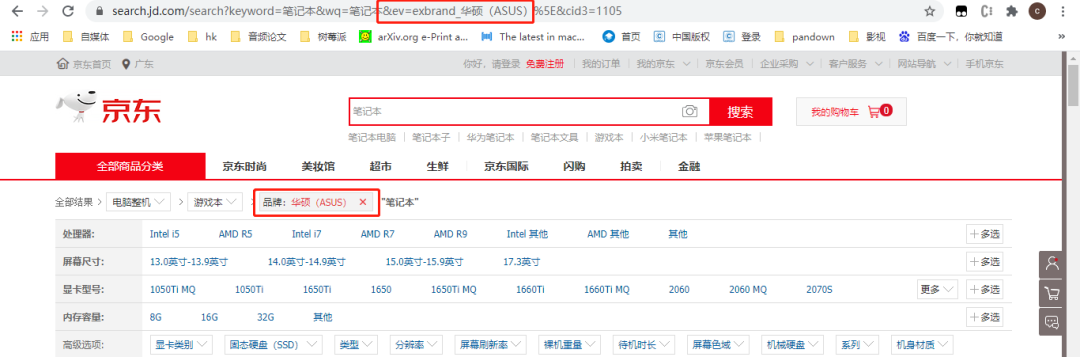
可以分析链接中,ev参数对应着品牌的名称,因此只需要更改ev参数就可以爬取不同品牌的笔记本数据。
避坑:
注意不要遗漏后面的括号:联想(lenovo),少了后面括号有一些品牌的数据无法爬取(亲测证明)。
此外不同品牌的笔记本商品数据总量(总页数)不一样,因此同样需要对应进行汇总,这里定义了字典去存储1.品牌名称和2.总页数。
brand_dict={'联想(lenovo)':100,'ThinkPad':100,'戴尔(DELL)':100,'惠普(HP)':100,'华为(HUAWEI)':100,'Apple':100,'小米(MI)':47,'宏碁(acer)':43,'荣耀(HONOR)':21,'机械革命(MECHREVO)':31,'微软(Microsoft)':100,'LG':3,'神舟(HASEE)':34,'VAIO':3,'三星(SAMSUNG)':47,}
2.获取不同品牌笔记本数据
#李运辰 公众号:python爬虫数据分析挖掘#遍历每一页def getpage(brand_dict):global countfor k, v in brand_dict.items():page = 1s = 1brand = str(k)try:for i in range(1, int(v) + 1):url = "https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_" + str(brand) + "&page=" + str(page) + "&s=" + str(s) + "&click=1"getlist(url, brand)page = page + 2s = s + 60print("品牌=" + str(k) + ",页数=" + str(v) + ",当前页数=" + str(i))except:pass
这里加入了try-except,防止其中某一页爬取失败,造成程序终止!
3.遍历每一页数据
#李运辰 公众号:python爬虫数据分析挖掘###获取每一页的商品数据def getlist(url,brand):global count#url="https://search.jd.com/search?keyword=笔记本&wq=笔记本&ev=exbrand_联想%5E&page=9&s=241&click=1"res = requests.get(url,headers=headers)res.encoding = 'utf-8'text = res.textselector = etree.HTML(text)list = selector.xpath('//*[@id="J_goodsList"]/ul/li')for i in list:title=i.xpath('.//div[@class="p-name p-name-type-2"]/a/em/text()')[0]price = i.xpath('.//div[@class="p-price"]/strong/i/text()')[0]
这里只获取商品标题和商品价格
4.数据存储到excel
定义excel表头
#李运辰 公众号:python爬虫数据分析挖掘import openpyxloutwb = openpyxl.Workbook()outws = outwb.create_sheet(index=0)outws.cell(row=1, column=1, value="index")outws.cell(row=1, column=2, value="brand")outws.cell(row=1, column=3, value="title")outws.cell(row=1, column=4, value="price")count = 2
写数据并保存成笔记本电脑-李运辰.xls
outws.cell(row=count, column=1, value=str(count-1))outws.cell(row=count, column=2, value=str(brand))outws.cell(row=count, column=3, value=str(title))outws.cell(row=count, column=4, value=str(price))outwb.save("笔记本电脑-李运辰.xls") # 保存
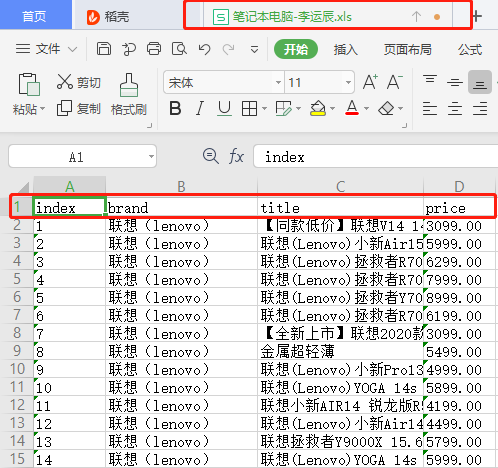
这样我们的数据就已经爬取完成。
下面开始对这些数据进行统计分析,最后绘制可视化图。
03
可视化分析
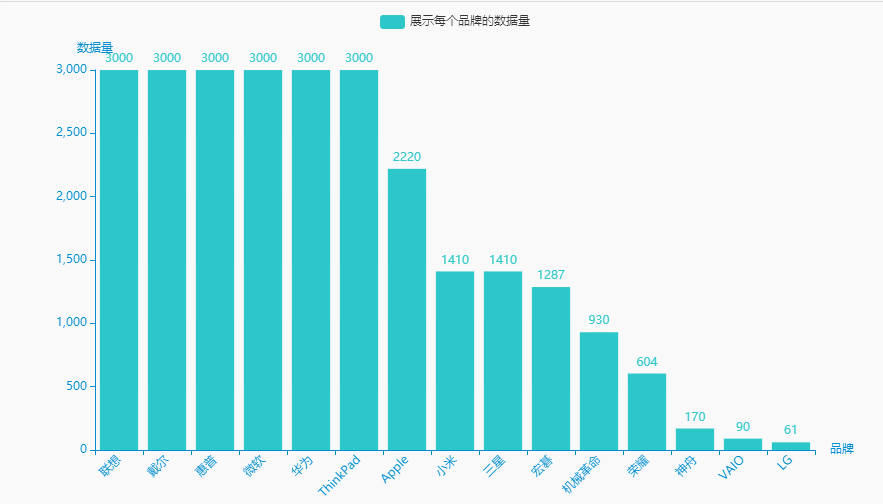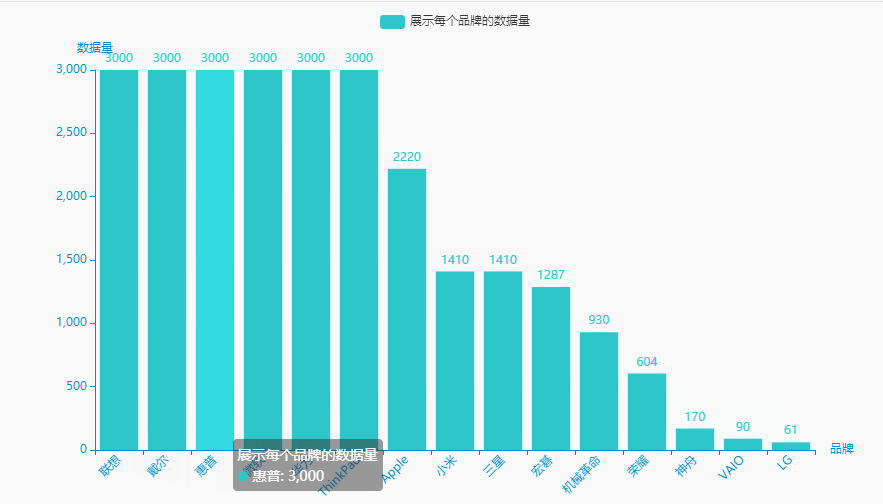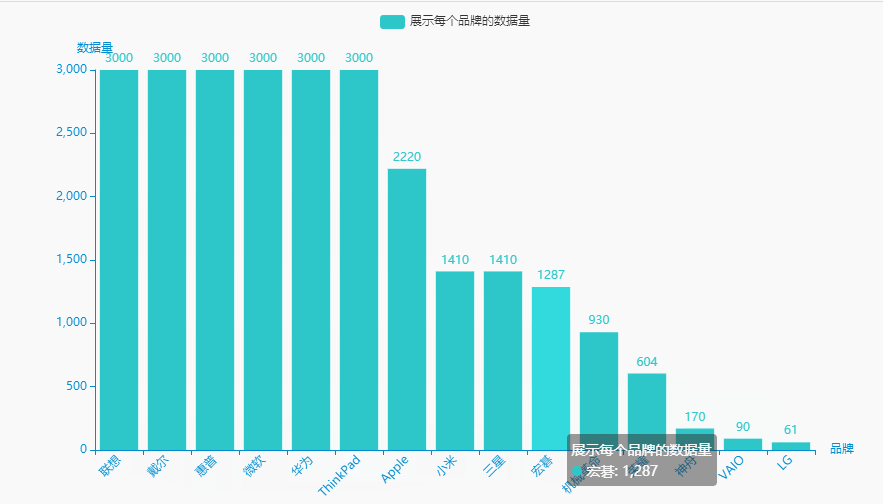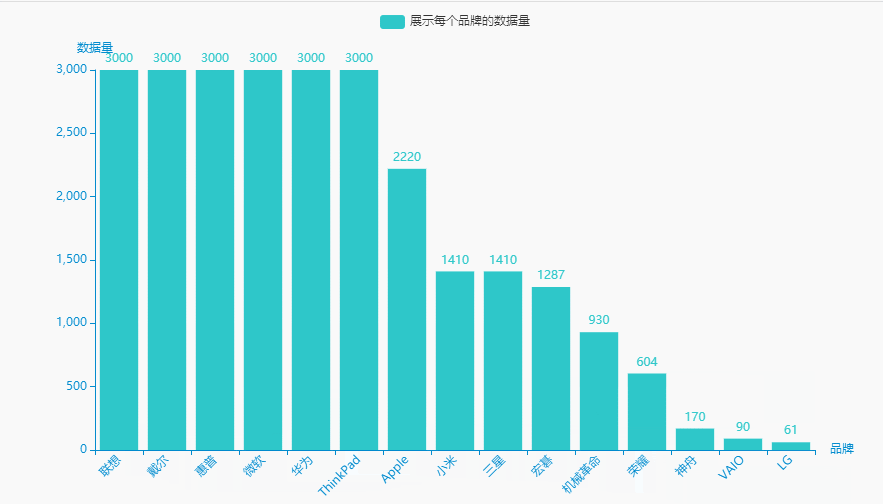
1.展示每个品牌的数据量
pandas读取excel
#李运辰 公众号:python爬虫数据分析挖掘#读入数据df_all = pd.read_csv("笔记本电脑-李运辰.csv",engine="python")df = df_all.copy()# 重置索引df = df.reset_index(drop=True)
统计分析
brand_counts = df.groupby('brand')['price'].count().sort_values(ascending=False).reset_index()brand_counts.columns = ['品牌', '数据量']name = (brand_counts['品牌']).tolist()dict_values = (brand_counts['数据量']).tolist()
可视化展示
#李运辰 公众号:python爬虫数据分析挖掘#链式调用c = (Bar(init_opts=opts.InitOpts( # 初始配置项theme=ThemeType.MACARONS,animation_opts=opts.AnimationOpts(animation_delay=1000, animation_easing="cubicOut" # 初始动画延迟和缓动效果))).add_xaxis(xaxis_data=name) # x轴.add_yaxis(series_name="展示每个品牌的数据量", yaxis_data=dict_values) # y轴.set_global_opts(title_opts=opts.TitleOpts(title='', subtitle='', # 标题配置和调整位置title_textstyle_opts=opts.TextStyleOpts(font_family='SimHei', font_size=25, font_weight='bold', color='red',), pos_left="90%", pos_top="10",),xaxis_opts=opts.AxisOpts(name='品牌', axislabel_opts=opts.LabelOpts(rotate=45)),# 设置x名称和Label rotate解决标签名字过长使用yaxis_opts=opts.AxisOpts(name='数据量'),).render("展示每个品牌的数据量.html"))
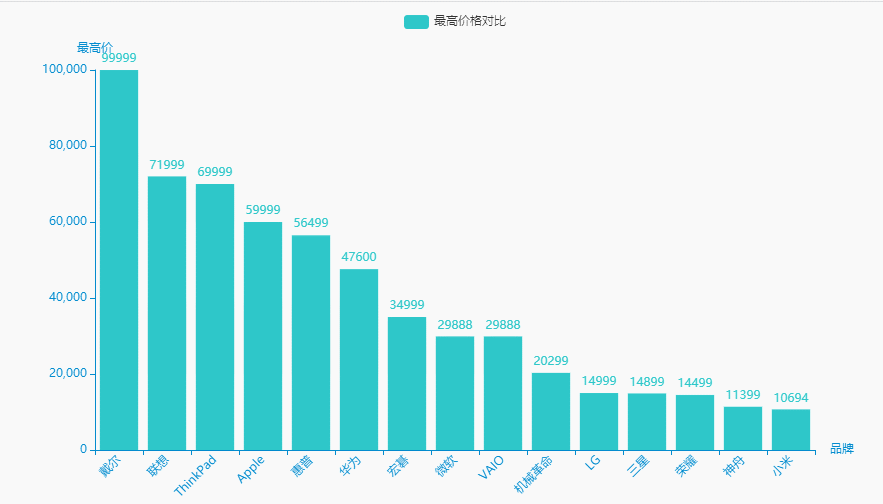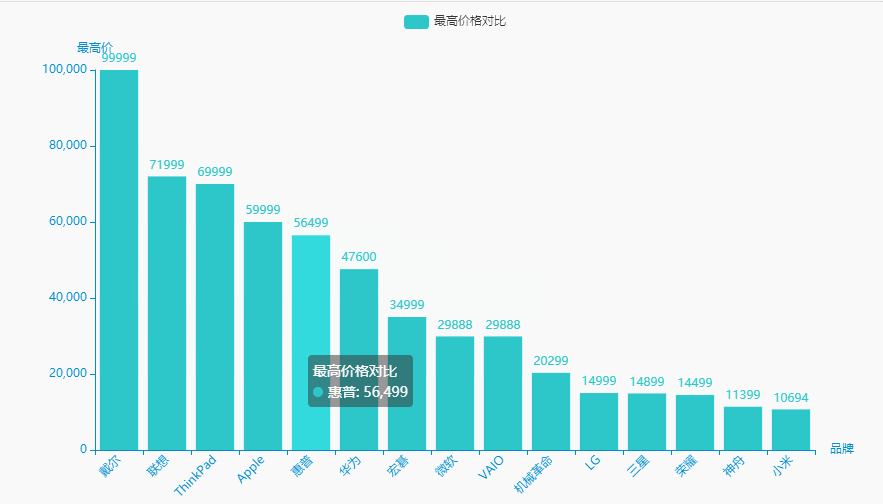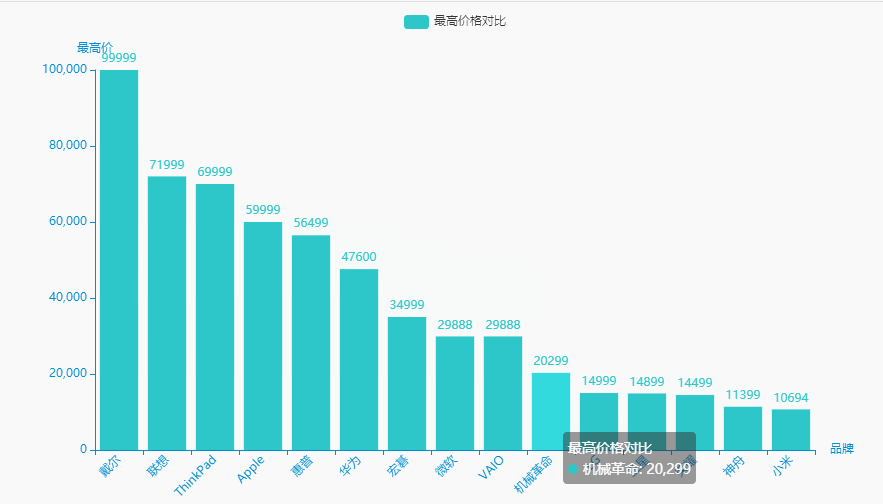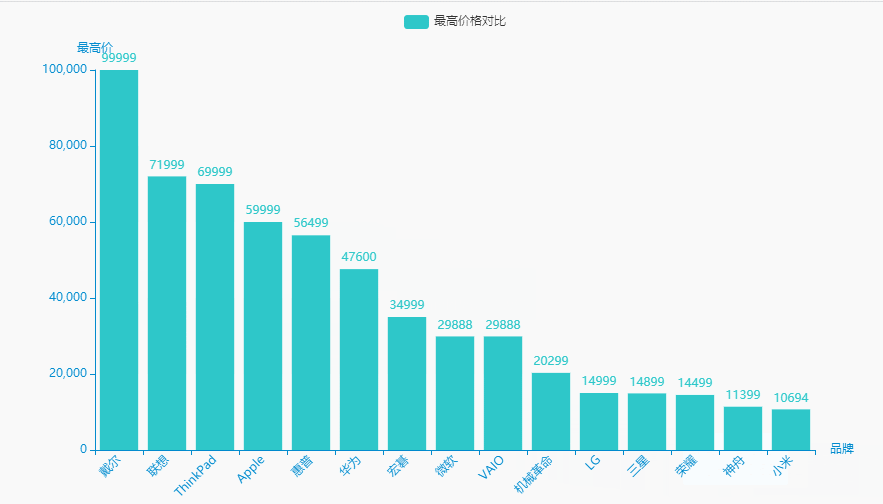
2.最高价格对比
统计分析
brand_maxprice = df.groupby('brand')['price'].agg(['max'])['max'].sort_values(ascending=False).reset_index()brand_maxprice.columns = ['品牌', '最高价']name = (brand_maxprice['品牌']).tolist()dict_values = (brand_maxprice['最高价']).tolist()
可视化展示
for i in range(0, len(name)):if "(" in name[i]:name[i] = name[i][0:int(name[i].index("("))]c = (Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS,animation_opts=opts.AnimationOpts(animation_delay=1000, animation_easing="cubicOut"))).add_xaxis(xaxis_data=name).add_yaxis(series_name="最高价格对比", yaxis_data=dict_values).set_global_opts(title_opts=opts.TitleOpts(title='', subtitle='',title_textstyle_opts=opts.TextStyleOpts(font_family='SimHei', font_size=25, font_weight='bold', color='red',), pos_left="90%", pos_top="10",),xaxis_opts=opts.AxisOpts(name='品牌', axislabel_opts=opts.LabelOpts(rotate=45)),yaxis_opts=opts.AxisOpts(name='最高价'),).render("最高价格对比.html"))
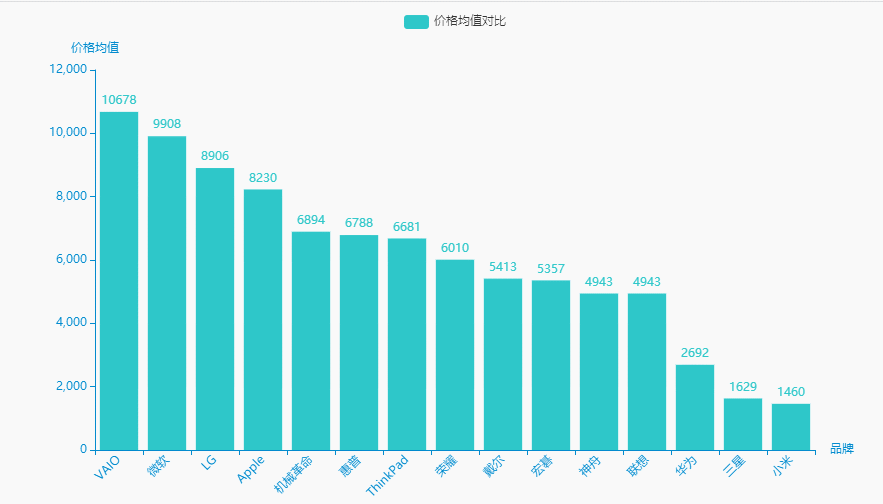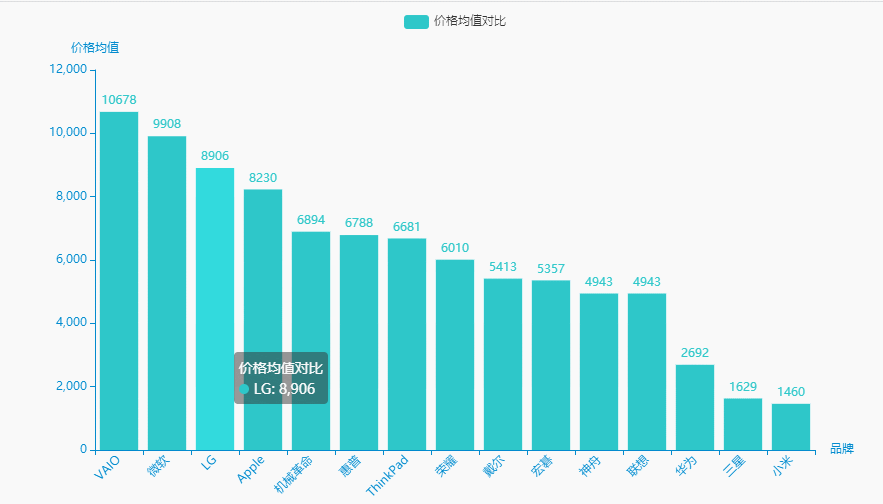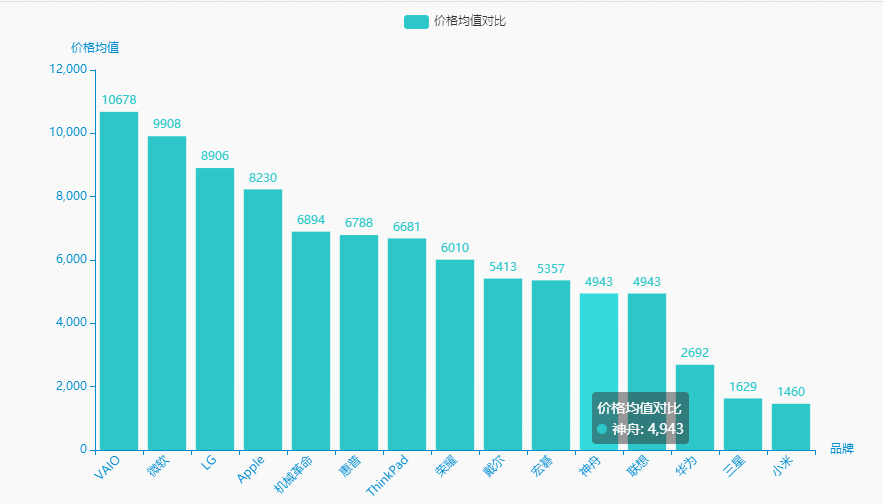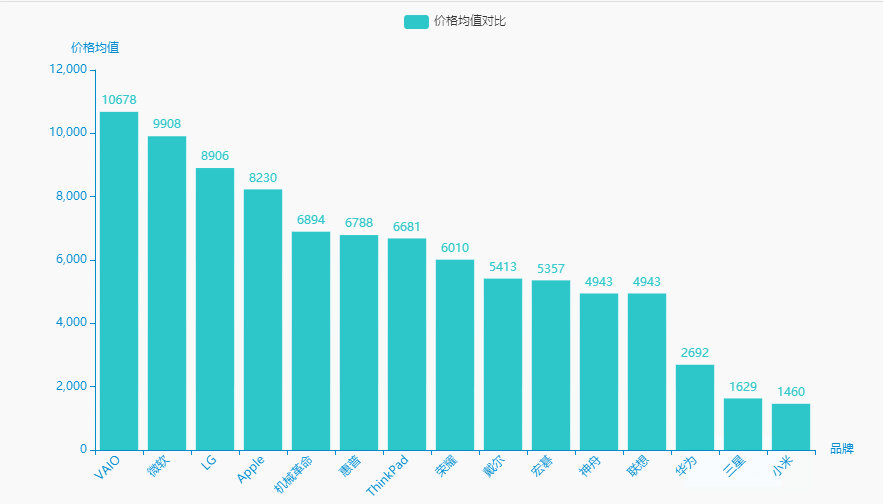
3.价格均值
统计分析
brand_meanprice = df.groupby('brand')['price'].agg(['mean'])['mean'].sort_values(ascending=False).reset_index()brand_meanprice.columns = ['品牌', '价格均值']name = (brand_meanprice['品牌']).tolist()dict_values = (brand_meanprice['价格均值']).tolist()for i in range(0, len(name)):if "(" in name[i]:name[i] = name[i][0:int(name[i].index("("))]for i in range(0, len(dict_values)):dict_values[i] = int(dict_values[i])
可视化展示
#李运辰 公众号:python爬虫数据分析挖掘# 链式调用c = (Bar(init_opts=opts.InitOpts( # 初始配置项theme=ThemeType.MACARONS,animation_opts=opts.AnimationOpts(animation_delay=1000, animation_easing="cubicOut" # 初始动画延迟和缓动效果))).add_xaxis(xaxis_data=name) # x轴.add_yaxis(series_name="价格均值对比", yaxis_data=dict_values) # y轴.set_global_opts(title_opts=opts.TitleOpts(title='', subtitle='', # 标题配置和调整位置title_textstyle_opts=opts.TextStyleOpts(font_family='SimHei', font_size=25, font_weight='bold', color='red',), pos_left="90%", pos_top="10",),xaxis_opts=opts.AxisOpts(name='品牌', axislabel_opts=opts.LabelOpts(rotate=45)),# 设置x名称和Label rotate解决标签名字过长使用yaxis_opts=opts.AxisOpts(name='价格均值'),).render("价格均值对比.html"))
4.各大品牌标题词云
提取文本
#李运辰 公众号:python爬虫数据分析挖掘brand_title = df.groupby('brand')['title']brand_title = list(brand_title)for z in range(0,len(brand_title)):brandname = brand_title[z][0]if "(" in brandname:brandname = brandname[0:int(brandname.index("("))]brandname = str(brandname).encode("utf-8").decode('utf8')print(brandname)text = "".join((brand_title[z][1]).tolist())text = text.replace(brand_title[z][0],"").replace(brandname,"").replace("\n\r","").replace("\t","").replace("\n","").replace("\r","").replace("【","").replace("】","").replace(" ","")#print(text)with open("text/"+str(brandname)+".txt","a+") as f:f.write(text)
这里将不同品牌的标题文本写入到txt
可视化展示
#李运辰 公众号:python爬虫数据分析挖掘def an4_pic():###词云图标fa_list = ['fas fa-play', 'fas fa-audio-description', 'fas fa-circle', 'fas fa-eject', 'fas fa-stop','fas fa-video', 'fas fa-volume-off', 'fas fa-truck', 'fas fa-apple-alt', 'fas fa-mountain','fas fa-tree', 'fas fa-database', 'fas fa-wifi', 'fas fa-mobile', 'fas fa-plug']z=0##开始绘图for filename in os.listdir("text"):print(filename)with open("text/"+filename,"r") as f:text = (f.readlines())[0]with open("stopword.txt", "r", encoding='UTF-8') as f:stopword = f.readlines()for i in stopword:print(i)i = str(i).replace("\r\n", "").replace("\r", "").replace("\n", "")text = text.replace(i, "")word_list = jieba.cut(text)result = " ".join(word_list) # 分词用 隔开# 制作中文云词icon_name = str(fa_list[z])gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc',output_name=str(filename.replace(".txt",""))+"词云图.png") # 必须加中文字体,否则格式错误z =z+1
















04
总结
1.讲解了如何用python爬取『各种品牌』笔记本电脑数据。
2.利用pandas对excel数据进行统计分析。
3.对统计数据进行动图展示,以及绘制各种精美词云图。
4.如果大家本文有什么地方不明白的可以在下方留言或者下方扫码观看本文代码讲解(手撕过程)
如果大家对本文代码源码感兴趣,点击下放名片关注后,回复:笔记本分析 ,获取完整代码!
如果大家想加群学习,后台点击:加群交流
推荐阅读
扫码回复「大礼包」后获取大礼


