
【深度学习】你心目中 idea 最惊艳的深度学习领域论文是哪篇?
共 3564字,需浏览 8分钟
· 2021-03-08
科研路上我们往往会读到让自己觉得想法很惊艳的论文,心中对不同的论文也会有一个排名。
我们来看看各路大神是怎么评价的。


论文链接 https://arxiv.org/abs/1410.3916
关于计算机视觉领域,@taokongcn分享了几个重要的工作。
1. Fully Convolutional Networks for Semantic Segmentation
论文链接 https://arxiv.org/abs/1411.4038
全卷积神经网络FCN:相信做物体识别检测分割的同学都非常熟悉这个工作,可以看作是开启和奠定了用FCN做实例和像素级别理解的一系列方法的先河,思想非常简单:直接端到端利用全卷积网络预测每个位置的标签。后续非常多的方法,包括Mask R-CNN、各种单阶段检测器、包括3D、video的诸多方法均或多或少受此简单想法的启发。
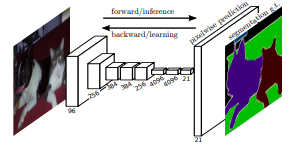
2. Faster R-CNN
论文链接 https://arxiv.org/abs/1506.01497
Faster R-CNN:现在回想起来,能在2015年想到Anchor这个想法真的是一个跨时代的,这个思想虽然简单但影响到了几乎所有的实例级别的理解任务。不多说,懂得都懂。
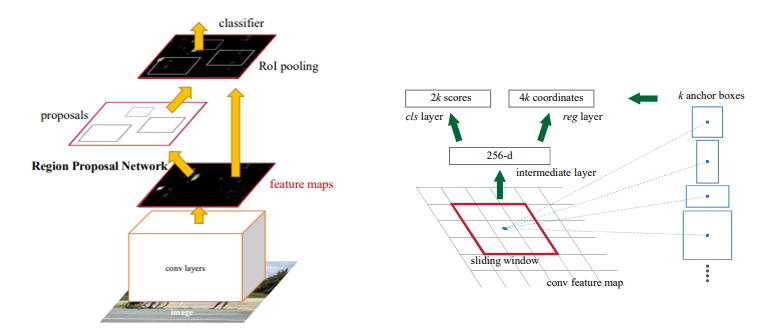
3. Deformable Convolutional Networks
https://openaccess.thecvf.com/content_iccv_2017/html/Dai_Deformable_Convolutional_Networks_ICCV_2017_paper.html
可形变卷积DCN:通过简单的offset学习和变换,赋予了卷积神经网络更加可形变的能力,想法很简单很work,目前已经成为各种打比赛的涨点神器。
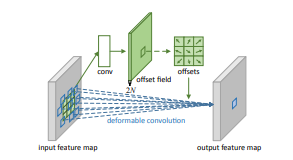
复旦大学硕士生@陀飞轮:当年看Deformable Convolutional Networks(DCN)的时候最为惊艳,可能看过的文章少,这种打破固定尺寸和位置的卷积方式,让我感觉非常惊叹,网络怎么能够在没有直接监督的情况下,学习到不同位置的offset的,然后可视化出来,能够使得offset后的位置能够刚好捕捉到不同尺寸的物体,太精彩了!

4. CAM: Learning Deep Features for Discriminative Localization
论文链接 https://www.cv-foundation.org/openaccess/content_cvpr_2016/html/Zhou_Learning_Deep_Features_CVPR_2016_paper.html
CAM@周博磊老师代表工作之一,如何用已有的分类网络去做定位?思想极为简单但有效:将最后一层的权重与对应特征层加权。目前几乎所有做图像弱监督定位分割的工作均或多或少吸收此思想,影响深远。
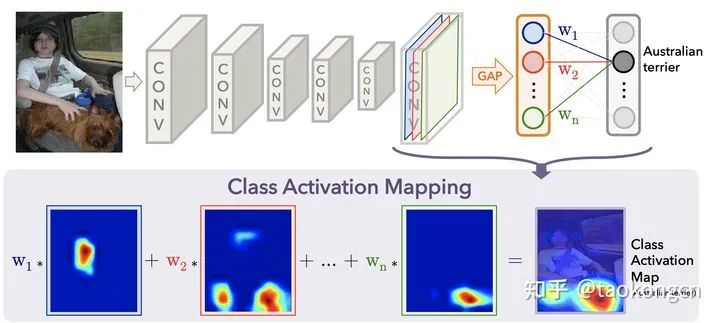
对你没有看错,图像关注的部分就是将该类的fc层中的权重和feature maps对应加权求和就行了。。。说实话我觉得这个真的是经过很多实验才发现的idea。因此通过这个CAM我们便可知这个网络到底在学什么东西。
至于后面CAM变体例如grad-cam等大家可以去查阅了解。通过这个惊艳的CAM,我觉得是开了基于弱监督图像分割领域的先河,简直是祖先级别的神工作。
为什么这么说呢,基于image-level的弱监督分割旨在仅通过分类标签而生成对应的分割标签图,(毕竟手工标记分割图上的像素太烧钱了呀哈哈哈 )你看看CAM,如果通过阈值一下的话,那些热点处的不就可以作为置信度高的前景像素标签了嘛!!!
于是你便可以看到大量的弱监督领域分割之作都是在这个CAM之上完成的。不仅如此,CAM也在可解释领域中被作为一种基本的工具。这篇五年前的文章至今仍在视觉领域中放光发热,让很多的学者以此为基石展开研究。
我也是很感谢这篇工作让我接触到弱监督领域。毕竟是我转做计算机视觉读的第一篇文章hhhh,所以,thank you, CAM!

5. CLIP: Learning Transferable Visual Models From Natural Language Supervision
论文链接 https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf
跨语言-图像的预训练是很多人都能想到的idea,但是一直效果不够。这个工作体现出了作者们极度的自信和能力,竟然收集了大量大量大量的paired数据真正做work了!感觉自己做的工作就是渣渣,,,
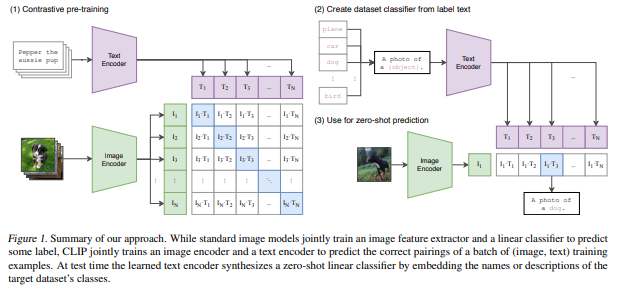
知乎上@王峰提出了一个非常好的图示:
人脸识别方面,ECCV16的Center Loss和ICML16的Large Margin Softmax(是同一波人做的)。
个人认为这两篇文章最惊艳的地方并不在于方法,而在于分析问题的方式,尤其是这张图:
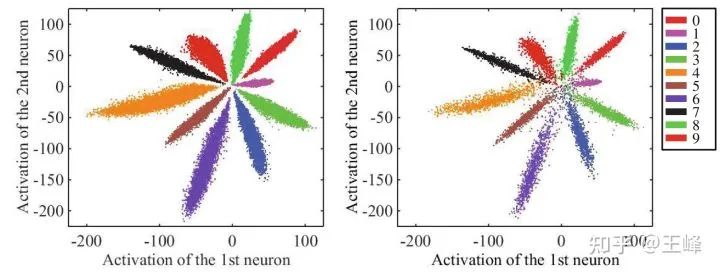
之前人们并不是没有研究过特征分布,但是用的方法都还是传统的一些降维手段如t-SNE,但t-SNE毕竟是个非线性降维方法,并不能真实地表现出原始特征分布。
实际上神经网络自己就是一个非常好的降维工具,直接将fc层的输出维度设置为2,那么每个样本的特征就只有两维,可以直接画在一个平面上,得到的可视化图像就是真正的特征分布。
有了这个可视化手段,人们发现原来softmax loss训练出来的特征是这样一个放射型分布,类与类之间是按角度分隔开的,于是才有了后续一系列工作关于角度的分析。
时至今日,这两个算法已经被更好的算法取代了,但分析问题的方式一直延续至今都还在被广泛使用。
@rainy分享了一篇小众方向(视频增稳/Video Stabilization)的论文,可能不是那种推动领域进步的爆炸性工作,这篇论文我认为是一篇比较不错的把传统方法deep化的工作。
论文链接 https://arxiv.org/pdf/2011.14574.pdf
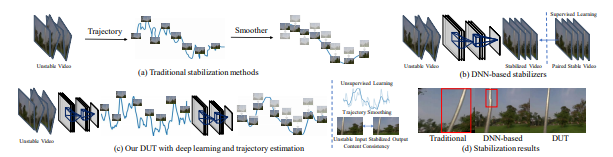
看样子应该是投稿CVPR21,已开源。
论文链接 https://github.com/Annbless/DUTCode
首先介绍一下视频增稳的定义,如名称所示,视频增稳即为输入一系列连续的,非平稳(抖动较大)的视频帧,输出一系列连续的,平稳的视频帧。
由于方向有点略微小众,因此该领域之前的工作(基于深度学习)可以简单分为基于GAN的直接生成,基于光流的warp,基于插帧(其实也是基于光流的warp)这么几类。这些论文将视频增稳看做了“视频帧生成问题”,但是理想的视频增稳工作应该看做“轨迹平滑”问题更为合适。
而在深度学习之前刘帅成大神做了一系列的视频增稳的工作,其中work的即为meshflow。这里贴一个meshflow解读的链接。(论文链接https://www.yuque.com/u452427/ling/qs0inc)
总结一下,meshflow主要的流程为“估计光流-->估计关键点并筛选出关键点的光流-->基于关键点光流得到mesh中每一个格点的motion/轨迹-->进行轨迹平滑并得到平滑后的轨迹/每一个格点的motion-->基于motion得到满足平滑轨迹的视频帧”。
总结了meshflow之后,这篇DUT主要进行的工作其实很简单,在meshflow的框架下,将其中所有的模块都deep化:
LK光流---->PWCNet
SIFT关键点----->RFNet
基于Median Filters的轨迹平滑------>可学习的1D卷积
除此之外,由于原始的meshflow是基于优化的方法,因此DUT在替换了模块之后依旧保留了原始的约束项,并且可以使用无监督的方式完成训练,效果也好于一票supervised的方法。
迈微推荐
看了很多大牛的推荐,经过个人思考后,迈微也整理了详细的论文推荐名单。
免费下载链接:https://github.com/Charmve/PaperWeeklyAI
之前分享的这几篇也给出了必读论文篇目及下载链接。
往期精彩回顾
本站qq群704220115,加入微信群请扫码: