
没想到吧?这货比 open 更适合读取文件!
共 7415字,需浏览 15分钟
· 2021-03-04

这是「进击的Coder」的第 357 篇技术分享作者:写代码的明哥来源:Python 编程时光
“
阅读本文大概需要 17 分钟。
使用 open 函数去读取文件,似乎是所有 Python 工程师的共识。
今天要给大家推荐一个比 open 更好用、更优雅的读取文件方法 -- 使用
fileinput fileinput 是 Python 的内置模块,但我相信,不少人对它都是陌生的。今天我把 fileinput 的所有的用法、功能进行详细的讲解,并列举了一些非常实用的案例,对于理解和使用它可以说完全没有问题。1. 从标准输入中读取
当你的 Python 脚本没有传入任何参数时,fileinput 默认会以 stdin 作为输入源# demo.py效果如下,不管你输入什么,程序会自动读取并再打印一次,像个复读机似的。
import fileinput
for line in fileinput.input():
print(line)
$ python demo.py
hello
hello
python
python
2. 单独打开一个文件
单独打开一个文件,只需要在 files 中输入一个文件名即可import fileinput其中
with fileinput.input(files=('a.txt',)) as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
a.txt 的内容如下hello执行后就会输出如下
world
$ python demo.py需要说明的一点是,
a.txt 第1行: hello
a.txt 第2行: world
fileinput.input() 默认使用 mode='r' 的模式读取文件,如果你的文件是二进制的,可以使用mode='rb' 模式。fileinput 有且仅有这两种读取模式。3. 批量打开多个文件
从上面的例子也可以看到,我在fileinput.input 函数中传入了 files 参数,它接收一个包含多个文件名的列表或元组,传入一个就是读取一个文件,传入多件就是读取多个文件。import fileinput
with fileinput.input(files=('a.txt', 'b.txt')) as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
a.txt 和 b.txt 的内容分别是$ cat a.txt运行后输出结果如下,由于
hello
world
$ cat b.txt
hello
python
a.txt 和 b.txt 的内容被整合成一个文件对象 file ,因此 fileinput.lineno() 只有在读取一个文件时,才是原文件中真实的行号。$ python demo.py如果想要在读取多个文件的时候,也能读取原文件的真实行号,可以使用
a.txt 第1行: hello
a.txt 第2行: world
b.txt 第3行: hello
b.txt 第4行: python
fileinput.filelineno() 方法import fileinput运行后,输出如下
with fileinput.input(files=('a.txt', 'b.txt')) as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.filelineno()}行: {line}', end='')
$ python demo.py这个用法和 glob 模块简直是绝配
a.txt 第1行: hello
a.txt 第2行: world
b.txt 第1行: hello
b.txt 第2行: python
import fileinput运行效果如下
import glob
for line in fileinput.input(glob.glob("*.txt")):
if fileinput.isfirstline():
print('-'*20, f'Reading {fileinput.filename()}...', '-'*20)
print(str(fileinput.lineno()) + ': ' + line.upper(), end="")
$ python demo.py
-------------------- Reading b.txt... --------------------
1: HELLO
2: PYTHON
-------------------- Reading a.txt... --------------------
3: HELLO
4: WORLD
4. 读取的同时备份文件
fileinput.input 有一个 backup 参数,你可以指定备份的后缀名,比如 .bakimport fileinput运行的结果如下,会多出一个
with fileinput.input(files=("a.txt",), backup=".bak") as file:
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
a.txt.bak 文件$ ls -l a.txt*
-rw-r--r-- 1 MING staff 12 2 27 10:43 a.txt
$ python demo.py
a.txt 第1行: hello
a.txt 第2行: world
$ ls -l a.txt*
-rw-r--r-- 1 MING staff 12 2 27 10:43 a.txt
-rw-r--r-- 1 MING staff 42 2 27 10:39 a.txt.bak
5. 标准输出重定向替换
fileinput.input 有一个 inplace 参数,表示是否将标准输出的结果写回文件,默认不取代请看如下一段测试代码import fileinput运行后,会发现在 for 循环体内的 print 内容会写回到原文件中了。而在 for 循环体外的 print 则没有变化。
with fileinput.input(files=("a.txt",), inplace=True) as file:
print("[INFO] task is started...")
for line in file:
print(f'{fileinput.filename()} 第{fileinput.lineno()}行: {line}', end='')
print("[INFO] task is closed...")
$ cat a.txt利用这个机制,可以很容易的实现文本替换。
hello
world
$ python demo.py
[INFO] task is started...
[INFO] task is closed...
$ cat a.txt
a.txt 第1行: hello
a.txt 第2行: world
import sys附:如何实现 DOS 和 UNIX 格式互换以供程序测试,使用 vim 输入如下指令即可
import fileinput
for line in fileinput.input(files=('a.txt', ), inplace=True):
#将Windows/DOS格式下的文本文件转为Linux的文件
if line[-2:] == "\r\n":
line = line + "\n"
sys.stdout.write(line)
DOS转UNIX::setfileformat=unix
UNIX转DOS::setfileformat=dos
6. 不得不介绍的方法
如果只是想要fileinput 当做是替代 open 读取文件的工具,那么以上的内容足以满足你的要求。fileinput.filenam()
返回当前被读取的文件名。在第一行被读取之前,返回None。fileinput.fileno()
返回以整数表示的当前文件“文件描述符”。当未打开文件时(处在第一行和文件之间),返回-1。fileinput.lineno()
返回已被读取的累计行号。在第一行被读取之前,返回0。在最后一个文件的最后一行被读取之后,返回该行的行号。fileinput.filelineno()
返回当前文件中的行号。在第一行被读取之前,返回0。在最后一个文件的最后一行被读取之后,返回此文件中该行的行号。
fileinput.isfirstline()
如果刚读取的行是其所在文件的第一行则返回True,否则返回False。fileinput.isstdin()
如果最后读取的行来自sys.stdin则返回True,否则返回False。fileinput.nextfile()
关闭当前文件以使下次迭代将从下一个文件(如果存在)读取第一行;不是从该文件读取的行将不会被计入累计行数。直到下一个文件的第一行被读取之后文件名才会改变。在第一行被读取之前,此函数将不会生效;它不能被用来跳过第一个文件。在最后一个文件的最后一行被读取之后,此函数将不再生效。fileinput.close()
关闭序列。
7. 进阶一点的玩法
在fileinput.input() 中有一个 openhook 的参数,它支持用户传入自定义的对象读取方法。若你没有传入任何的勾子,fileinput 默认使用的是 open 函数。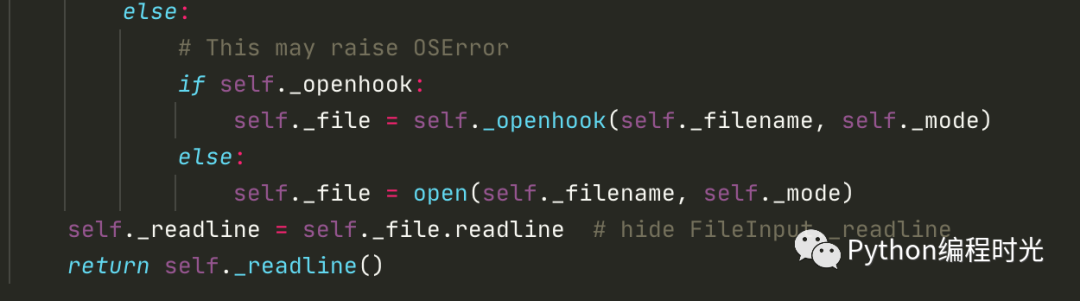
fileinput 为我们内置了两种勾子供你使用fileinput.hook_compressed(*filename*, *mode*)使用
gzip和bz2模块透明地打开 gzip 和 bzip2 压缩的文件(通过扩展名'.gz'和'.bz2'来识别)。如果文件扩展名不是'.gz'或'.bz2',文件会以正常方式打开(即使用open()并且不带任何解压操作)。使用示例:fi = fileinput.FileInput(openhook=fileinput.hook_compressed)fileinput.hook_encoded(*encoding*, *errors=None*)返回一个通过
open()打开每个文件的钩子,使用给定的 encoding 和 errors 来读取文件。使用示例:fi = fileinput.FileInput(openhook=fileinput.hook_encoded("utf-8", "surrogateescape"))
先使用 requests 下载文件到本地
再使用 open 去读取它
def online_open(url, mode):直接将这个函数传给 openhook 即可
import requests
r = requests.get(url)
filename = url.split("/")[-1]
with open(filename,'w') as f1:
f1.write(r.content.decode("utf-8"))
f2 = open(filename,'r')
return f2
import fileinput运行后按预期一样将 CSDN 的 robots 的文件打印了出来
file_url = 'https://www.csdn.net/robots.txt'
with fileinput.input(files=(file_url,), openhook=online_open) as file:
for line in file:
print(line, end="")
User-agent: *
Disallow: /scripts
Disallow: /public
Disallow: /css/
Disallow: /images/
Disallow: /content/
Disallow: /ui/
Disallow: /js/
Disallow: /scripts/
Disallow: /article_preview.html*
Disallow: /tag/
Disallow: /*?*
Disallow: /link/
Sitemap: https://www.csdn.net/sitemap-aggpage-index.xml
Sitemap: https://www.csdn.net/article/sitemap.txt
8. 列举一些实用案例
案例一:读取一个文件所有行import fileinput案例二:读取多个文件所有行
for line in fileinput.input('data.txt'):
print(line, end="")
import fileinput案例三:利用fileinput将CRLF文件转为LF
import glob
for line in fileinput.input(glob.glob("*.txt")):
if fileinput.isfirstline():
print('-'*20, f'Reading {fileinput.filename()}...', '-'*20)
print(str(fileinput.lineno()) + ': ' + line.upper(), end="")
import sys案例四:配合 re 做日志分析:取所有含日期的行
import fileinput
for line in fileinput.input(files=('a.txt', ), inplace=True):
#将Windows/DOS格式下的文本文件转为Linux的文件
if line[-2:] == "\r\n":
line = line + "\n"
sys.stdout.write(line)
#--样本文件--:error.log案例五:利用fileinput实现类似于grep的功能
aaa
1970-01-01 13:45:30 Error: **** Due to System Disk spacke not enough...
bbb
1970-01-02 10:20:30 Error: **** Due to System Out of Memory...
ccc
#---测试脚本---
import re
import fileinput
import sys
pattern = '\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}'
for line in fileinput.input('error.log',backup='.bak',inplace=1):
if re.search(pattern,line):
sys.stdout.write("=> ")
sys.stdout.write(line)
#---测试结果---
=> 1970-01-01 13:45:30 Error: **** Due to System Disk spacke not enough...
=> 1970-01-02 10:20:30 Error: **** Due to System Out of Memory...
import sys
import re
import fileinput
pattern= re.compile(sys.argv[1])
for line in fileinput.input(sys.argv[2]):
if pattern.match(line):
print(fileinput.filename(), fileinput.filelineno(), line)
$ ./demo.py import.*re *.py
#查找所有py文件中,含import re字样的
addressBook.py 2 import re
addressBook1.py 10 import re
addressBook2.py 18 import re
test.py 238 import re
9. 写在最后
fileinput 是对 open 函数的再次封装,在仅需读取数据的场景中, fileinput 显然比 open 做得更专业、更人性,当然在其他有写操作的复杂场景中,fileinput 就无能为力啦,本身从 fileinput 的命名上就知道这个模块只专注于输入(读)而不是输出(写)。
End
「进击的Coder」专属学习群已正式成立,搜索「CQCcqc4」添加崔庆才的个人微信或者扫描下方二维码拉您入群交流学习。
及时收看更多好文
↓↓↓
赶紧试一试
