 小白学视觉
小白学视觉




点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


视频和语言学习(例如,视频问答)的规范方法规定了一个神经模型,该模型可以从脱机提取的视觉模型中的密集视频特征和语言模型中的文本特征中学习。这些特征提取器是独立训练的,通常用于不同于目标域的任务,使得这些固定的特征对于下游任务来说不是最优的。此外,由于密集视频特征的高计算过载,通常很难(或不可行)将特征提取器直接插入现有方法中以便进行微调。为了解决这一难题,作者提出了一个通用框架CLIPBERT,该框架通过使用稀疏采样,在每个训练步骤中只使用一个或几个稀疏采样的视频短片段,从而为视频和语言任务提供了负担得起的端到端学习。实验text-to-video检索和视频问答6个数据证明CLIPBERT优于与(或)现有的方法,利用完整的视频,这表明端到端学习几个稀疏采样剪辑往往比使用更精确的人口从完整的视频中提取离线特性,证明了众所周知的less-is-more原则。数据集中的视频来自不同的领域和长度,从3秒的通用域GIF视频到180秒的YouTube人类活动视频,显示了作者方法的泛化能力。提供了全面的消融研究和彻底的分析,以剖析导致这种成功的因素。
代码链接:https://github.com/jayleicn/ClipBERT
作者的贡献有三方面:
(i)作者提出了CLIPBERT,一种新的端到端学习框架,用于视频+语言任务。实验表明,在不同的视频文本任务(平均视频长度从几秒到三分钟不等)中,CLIPBERT获得了优于现有方法的性能。
(ii)作者的研究表明,少即是多:提出的端到端训练策略使用单个或几个(较少)稀疏采样的视频片段通常比使用密集提取视频特征的传统方法更精确。
(iii)作者证明了图像-文本预训练有利于视频-文本任务。作者还提供了全面的消融研究,揭示了导致CLIPBERT成功的关键因素,以期启发更多的未来工作。
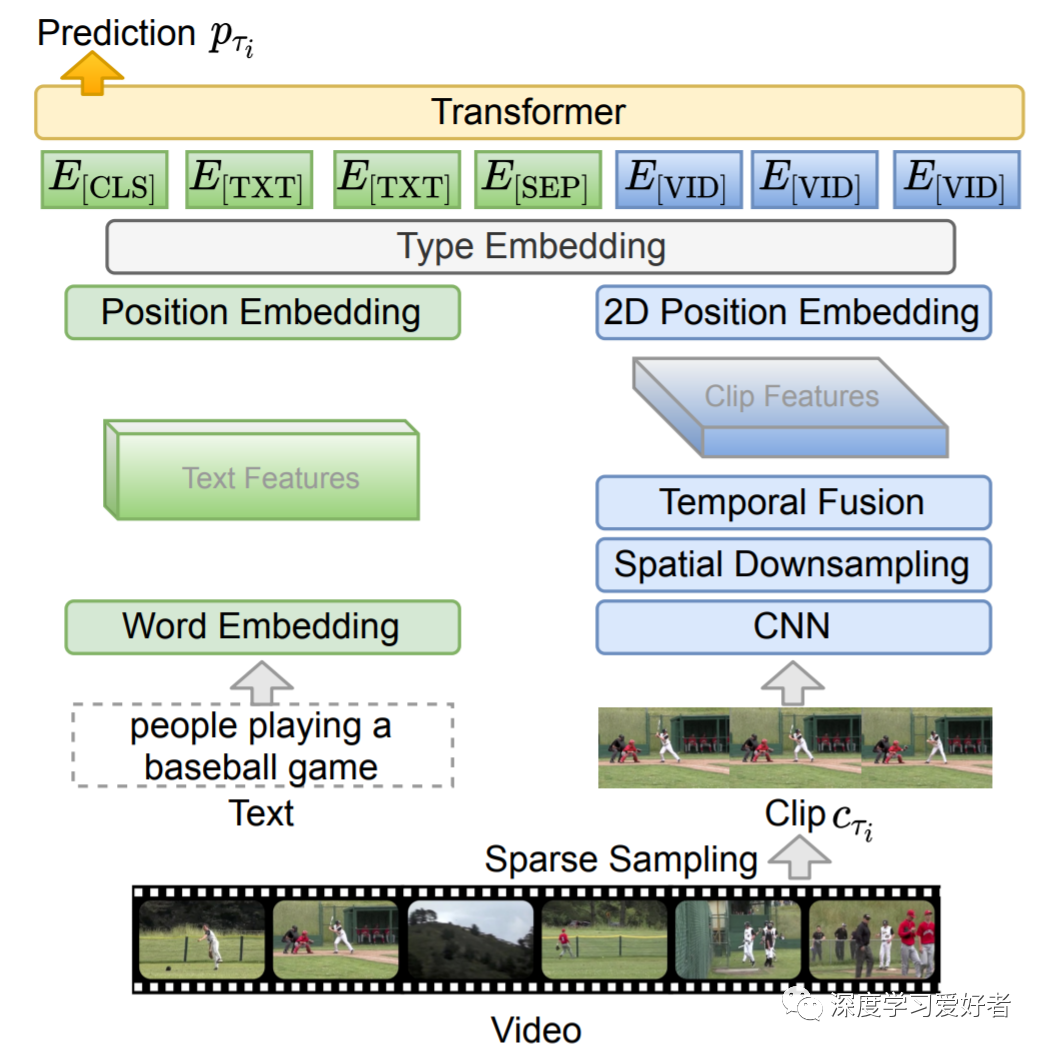
CLIPBERT架构概述。为简单起见,作者只展示了对单个采样剪辑产生预测的示例。当使用多个剪辑时,他们的预测融合在一起作为最终预测。

作者提出了一种端到端视频和语言学习的通用框架CLIPBERT,该框架采用稀疏采样,在每个训练步骤中只使用少量采样的视频短片段。在不同的任务中进行的实验表明,CLIPBERT的性能优于(或与)最先进的方法,具有密集的离线采样特征,这表明少即是多的原则在实践中是非常有效的。综合消融研究揭示了导致这种成功的几个关键因素,包括稀疏采样、端到端训练和图像-文本预训练。
论文链接:https://arxiv.org/pdf/2102.06183.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~



