 机器学习算法工程师
机器学习算法工程师




 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
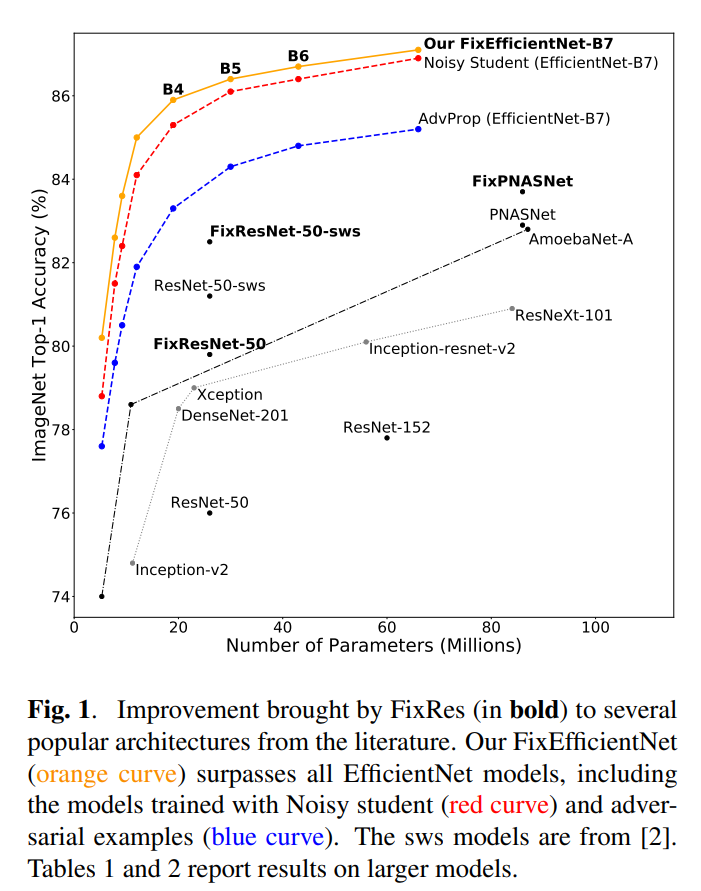
FixRes是Facebook在19年提出的一个应用于图像分类的简单优化策略,论文名是Fixing the train-test resolution discrepancy,在这篇论文中作者发现了在ImageNet数据集上的分类模型中常采用的数据增强会导致训练和测试时的物体分辨率(resolution)不一致,继而提出FixRes策略来改善这个问题:常规训练后再采用更大的分辨率对模型的classifier或最后的几层layers进行finetune。利用FixRes这个简单的策略对ImageNet数据集上的SOTA进行优化,FixRes都达到了更高的accuracy:
FixResNeXt-101 32x48d(224训练,320测试):top-1 acc达到86.4%,超过ResNeXt-101 32x48d所达到的85.4%; FixEfficientNet-L2(475训练,600测试):top-1 acc达到88.5%,超过Noisy Student Training (L2)所达到的88.4%;
首先,问题的所在是在ImageNet图像分类中会采用random size的数据增强,这是因为CNN虽然具有translation invariance,但是并不具有scale invariance,那么就需要通过数据增强来让模型学习到这种特性。以torchvision官方代码为例,训练ImageNet的数据预处理如下所示:
# 训练
dataset = torchvision.datasets.ImageFolder(
traindir,
transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
]))
# 测试
dataset_test = torchvision.datasets.ImageFolder(
valdir,
transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
]))
可以看到训练和测试的数据预处理流程并不一样,在训练时,主要的数据增强是通过transforms.RandomResizedCrop来完成:从输入图像随机选择一块矩形区域(Region of Classification, RoC),然后resize到固定大小(224),scale参数控制RoC的变化范围,这样训练过程模型学习到不同scale的物体。在测试过程中,是直接将图像resize到一个固定大小(256,Resize最短边为256),然后从中间区域center crop一个固定大小的图像块(224)。模型在训练和测试时图像的输入大小均为224,但是由于训练和测试时的处理流程不同,实际上物体的分辨率并不匹配,如下图所示,可以明显看到虽然训练和测试时的输入大小均为224,但是训练图像中物体(这里是牛)的分辨率明显比测试图像中高。虽然训练过程中的随机scale可以让模型学习到scale invariance能力,但是如果测试时的分辨率可以接近训练过程中的平均分辨率,那么理论效果是最好的。下面我们从理论上计算一下训练和物体的分辨率的差异。

首先假定原始图像(大小为)中物体的分辨率是大小(像素点),如果对图像进行缩放,那么物体的大小将变为。这里先来分析训练过程,对于transforms.RandomResizedCrop函数,其主要有两个参数来控制RoC的生成,第一个是缩放参数,这里满足(默认参数为),另外一个参数是长宽比系数,其满足(默认参数为)。这里忽略长宽比系数,那么RoC的大小。然后将RoC直接resize到 大小(非同比例resize),这里的缩放因子为。如果输入图像是正方形大小(W=H),那么训练过程中的缩放比例为。所以训练输入的物体大小为:
测试过程中图像处理方式和训练过程不同,首先是将输入图像resize到(这里是同比例resize,这样最短边保证为这个大小),然后从中间区域crop出大小区域作为测试图像输入模型。这样测试过程中缩放比例为。那么测试时输入的物体大小就变为:
那么训练和测试时物体分辨率比值为:
这里是固定值,而的平方满足均匀分布(0.08,1.0),这里我们计算期望值:
所以从理论上讲,训练时的输入物体的分辨率要高于测试时,那么要达到两者较好的比配,就需要增加测试时输入分辨率,如果直接增加(按理论计算需要增加1/0.8=1.25)但是依然保持,虽然输入的分辨率提高了,但是crop的区域少了,可能物体的边缘部分丢失了,所以理想的方法是同比例增加和。论文中用ResNet50做了实验(训练224不变,但是改变测试时size),结果如下表所示:

可以看到时ResNet50取得了78.4%的acc,比原始的224效果要好。注意这里的size都是32的倍数(分类CNN的stride都是32),具体可以看附录B。另外这里也看到,持续增大size,其实acc反而有所下降,说明分辨率并不是越大越好,而要和训练size匹配好。
当输入size发生变化后,我们还要考虑对模型输出的影响。由于模型的卷积部分对输入变化是适应的,就是说改变输入大小,并不会改变卷积部分的感受野,但是卷积得到的特征图大小是不同的,特征图会经过global average pooling后送入classifier。特征图的改变会直接影响pooling得到的特征分布,这将会给后面的分类器带来影响,这是论文的第二点重要的部分。下图给出了不同test size下的ResNet50的pooling后特征的累积分布函数(Cumulative Distribution Function),可以看到当test size较小时,特征更容易稀疏化,时为0的比重占29.8%,而时为0的比重占0.5%,这不难理解,前者的特征图大小只有2x2,而后者的特征图大小为7x7,经过pooling后前者更可能出现0。这说明不同的size输入会直接改变特征分布。
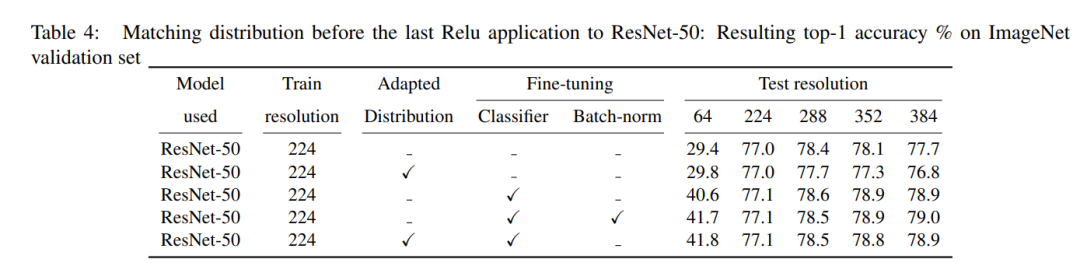
解决办法就是对特征进行校正,论文里面给出了两种解决方案。第一个方法是采用建模的方法进行Parametric adaptation,但是效果并不佳。这里重点是第二种方案,那就是通过fine-tunng的方法来校正特征分布,但是这里的finetune只限于最后的分类器以及pooling之前的BN层就足够了,在finetune时输入的size由切换到。至于数据增强,论文中共尝试了三种方法:
test DA:和test阶段一样的数据增强,resizing the image and then take the center crop; test DA2:相比test DA增加了更多的增强, resizing the image, random horizontal shift of the center crop, horizontal flip and color jittering; train DA:和train阶段一样的数据增强
从论文的结果来看,三种方法的结果是接近的,默认采用test DA是最简单的,test DA2的结果要稍微好一点点。最终在ResNet50的结果如下所示,可以看到在224训练,采用384进行finetune,Top-1 acc从77%提升至79%。
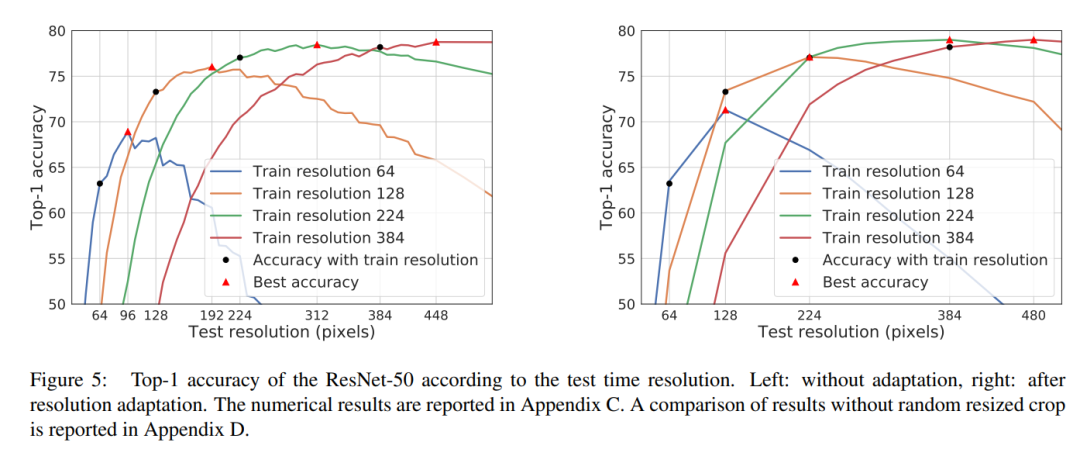
另外论文中还对不同的train size以及test size做了详细地实验,如下图所示(右图是finetune后的结果),不如当采用128训练时,然后采用224进行finetune,Top-1 Acc可达77.1%,这超过了原始的ResNet50的224训练结果,但采用128训练成本更低。
靠着FixRes这个简单的技巧,Facebook分别两次超越ImageNet数据集上的SOTA:FixResNeXt-101 32x48d(224训练,320测试),top-1 acc达到86.4%;FixEfficientNet-L2(475训练,600测试),top-1 acc达到88.5%。
最后简单总结一个FixRes:
FixRes is a very simple fine-tuning that re-trains the classifier or a few top layers at the target (higher) resolution.
开源代码地址:https://github.com/facebookresearch/FixRes.
参考
Fixing the train-test resolution discrepancy Fixing the train-test resolution discrepancy: FixEfficientNet

推荐阅读
CondInst:性能和速度均超越Mask RCNN的实例分割模型
mmdetection最小复刻版(十一):概率Anchor分配机制PAA深入分析
MMDetection新版本V2.7发布,支持DETR,还有YOLOV4在路上!
无需tricks,知识蒸馏提升ResNet50在ImageNet上准确度至80%+
不妨试试MoCo,来替换ImageNet上pretrain模型!
mmdetection最小复刻版(七):anchor-base和anchor-free差异分析
mmdetection最小复刻版(四):独家yolo转化内幕
机器学习算法工程师
一个用心的公众号



