大数据文摘授权转载自AI科技评论
大数据文摘授权转载自AI科技评论
作者 | Mihail Eric
编译 | Don
近些年来,我都在数据科学和机器学习人力市场的风口浪尖进行研究,我尝试用我的研究回答一些问题,就是市场上到底需要什么样的数据科学相关人才。
通过分析Y-Combinator 发布的2012年来各家公司数据相关工作岗位的招聘信息(大约1400家公司),我发现在各大公司的招聘需求中,数据工程师的需求量要远远大于数据科学家的需求量。数据是人工智能之本。数据源于生活,我们的举手投足都能映射成一段段奇妙的样本,它会随着人们生活的继续和传感器的采集而不断增加。海量的数据让机器越来越理解人类,认识万物。在过去的5到10年间,数据的巨量增加让这种现象愈发明显,也正因为此,数据科学领域吸引了大量的科学家和小白投身其中,尝试这种由海量数据带来的"禁果"。那就不禁让我们好奇了,如今随着大量科研和开发人员涌入数据科学应聘市场,数据科学相关岗位的招聘需求行情如何呢?为了不耽误各位童鞋宝贵的时间,我们简练滴总结了最终的结论:一句话总结:在各大公司的招聘中,数据工程领域的岗位需求比数据科学高出了70%!因此,各位童鞋和老师请注意,我们在教育或者成为下一代的数据科学相关从业者的漫漫长征路上,不要一味的追求学术成就,更要注重培养工程技能。作为一名数据科学教育平台的开发者,我十分关注学员们的就业情况。同样的,我也深刻思考了数据驱动相关领域(也就是数据科学和机器学习)的人力需求是如何演化的。我曾经和数十位数据分析领域的从业者进行了深入交流,其中不乏世界顶尖院校的高材生。在交流的过程中我逐渐产生了一个巨大的疑惑,就是到底什么技能才能给我们的从业者"镀金"?哪些技能会让我们的学员在愈来愈多的相关从业者中脱颖而出,从而为自己步入职场做好重要的准备。那到底需要哪些职业数据科学相关的技能呢?我觉得只要和以下关键词沾边即可:机器学习建模,可视化,数据清洗和处理(即SQL争用),工程和生产部署。那作为一个初次接触数据科学的小白同学来说,有什么入门的学习课程和学习路径推荐吗?数据胜于雄辩,讲了半天的大道理可能都不如一篇朴实无华的数据分析更有说服力。所以我对Y-Combinator自2012年以来的每家公司招聘的数据科学相关招聘需求进行了分析和统计,力求回答如下的问题:- 大公司们聘用的数据科学相关从业者人员大多是去干什么的?
- 我们经常谈论的传统数据科学家到底受不受市场欢迎呢?
- 如今来说,那些开启了数据科学革命的技能之间是否相关呢?
YC投资组合公司是一家以数据为本的公司,他们号称是"将数据作为公司的价值主张",听起来很靠谱,所以我选择使用他们的统计数据作为数据支撑。
YC公司除了价值观和旗号打的响,他们还额外提供了一个用起来很方便的搜索目录,里面都是他们收录的公司数据,查找起来十分方便。此外,YC还是一个特别具有前瞻性思维的孵化器,十多年来一直在为来自世界各地的公司提供跨领域的孵化资金,成功扶持了不少新兴企业。我觉得他们能够慧眼识珠,起码不至于将一些外强中干的皮包公司收录其中。他们起码能提供一个具有代表性的样本集合来支撑我们的分析。为了收集数据,我搜集了自2012年来的每家公司的YC网页网址,目前统计了大概1400多家公司的数据。有的同学可能会问,为啥是统计2012年来的数据呢?哈哈,因为2012年是AlexNet在ImageNet比赛中大放异彩的一年。自那之后无数的数据分析公司受到了AlexNet的启发和感召,如雨后春笋一般疯狂的成立。换句话说,2012年后,AlexNet催生了一些最早的数据科学大公司。在这些最开始的大公司中,我使用关键词过滤来减少那些无关的样本干扰。主要来说,我只考虑那些用如下关键词描述的公司:包括AI, CV, NLP, 自然语言处理,计算机视觉,人工智能,机器,ML,数据。我也忽略了那些官网无法访问的公司。那肯定就有同学会怀疑了,这会不会让我们的样本集中包含大量的假阳样本?答案是肯定的。但是现在来说我更想去关注数据集的召回率,因为我在初步确定样本对象之后,会对每个网站的详细数据进行更细致的手动检查。有了这些精炼的人才需求数据库,我访问了每一家公司的网站,找到他们官网上的人才招聘的网页,关键词通常是Carrer, Jobs, 或者甚至就是这个网页链接的本身。然后我记录下其中的岗位需求名称,比如机器学习,NLP之类的,以及对应的数量。通过这样的数据收集工作,我攒到了一个样本量大约是70家不同公司的数据科学相关人才需求统计表。当然了,有的公司的网站上信息不全。通常是因为公司机密或者出于隐私保护的原因所致。所以我就只好把这些公司给略过了。还有一些公司没有公布他们的招聘需求,而是要求应聘者自己发送邮件给他们的邮箱投递简历。所以这些公司的岗位需求和数量我也无从知晓。实在没办法了,这两种公司的数据我实在是得不到,或者太费功夫了。所以他们并不在本文的分析对象之中。哦对了,本文中的大部分研究都是在2020年最后的几周中完成的,而很多公司在最近飞速发展,招聘的需求和招聘页面也会发生变化。因此我们的数据可能不是那么实时。但是即便如此,这也不会影响我们最终的结论。在深入研究结果之前,我们有必要花一些时间详细说说数据科学从业者的职位通常是干什么的。以下是本文着重研究的四个典型的职位,我们将简要的介绍他们的职责:
数据科学家,数据科学家通常需要使用统计学和机器学习中的各种技术来处理和分析数据。他们通常负责构建模型,从而研究从某些数据集中能够学到什么。科学家嘛,通常做的都是比较前沿和原型的。因此这些工作通常都不是直接落地并应用到实际产品的。也就是说不是生产级别,面向用户使用的。
数据工程师,数据工程师通常需要开发出一套鲁棒性高,扩展性强的数据处理工具或者平台。他们必须熟悉SQL,NoSQL数据库的使用和ETL管道的部署和维护。
机器学习ML工程师,机器学习工程师通常需要负责训练模型和交付模型。他们需要熟悉一些高级的ML框架,比如Tensorflow, Pytorch, ScikitLearn之类的,并且能够为模型构建伸缩性强的训练工具,方便好用的推理和部署管道。
机器学习科学家,机器学习科学家通常需要从事尖端的学术研究。他们需要负责产出可在学术会议上发表的新想法。他们可能比数据科学家更学术范儿一点儿,通常只需要在交付给机器学习工程师之前对模型粗粗的进行原型化验证即可。
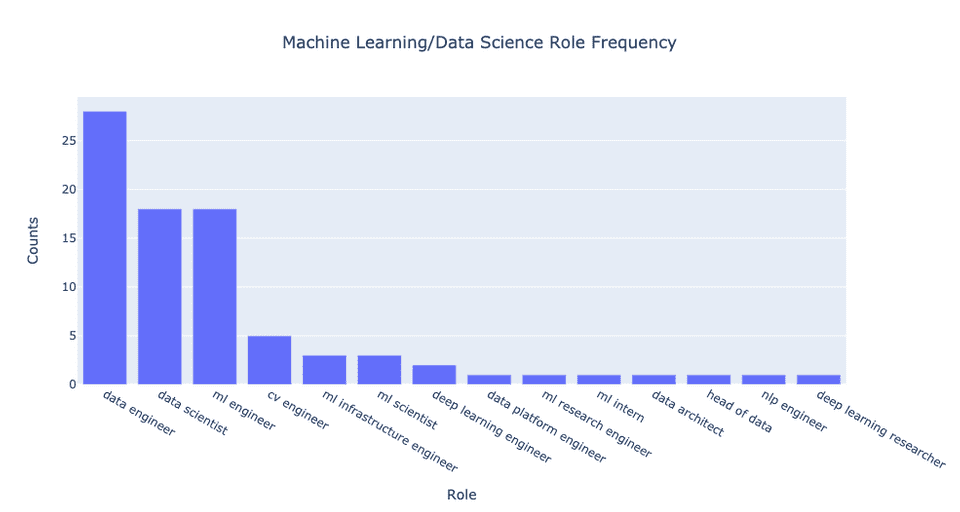
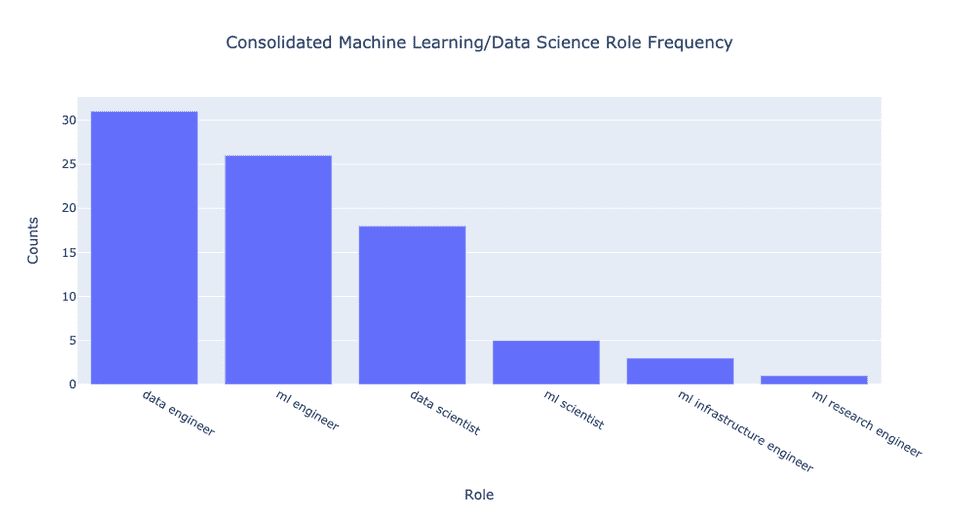
当我们将统计起来的各大公司的岗位招聘职位的频率进行统计并画出来的时候,大致结果如下:从图中,我们一眼就能发现,和传统的数据科学家相比,数据工程师的需求多了很多。在图中,数据工程师的应聘需求量比数据科学家多了大约55%,而机器学习工程师的数量与数据科学家的数量大概相同。让我们更深的剖析这个结果,如果你仔细研究每个岗位的名称,你会发现其中有些重叠。因此,如果我们"泛泛地"对职位进行归类,而不是那么精细地对岗位进行划分的话,能得到另一个更直观的结论。也就是如果我们合并同类项,将那些看似很相近的岗位作为一类的话,这种角度的分析可能给我们一个更为直观和宏观的数量对比及印象。- NLP工程师≈CV工程师≈机器学习工程师≈深度学习工程师(也许上述职位的领域稍有不同,但是这些岗位职员的工作内容是大致相同的)
- 机器学习科学家≈深度学习研究员≈机器学习实习(虽然是实习岗,但是我们会找那些实习要求中明确说明是研究相关实习的岗位)
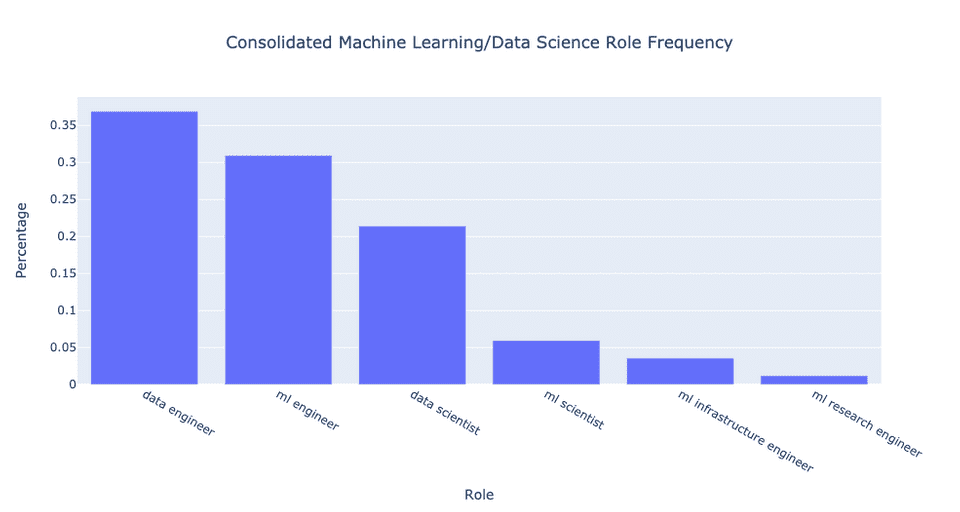
如果觉得上述的原始数据不够直观,喜欢看百分比的数据的话,请查阅下图:我们其实可以进一步把ML研究工程师归类为ML科学家或者ML工程师,但考虑到这是一个混合角色,我还是保持原样。总体来说,合并同类项的操作使得差异更加明显,也让结果更加显而易见。那就是:数据工程师的职位需求比数据科学家的职位需求多70%。此外,机器学习工程师的职位数量比数据科学家的职位数量多了大约40%。ML科学家的数量也只有数据科学家职位数量的30%。
与其他数据驱动行业相比,大公司们对数据工程师的需求越来越多。从某种意义上来说,这代表了一种趋势,也就是人们对于更泛在的ML领域的需求的增加,以及朝此方向的一种演变。
5-8年前的时候,但机器学习刚刚变得热门,各大公司觉得他们需要能够对数据进行分类的人。但是后来像Tensorflow和Pytorch这样的高级框架变得十分强大和易用的时候,大公司便增加了该方面的人力投入,于是便增加了该方向的人才需求,这就让深度学习和机器学习的需求开始增多。现如今,各大公司都手握海量数据,而如何利用好这些数据,从中挖掘出更多更有用的信息则成为了公司未来发展的核心,也成为了招聘人才的主要驱动力。如何解释数据、如何处理和清理数据、怎么把A项目的工程和经验快速迁移到B项目中,这都是大公司关心的问题,即我们应该怎么将这些琐碎的工作尽快完成。这听起来也许特别傻,特别没劲,而且一点都不酷。但实际上大公司真正需要的就是这样“老派”、“传统”而朴实的软件工程师。多年以来,我们一直被数据领域所谓的专业人士的想法所迷惑和牵引,它们凭借炫酷的PPT和媒体炒作为原始的数据注入了生机与活力。毕竟,你想想你最后一次看到TechCrunch关于ETL管道的文章是什么时候?是不是好像根本没有看到过?我相信扎实的工程能力是必需的,这也是我们在数据科学工作培训或者教育项目中所缺失的。我们除了需要学习如何调用线性回归拟合函数来训练模型之外,更要学习如何编写单元测试代码。那这是不是意味着你不应该学习数据科学了呢?答案是否定滴。这其实意味着更加激烈的市场竞争。人才市场上有着大量新兵蛋子,它们一开始就接受了数据科学科班训练,而这个领域人才越来越多,能够提供给这个领域的职位则将会越来越少。公司要的是务实,人们总是需要能够有效分析数据、并且从数据中提取有效信息的人。这些信息不必是炫酷烂漫的,但必须是有效而且好用的。如今世道变了,我们今会从Tensorflow官网上下载一个Iris数据集,然后利用已经训练好的模型跑一遍数据,这种技能模型可能已经不足以完成如今的数据科学工作了。但是很明显,随着ML工程师的大量空缺,公司通常需要一个混合数据从业者,也就是一个能够构建和部署模型的家伙。或者更简洁的说,这个人既可以使用Tensorflow训练模型,也能徒手用底层代码手撸模型。这里的另一个发现是,其实市场上并没有那么多的机器学习研究岗位需求。机器学习的研究往往有点掺水,或者说华而不实。因为学术研究嘛,比较先锋,这是所有所谓尖端的东西产生的地方,它们是否真正适用于商用还是有待商榷的。比如什么AlphaGo和GPT-3之类的炫技操作。但是对于很多公司来说,尤其是那些早期公司,这么先锋的技术可能不是真正需要的。对于他们,获得一个90%成功但是可以扩展到1000多个用户的模型通常更有价值。因为你可能会在一些大型的研究所、实验室中发现特别特别多的数据科学家的岗位需求。这些实验室就是大公司或者研究所用来秀肌肉的,他们有能力长期投入大量的科研经费,保证他们能够在该领域的曝光度和话语权。其实还有个重要的原因,就是尖端技术能产生意想不到的收益,因为一个看起来特别炫酷,别人短时间之内还难以追上的技术能够产生一系列A股公司。如果没有其他问题的话,我觉得让新来的童鞋们对数据领域有一个大致的了解,知道这个领域就业的需求和前景还是有必要的。我们必须承认,数据科学现在不同了。我希望这篇文章能对大家有所帮助。只有当我们知道我们在哪里,我们才知道我们要去哪里。没错没错。我们公司刚刚招聘了一名研究生,在公司收到的简历情况上来看,数据科学家岗位的申请人数起码是数据工程师的15倍!公司的面试官们,你们在招聘研究生毕业的数据工程师时主要看中他们的什么技能呀?看过这篇文章,我觉得对于一个毕业生来说,能做到文中这些技能的积累着实有点困难。因为我们的教育都是跟着导师或者教学规划走的,没有那么多直接面向职位招聘的教育途径和实践机会。换句话说,我们都是导师项目的工程师,我们读研读博的目的并不是找工作。面试的时候,对于投简历的毕业生小白们,我希望它们能够有一些编码、计算机的工程背景。并且对数据工程感兴趣。如果玩儿过AWS或者有类似技能的小盆友会有加分的,比如在线课堂等。哦对了,还有SQl技能也是有加分的哈。除了这些之外,其他需要关注的技能就要看投简历的童鞋所选择的岗位需求了。 对于那些更需要有经验的老鸟工程师岗位来说,我希望看到应聘者能有一些大数据领域的经验,比如有一些典型大数据平台或者框架的使用经验,比如Hadoop/Spark/Hive之类的,然后数据库的经验等也是很重要的。唉,不知道作者你们是在哪个国家,但是在我们这儿(澳大利亚),这些公司面试官都需要有经验的人,他们很少会让刚毕业的青瓜蛋子担任数据科学家。所以对于像我这样想从数据分析师过渡到数据科学家的人来说,应聘机会都没有。我太难了。越不给机会我越没有经验,死循环无解无解。在美国湾区,很多公司都会让硕士或者博士担任初级数据科学家。当然了,我还认识一些本科生,他们在5年前直接升职成为数据科学家。但我认为,在现在来说,那些没有研究生学位和背景的本科生也能够一跃成为数据科学家,这表明,各大公司正在调整它们所需的数据分析师的工作,也正在重塑以前被研究生所垄断的数据分析师职位的品牌定位。我有点质疑文中关于领域归并的统计合理性。因为我工作和研究的方向是计算机视觉,在此方向校友领域(在本科毕业之后,我曾经去做过全职的计算机视觉工程师,然后去卡内基梅隆大学CMU读的硕士学位),但是就我而言,我虽然学的是计算机视觉,但好像从来没有搞过任何跟“数据科学”相关的研究、工程。数据科学和典型的机器学习岗位有什么区别呢?文中在提及“数据工程师”时,是指开发算子?基础操作函数?还是机器学习系统工程?另外,请教有经验的大佬们,上述这些技能或者工作是如何更广泛地应用在计算机视觉和机器学习领域中的呢?我曾经面试了一些更基础的数据学习岗位,然后我目前正在学习更多的分布式系统/计算机体系结构方面的知识。从我的经验和理解来看,计算机视觉或者机器学习的基础工作岗位开发里,99%是和系统工程类似的,这些应聘者的技能包在其他机器学习相关岗位中也能适配,并且直接使用。但是,一个高水平的计算机视觉科学家是非常具体的,因为CV这个领域和传统机器学习还是有些区别和壁垒的。我觉得CV和机器学习这两个领域中间夹着的这个领域很奇怪,在这里我可以研究一些高层的应用,比如异常检测和姿态估计的问题,但是也可以下沉到研究C++相关的代码中。但是对于这两个角色来说,这些技能在初创公司之外是否有价值?大公司们需要这些多栈工程师吗?我觉得文章说的太真实了,很多东西真的取决于公司属性和你要应聘的职位的需求。每个单一的定义都不能一概而论。一般来说,数据科学比机器学习的范围更广泛。你会发现数据科学家们有时候做的活儿跟机器学习工程师一样。但是有时我们又会发现,数据科学家也能去做知识表示或者统计学工作,这些工作有些只是为了给那些管理人员演示、提供可视化的展示。数据科学家和数据工程师这两个岗位的定位同样让人困惑。因为我曾经见过有的数据工程师被“提拔”为数据科学家,但是这仅作为资历老的一种形式化奖励,实际上他们还是做着跟以往相同的工作。依在下之见,这一切都是无中生有的,它就像早起的初创公司在招聘的福利标语一样可笑“一个你选择的未命名的C套件标题”。我在美国五大巨头公司FAANG之一工作(FAANG=Facebook、Apple、Amazon、Netflix、Alphabet或者Google),在我们这,这几个职位的报酬顺序大致是:数据工程师<软件工程师=数据科学家<机器学习工程师数据工程师的工作是让数据集可用,软件工程师做的是一些一般性的开发工作,数据科学家的职责是训练Python模型,而机器学习工程师负责从模型中获取权重和偏差,并在Scala中进行商业化部署,并和一些基础的组件打交道(包括kafka和Spark等)。我曾经是一名数据科学家,然后转方向变成了一名软件工程师,现在我准备专职到机器学习工程师。当然,我们也有薪水更高的应用科学家岗位,但面试官甚至从来不看我的简历,因为我没有博士学位。我的理解虽然有点刻薄,但是一针见血。数据科学家更像是一个业务专员,他们知道如何分析数据、需要哪些数据、如何组合和提取信息等。而数据工程师是一个知道如何准备、清理、收集和分发数据工具的人。但用于数据管道他们就像一个开发人员和开发工具的混合体。我觉得是这样的,数据科学家更接近机器学习领域,而数据工程师更像是程序员。这篇文章和我的想法不谋而合。虽然我不是业内人士,但是我想补充点东西。数据科学家、数据工程师们在技能包上的重叠是意料之中的。他们的工作同质化十分严重。是的,总会有重叠,因为最开始的时候人们对机器学习产生兴趣,但随后便发现真正的机器学习工作需要深厚的积累和一个博士学位,然后他们无可奈何地走上了一条更“轻量化”的数据科学道路,也就是做数据工程师。但随后发现数据工程师这样的“基础工作”也开始有着较高较深的要求了。所以,很多数据工程师多多少少都会了解一些机器学习和数据科学领域的东西。作者:
Mihail Eric,亚马逊Alexa AI机器学习科学家,斯坦福大学计算机科学硕士,曾担任斯坦福大学自然语言处理(NLP)研究助理。
https://www.mihaileric.com/posts/we-need-data-engineers-not-data-scientists/
https://www.reddit.com/r/MachineLearning/comments/kx0j1v/d_we_need_more_data_engineers_not_data_scientists/