 GiantPandaCV
GiantPandaCV




【GiantPandaCV导语】本次简要的总结了模型量化研究的一些问题,介绍了量化存在的量化误差与其总体上解决量化误差的一些方法。主要讨论了5种非线性量化的方法。
量化任务的简要总结:1、量化映射方法,也就是将float-32映射到Int数据类型,每个间隔是相等的还是不相等的,这里就是均匀量化(uniform quantization)和非均匀量化(non-uniform quantization),也可以叫作线性量化和非线性量化
2、关于映射到整数是数值范围是有正负数,还是都是正数,这里就是对称量化(有正负数)和非对称量化(全是正数),非对称量化就有zero-point,zero-point的主要作用是用于做padding。
3、原精度即浮float-32,量化到什么样的数据类型,这里就有float和int;到底要选择量化后的是多少个bit,这里就有1-bit(二值网络)、2-bit(三值网络)、3-bit、4-bit、5-bit、6-bit、7-bit、8-bit,这几种量化后的数值类型是整型。
4、是固定所有网络都是相同的bit-width,还是不同的,这里就有混合精度量化(Mixed precision)
5、是从一个已经训练好的模型再进行量化,还是有fine tune的过程或者直接是从头开始训练一个量化的模型,这里就有Post-training quantization(后量化,即将已经训练完的模型参数进行量化)、quantization-aware training(量化感知训练,即在从头开始训练中加入量化)和quantization-aware fine tune(在fine tune训练中加入量化)。
我们与剪枝来做一个不恰当的对比
上面的(3)选择什么样的bit-width来做量化,对应的是剪枝的压缩率,即要剪枝多少参数;
上面的(4)是所有参数统一一个bit表示还是采用混合精度量化,对应的剪枝就是结构化剪枝和非结构化;
上面的(5)有没有fine tune操作,对应的剪枝就是《training from starch》和三步剪枝方法(train-prune-fine tune);
「量化误差到底来自于哪里?」
1、从float-32到Int数据类型,其中有一个round的操作,这里肯定会有误差;2、激活函数的截断;3、溢出时候的处理也有可能带来误差。
那么继续来讨论一下「量化遇到的问题」是什么:
1、weight和activation的数据分布呈现出一个类拉普拉斯分布或者类高斯分布,数据分布是一个钟型分布,大部分数据集中在中间,两头的数据比较少。如果采用均与量化(uniform quantization),由于是等间隔的,那么中间密集分布的数据的分辨率低。举个例子,假如总共10个值,fp32_x={10,-10,0.11,0.21,0.15,0.05,-0.14,-0.22,-0.08,-0.35},采用对称均匀分布量化,(10-(-10))/(255)= 20/255,Int8_x={127,-127,1,3,2,1,-2,-3, -1,-5},可以看到,0.05和0.11被量化同一个int-8的数值1,而且量化后的数值大部分集中在了[-5,3],而其余的数值没有用到。如何解决这个问题?很简单,给密集的区域用比较多的Int数值表示(增大分辨率),稀疏的区域用比较少的Int数值表示;这就是一个不等间距间隔,称为非均与量化(non-uniform quantization)或非线性量化。
2、另外一个问题就是每一层的数值范围不一定都相同,activation在不同层的数值范围会不一样,这就会产生另外一个问题,动态值域问题,dynamic range。这个dynamic range如何影响量化效果呢?比如8-bit的均与分布量化,值域[-2, 2]的单位间隔是(2-(-2))/255 = 4/ 255,值域[-6, 6]的单位间隔是(6-(-6))/255 = 12/ 255,明显前面的分辨率更高。还是由于数据分布钟型分布,即可abs(数值)大的占据的比例很小,因此,这里可以采用截断的方式提高来量化的分辨率。
3、round会肯定会带来误差,怎么处理呢?Stochastic rounding,因为其期望是x,可以减少round的误差.
Round
证明:
其中是向下取整,即取不大于x的最大整数 4、如果是量化感知训练,会遇到另外一个新的问题,就是量化这个操作的导数为0,在backwards的时候,梯度在后向传播中传不到后面。怎么办?(1)STE(Straight-Through Estimator ),直通估算器,即将该操作的梯度设置为1,那么梯度就可以传递下去,;(2)设计一个光滑可导且导数不为零的量化,比如Lq-Net和DSQ(Differentiable Soft Quantization)
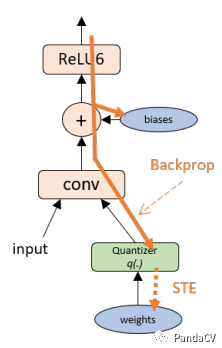
以上就是总结的量化知识点和存在的一些问题,可能列举的还不够完善,希望大家提出宝贵的建议。下面先来讨论非均匀量化/非线性量化,参考文章如下:1、《Convolutional Neural Networks using Logarithmic Data Representation》 2016
2、 Powers-of-two quantization,这个方法我还没找到原论文
3、《Quantization Networks》CVPR 2019
4、《Additive powers-of-two quantization: an efficient non-uniform discretization for neural networks》 ICLR 2020
5、《Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks》 CVPR 2019
6、《Post-Training Piecewise Linear Quantization for Deep Neural Networks》ECCV 2020
「一、均匀量化/线性量化 uniform quantization」
就是scale,是量化,是反量化,
另外一种写法,是全精度数据的值域[0,],大括号里面就有255个值,让全精度数据映射到这255值。
「二、Logarithmic」文章:《Convolutional Neural Networks using Logarithmic Data Representation》
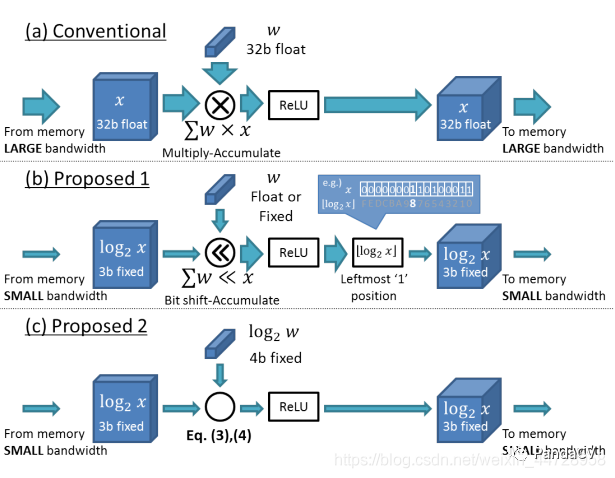
先贴公式,下面公式是上图(b)的方案:
为啥要将x变成log呢?就是为了在做矩阵乘法的时候用2的指数形式,先,后面再用复原。这是为了可以用位移的方式实现乘法。方案(b)只将input做了log操作。
继续看上图(c)的方案,即weight和input两个矩阵乘法的乘子都做了log操作,那么:
做矩阵乘法的时候,weight和input都需要用来复原之前的log操作。另外还要担心溢出,所以要有做一个截断clamp。一定的bit的数值范围,记为,其中,
对应的均匀量化/线性量化:
其中
「这个方法,还是比较复杂的,而且是2016的论文,大家就看看理解一下就好了。」
「三、Powers-of-two quantization(PoT)」
量化的值跟名字一样,就是要把浮点数量化为2的n次幂,下面公式是PoT的计算公式
下面公式也是PoT的计算公式,不过是以集合的形式,列举可以选的PoT值
其中表示bit位数,这个也是为了做乘法的时候,可以使用位移。
那PoT的缺限在哪里呢?举个例子最好理解: 为例子,那么两个最小的值为 和 ,这两数值太接近了;而两个最大值为 和 ,这两个最大值的间距又过大。当bit位数增加的时候,最大值仍然是 和 ,最小值的颗粒度更加细了。
「四、Additive powers-of-two(APoT)」
先来看看APoT的名字比powers-of-two多了个additive,也就说明比PoT的非线性量化多了个加法项, where
其中,
表示是缩放系数,以保证中的最大水平为;
是基位宽度(base bit-width),是每个加法项的位宽;
是加法项的数量。
当设置了 和 时,可以通过计算。总共有个级别。APoT量化中加法项的数量可以随位宽b的增加而增加,这为非均匀水平提供了更高的分辨率。下面的图片展示了均匀分布量化、PoT量化和APoT量化的图,可以看出一下几点:1、均与分布量化是一个等间隔的阶梯,对于钟性分布的数据不利;
2、PoT解决了一个问题,就是在值比较小的区域阶梯变多了,也就是分辨率变高了,但是也存在Powers-of-two quantization中提到的问题;
3、APoT就是为了解决PoT存在的问题,也就是当bit数增加的时候,两个最大值的之间的分辨率没有提高的问题。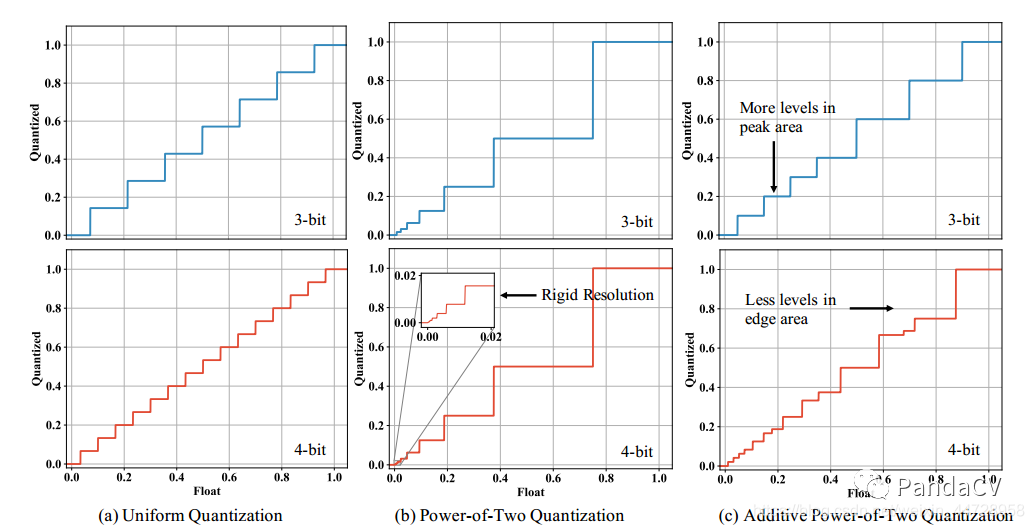 因为没有mobilenet、shufflnet的实验,实验结果就不贴图了,另外因为多了一些累加,具体speedup不好说,代码开源了。
因为没有mobilenet、shufflnet的实验,实验结果就不贴图了,另外因为多了一些累加,具体speedup不好说,代码开源了。
「五、可微分的非线性量化」
可微分的非线性量化留到下一次讨论,给自己挖个坑,即两篇《Quantization Networks》和《Differentiable Soft Quantization: Bridging Full-Precision and Low-Bit Neural Networks》(当然还有其他的文章,我还没找到),主要的思路是:量化映射这个操作原来是阶跃函数或者阶段函数,是不可导或者导数为0,那么找一个可导的函数比如sigmoid去模拟阶跃函数,利用学习的方式去找上图的阶梯。这样就可以不用STE的方法,也就没有了梯度不匹配的问题。当然这种量化方法也有局限性,就是,得用训练的方式,肯定增加了耗时,而且对于硬件是否友好,这个还得具体落地实验。因为DSQ有mobilenet的实验,就贴实验效果表格(Quantization Networks没有mobilenet实验就忘记他吧):DSQ: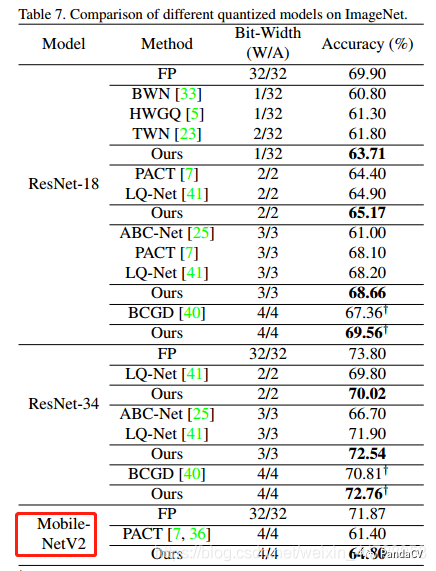
「六、Piecewise Linear Quantization」(推荐)
最后来讨论一下PWLQ(作者自己要这么缩写的,不是我强行造词)「。代码开源了」。就同名字一样,分段线性量化,这个思路简单而巧妙:在全精度数据的分布中,找一个分位点,那么中间的部分给予比较多的bit位数做一个线性量化,两边分比较少的bit位数也做一个线性量化,非常的巧妙的做法。
m是量化的值域[-m; m] (m > 0) , , ,uni表示的是均匀分布量化/线性量化。看图就能一眼看懂这个公式。
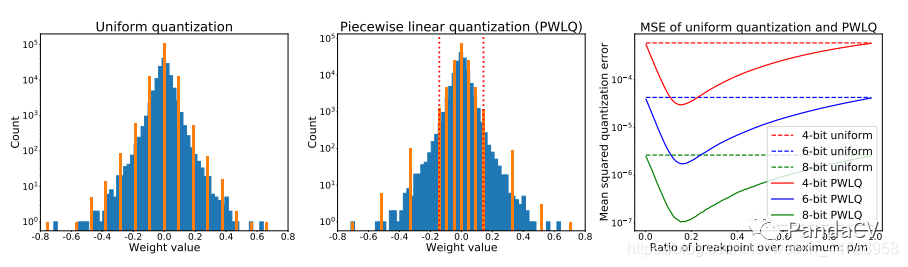
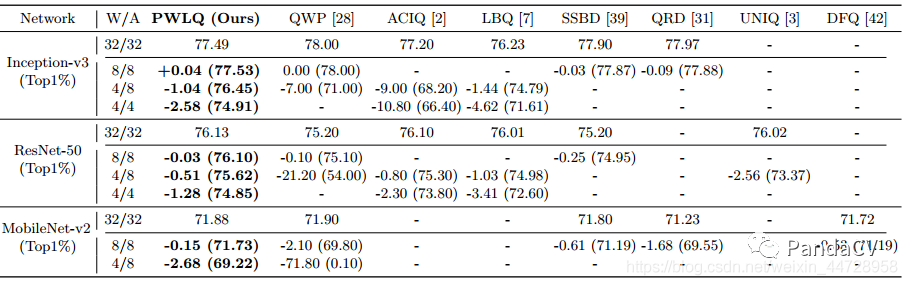
图中,m=0.8,,。来看看效果,(有mobilenet的实验):
后续有时间回过头来,我想更加详细的写一下这些内容。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。


