
IP协议源码分析
共 8745字,需浏览 18分钟
· 2021-02-12
IP协议 是网络的最重要部分,毫不夸张地说,正是因为有 IP协议 才有了互联网。而 IP协议 最重要的是 IP地址,IP地址 就好像我们的家庭住址一样,用于其他人方便找到我们的位置。
当然,这篇文章并不是介绍 IP协议 的原理,有关 IP协议 的原理可以参考经典的书籍《TCP/IP协议详解》,而这篇文章主要介绍的是 Linux 内核怎么实现 IP协议。
IP协议简介
虽然我们不会对 IP协议 做详细介绍,但是还是作个简单的介绍吧,不然直接分析代码有点唐突。
如果有一台计算机A和一台计算机B,计算机A想与计算机B通讯的话怎么办?
如果计算机A与计算机B是直连的,那么计算机A可以直接发送信息给计算机B,如下图:
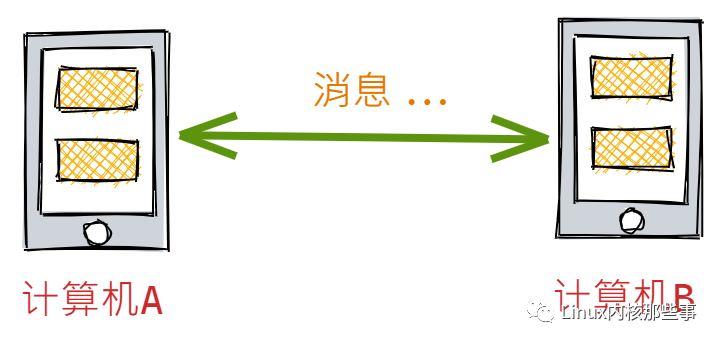
所以,如果是直连的话,问题很容易解决。但是,大多数情况下,互联网上的计算机都不是直连的。试想一下,如果在中国的电脑如果要与美国的电脑发送消息,那是不可能直接通过一条网线连接的。
那么,互联网上的计算机之间是通过什么连接的的?答案就是 路由器。如下图:
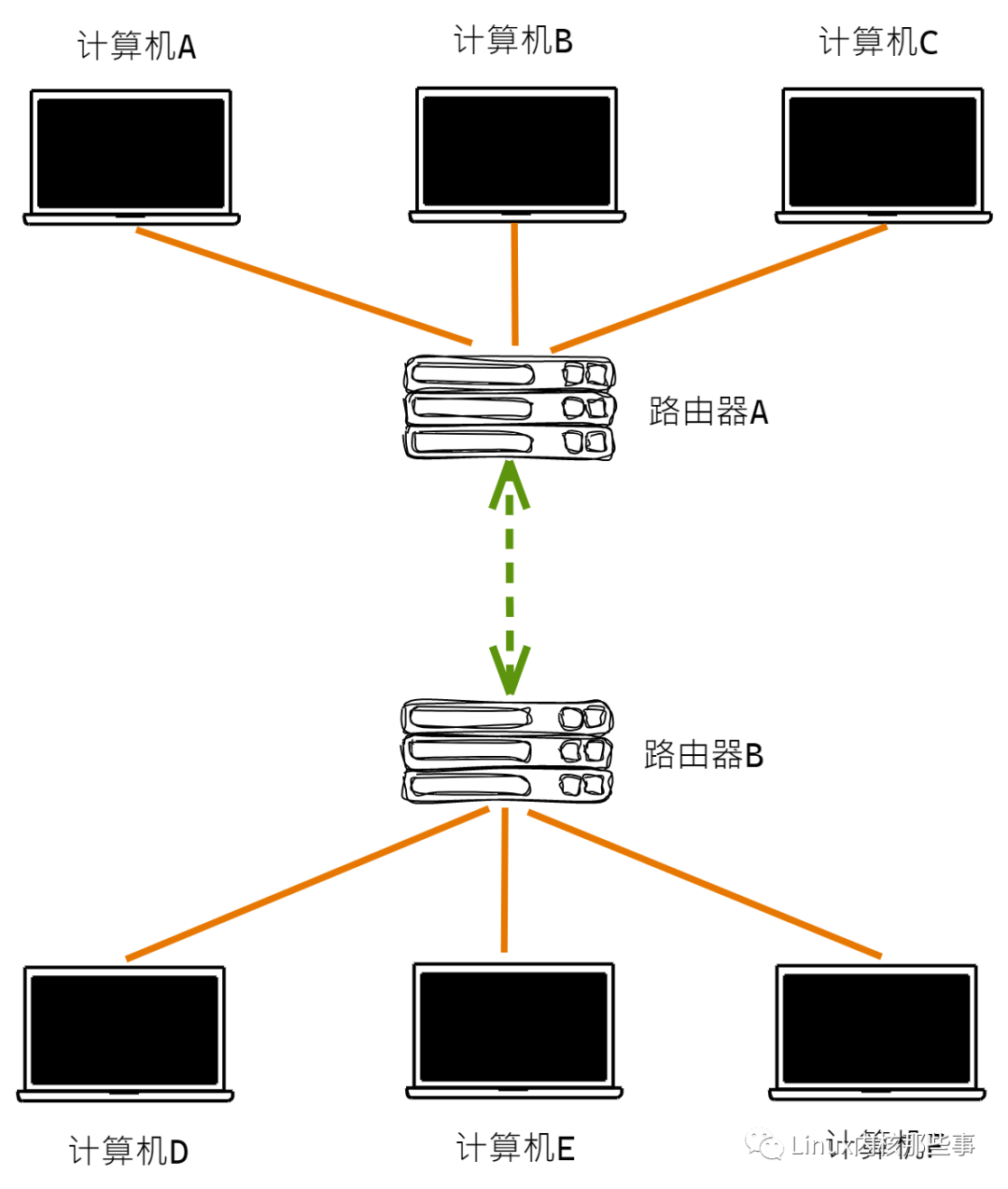
由于在互联网中,计算机与计算机之间不是直连的,所以两台计算机之间要通讯的话不能直接发送消息,因为不同的计算机之间不知道对方的位置。
那么,有什么办法解决呢?我们现实生活中,房子都有一个固定的地址,如:广东省广州市天河区林和西路98号,我们可以通过这个地址找到对应的房子。所以,对应互联网上的计算机,我们也可以人为的为其编上地址,名为 IP地址。
IP地址 由一个 32 位的整型数字表示,学过计算机科学的同学都指定,一个 32 位的整型数字能够表示的范围为:0 ~ 4294967295。所以,IP地址 理论上能够支持 4294967296 台计算机上网(但事实上远远少于这个数,因为有很多地址用于特殊用途)。
但是,32 位的整型数字对人类的记忆不太友好,所以,又将这个 32 位的整型数字分成 4 个 8 位的整型数字,然后用 点 将他们连接起来,如下图:

所以,IP地址 表示的范围如下:
0.0.0.0 ~ 255.255.255.255我们可以在 Windows 系统的网络设置处查看到本机的 IP地址,如下图:

有了 IP地址 后,就可以为互联网上的每台计算机设置 IP地址,如下图:
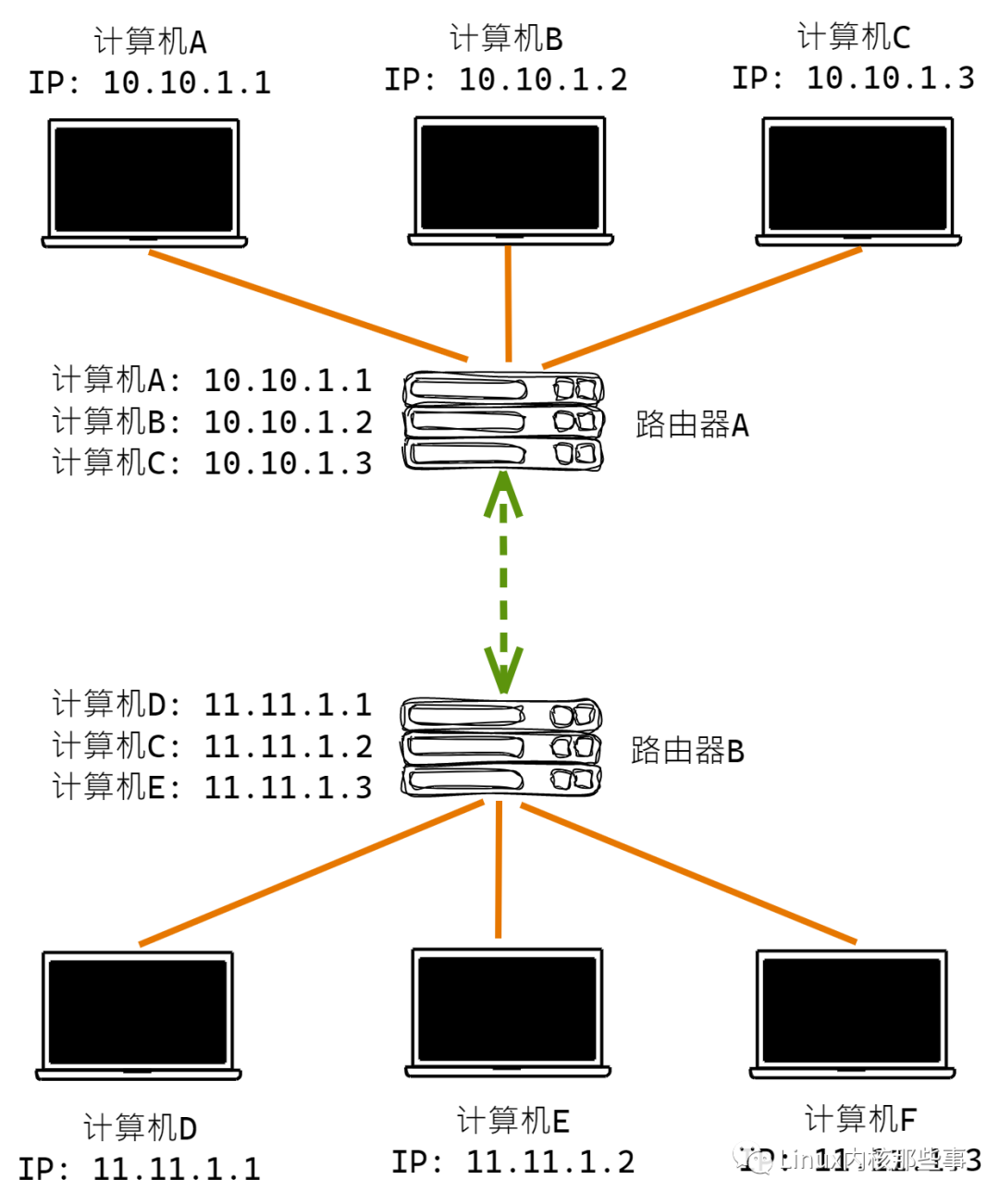
这样,为每台计算机设置好 IP地址 后,不同计算机之间就可以通过 IP地址 来进行通讯。比如,计算机A想与计算机D通讯,那么就可以通过向 IP地址 为 11.11.1.1 的地址发送消息。
通信过程如下:
计算A把自己的
IP地址(源IP地址)与计算机B的IP地址(目标IP地址)封装成数据包,然后发送到路由器A。路由器A接收到计算机A的数据包,发现目标
IP地址不在同一个网段(也就是连接不同路由器的),就会从路由表中找到合适的下一跳路由器,把数据包转发出去(也就是路由B)。路由器B接收到路由器A的数据后,从数据包中获取到目标
IP地址为11.11.1.1,知道此IP地址是计算机D的IP地址,所以就把数据转发给计算机D。
由于每个路由器都知道连着自己的所有计算机的 IP地址(称为路由表),所以路由器与路由器之间可以通过 路由协议 交换路由表的信息,这样就可以从路由表信息中查找到 IP地址 对应的下一跳路由器。
IP协议 就介绍到这里了,更详细的原理可以参考其他资料。
IP头部
由于向网络中的计算机发送数据时,必须指定对方的 IP地址(目标IP地址) 和本机的 IP地址(源IP地址),所以需要在发送的数据包添加 IP协议 头部。IP协议 头部的格式如下图所示:
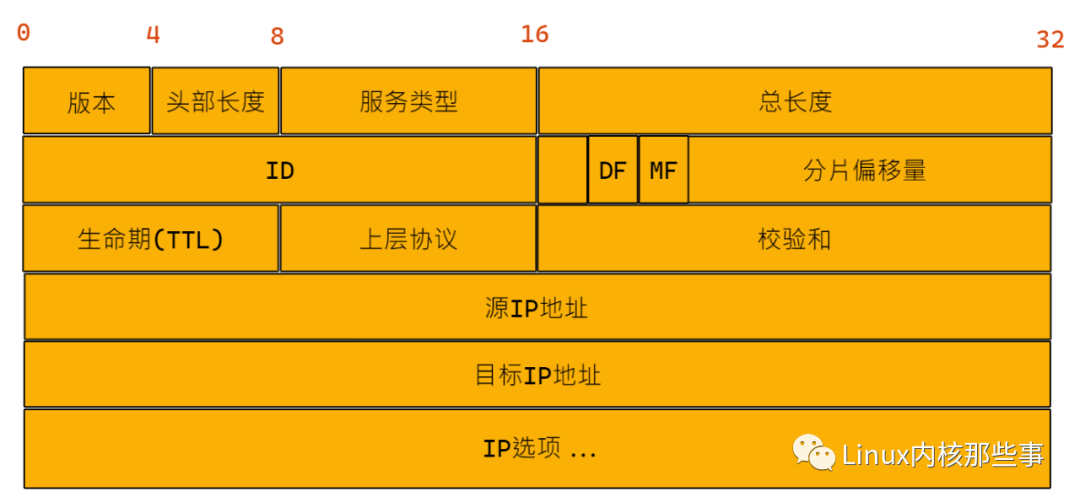
从上图可以看出,除了 目标IP地址 和 源IP地址 外,还有其他一些字段,这些字段都是为了实现 IP协议 而定义的。下面我们来介绍一下 IP头部 各个字段的作用:
版本:占 4 个位。表示IP协议的版本,如果是IPv4的话,那么固定为 4。头部长度:占 4 个位。表示IP头部的长度,单位为字(即 4 个字节)。由于其最大值为 15,所以IP头部最长为 60 字节(15 * 4)。服务类型:占 8 个位。定义不同的服务类型,可以为 IP 数据包提供不同的服务。本文不涉及这个字段,所以不作详细介绍。总长度:占 16 个位。表示整个 IP 数据包的长度,包括数据与IP头部,所以 IP 数据包的最大长度为 65535 字节。ID:占 16 个位。用于标识不同的 IP 数据包。该字段和Flags和分片偏移量字段配合使用,对较大的 IP 数据包进行分片操作,关于 IP 数据包分片功能后面会介绍。标记(Flags):占 3 个位。该字段第一位不使用,第二位是DF(Don't Fragment)位,DF位设为 1 时表明路由器不能对该数据包分段。第三位是MF(More Fragments)位,表示当前分片是否为 IP 数据包的最后一个分片,如果是最后一个分片,就设置为 0,否则设置为 1。分片偏移量:占 13 个位。表示当前分片位于 IP 数据包分片组中的位置,接收端靠此来组装还原 IP 数据包。生存期(TTL):占 8 个位。当 IP 数据包进行发送时,先会对该字段赋予某个特定的值。当 IP 数据包经过沿途每一个路由器时,每个沿途的路由器会将该 IP 数据包的 TTL 值减少 1。如果 TTL 减少至为 0 时,则该 IP 数据包会被丢弃。这个字段可以防止由于路由环路而导致 IP 数据包在网络中不停被转发。上层协议:占 8 个位。标识了上层所使用的协议,例如常用的 TCP,UDP 等。校验和:占 16 个位。用于对 IP 头部的正确性进行检测,但不包含数据部分。因为每个路由器要改变 TTL 的值,所以路由器会为每个通过的 IP 数据包重新计算这个值。源 IP 地址与目标 IP 地址:这两个字段都占 32 个位。标识了这个 IP 数据包的源IP地址和目标IP地址。IP选项:长度可变,最多包含 40 字节。选项字段很少被使用,所以本文不会介绍。
IP头部 结构在内核中的定义如下:
struct iphdr {__u8 version:4,ihl:4;__u8 tos;__u16 tot_len;__u16 id;__u16 frag_off;__u8 ttl;__u8 protocol;__u16 check;__u32 saddr;__u32 daddr;options start here. */};
IP头部 结构的各个字段与上图的所展示的字段是一一对应的。
虽然 IP头部 看起来好像很复杂,但如果按每个字段所支持的功能来分析,就会豁然开朗。一个被添加上 IP头部 的数据包如下图所示:
当然,除了 IP头部 外,在一个网络数据包中还可能包含一些其他协议的头部,比如 TCP头部,以太网头部 等,但由于这里只分析 IP协议,所以只标出了 IP头部。
接下来,我们通过源码来分析 Linux 内核是怎么实现 IP协议 的,我们主要分析 IP 数据包的发送与接收过程。
IP数据包的发送
要发送一个 IP 数据包,可以通过两个接口来完成:ip_queue_xmit() 和 ip_build_xmit()。第一个主要用于 TCP 协议,而第二个主要用于 UDP 协议。
我们主要分析 ip_queue_xmit() 这个接口,ip_queue_xmit() 代码如下:
int ip_queue_xmit(struct sk_buff *skb){struct sock *sk = skb->sk;struct ip_options *opt = sk->protinfo.af_inet.opt;struct rtable *rt;struct iphdr *iph;rt = (struct rtable *)__sk_dst_check(sk, 0); // 是否有路由信息缓存if (rt == NULL) {u32 daddr;u32 tos = RT_TOS(sk->protinfo.af_inet.tos)|RTO_CONN|sk->localroute;daddr = sk->daddr;if(opt && opt->srr)daddr = opt->faddr;// 通过目标IP地址获取路由信息if (ip_route_output(&rt, daddr, sk->saddr, tos, sk->bound_dev_if))goto no_route;__sk_dst_set(sk, &rt->u.dst); // 设置路由信息缓存}skb->dst = dst_clone(&rt->u.dst); // 绑定数据包的路由信息...// 获取数据包的IP头部指针iph = (struct iphdr *)skb_push(skb, sizeof(struct iphdr)+(opt?opt->optlen:0));// 设置 版本 + 头部长度 + 服务类型*((__u16 *)iph) = htons((4<<12)|(5<<8)|(sk->protinfo.af_inet.tos & 0xff));iph->tot_len = htons(skb->len); // 设置总长度iph->frag_off = 0; // 分片偏移量iph->ttl = sk->protinfo.af_inet.ttl; // 生命周期iph->protocol = sk->protocol; // 上层协议(如TCP或者UDP等)iph->saddr = rt->rt_src; // 源IP地址iph->daddr = rt->rt_dst; // 目标IP地址skb->nh.iph = iph;...// 调用 ip_queue_xmit2() 进行下一步的发送操作return NF_HOOK(PF_INET, NF_IP_LOCAL_OUT, skb, NULL, rt->u.dst.dev,ip_queue_xmit2);}
ip_queue_xmit() 函数的参数是要发送的数据包,其类型为 sk_buff。在内核协议栈中,所有要发送的数据都是通过 sk_buff 结构来作为载体的。ip_queue_xmit() 函数主要完成以下几个工作:
首先调用
__sk_dst_check()函数获取路由信息缓存,如果路由信息还没被缓存,那么以目标IP地址作为参数调用ip_route_output()函数来获取路由信息,并且设置路由信息缓存。路由信息一般包含发送数据的设备对象(网卡设备)和下一跳路由的IP地址。绑定数据包的路由信息。
获取数据包的
IP头部指针,然后设置IP头部的各个字段的值,如代码注释所示,可以对照IP头部结构图来分析。调用
ip_queue_xmit2()进行下一步的发送操作。
我们接着分析 ip_queue_xmit2() 函数的实现,代码如下:
static inline int ip_queue_xmit2(struct sk_buff *skb){struct sock *sk = skb->sk;struct rtable *rt = (struct rtable *)skb->dst;struct net_device *dev;struct iphdr *iph = skb->nh.iph;...// 如果数据包的长度大于设备的最大传输单元, 那么进行分片操作if (skb->len > rt->u.dst.pmtu)goto fragment;if (ip_dont_fragment(sk, &rt->u.dst)) // 如果数据包不能分片iph->frag_off |= __constant_htons(IP_DF); // 设置 DF 标志位为1ip_select_ident(iph, &rt->u.dst); // 设置IP数据包的ID(标识符)// 计算 IP头部 的校验和ip_send_check(iph);skb->priority = sk->priority;return skb->dst->output(skb); // 把数据发送出去(一般为 dev_queue_xmit)fragment:...ip_select_ident(iph, &rt->u.dst);return ip_fragment(skb, skb->dst->output); // 进行分片操作}
ip_queue_xmit2() 函数主要完成以下几个工作:
判断数据包的长度是否大于最大传输单元(
最大传输单元 Maximum Transmission Unit,MTU是指在传输数据过程中允许报文的最大长度),如果大于最大传输单元,那么就调用ip_fragment()函数对数据包进行分片操作。如果数据包不能进行分片操作,那么设置
DF(Don't Fragment)位为 1。设置 IP 数据包的 ID(标识符)。
计算
IP头部的校验和。通过网卡设备把数据包发送出去,一般通过调用
dev_queue_xmit()函数。
ip_queue_xmit2() 函数会继续设置 IP头部 其他字段的值,然后调用 dev_queue_xmit() 函数把数据包发送出去。
当然还要判断发送的数据包长度是否大于最大传输单元,如果大于最大传输单元,那么就需要对数据包进行分片操作。数据分片是指把要发送的数据包分割成多个以最大传输单元为最大长度的数据包,然后再把这些数据包发送出去。
IP数据包的接收
IP数据包的接收是通过 ip_rcv() 函数完成的,当网卡接收到数据包后,会上送到内核协议栈的链路层,链路层会根据链路层协议(如以太网协议)解析数据包。然后再将解析后的数据包通过调用 ip_rcv() 函数上送到网络层的 IP协议,ip_rcv() 函数的实现如下:
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt){struct iphdr *iph = skb->nh.iph; // 获取数据包的IP头部if (skb->pkt_type == PACKET_OTHERHOST) // 如果不是发送给本机的数据包, 则丢掉这个包goto drop;...// 判断数据包的长度是否合法if (skb->len < sizeof(struct iphdr) || skb->len < (iph->ihl<<2))goto inhdr_error;// 1. 判断头部长度是否合法// 2. IP协议的版本是否合法// 3. IP头部的校验和是否正确if (iph->ihl < 5 || iph->version != 4 || ip_fast_csum((u8 *)iph, iph->ihl) != 0)goto inhdr_error;{__u32 len = ntohs(iph->tot_len);if (skb->len < len || len < (iph->ihl<<2)) // 数据包的长度是否合法goto inhdr_error;__skb_trim(skb, len);}// 继续调用 ip_rcv_finish() 函数处理数据包return NF_HOOK(PF_INET, NF_IP_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);inhdr_error:IP_INC_STATS_BH(IpInHdrErrors);drop:kfree_skb(skb);out:return NET_RX_DROP;}
ip_rcv() 函数的主要工作就是验证 IP头部 各个字段的值是否合法,如果不合法就将数据包丢弃,否则就调用 ip_rcv_finish() 函数继续处理数据包。
ip_rcv_finish() 函数的实现如下:
static inline int ip_rcv_finish(struct sk_buff *skb){struct net_device *dev = skb->dev;struct iphdr *iph = skb->nh.iph;// 根据源IP地址、目标IP地址和服务类型查找路由信息if (skb->dst == NULL) {if (ip_route_input(skb, iph->daddr, iph->saddr, iph->tos, dev))goto drop;}...// 如果是发送给本机的数据包将会调用 ip_local_deliver() 处理return skb->dst->input(skb);}
ip_rcv_finish() 函数的实现比较简单,首先以 源IP地址、目标IP地址 和 服务类型 作为参数调用 ip_route_input() 函数查找对应的路由信息。
然后通过调用路由信息的 input() 方法处理数据包,如果是发送给本机的数据包 input() 方法将会指向 ip_local_deliver() 函数。
我们接着分析 ip_local_deliver() 函数:
int ip_local_deliver(struct sk_buff *skb){struct iphdr *iph = skb->nh.iph;// 如果是一个IP数据包的分片if (iph->frag_off & htons(IP_MF|IP_OFFSET)) {skb = ip_defrag(skb); // 将分片组装成真正的数据包,如果成功将会返回组装后的数据包if (!skb)return 0;}// 继续调用 ip_local_deliver_finish() 函数处理数据包return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,ip_local_deliver_finish);}
ip_local_deliver() 函数首先判断数据包是否是一个分片,如果是分片的话,就调用 ip_defrag() 函数对分片进行重组操作。重组成功的话,会返回重组后的数据包。接着调用 ip_local_deliver_finish() 对数据包进行处理。
ip_local_deliver_finish() 函数的实现如下:
static inline int ip_local_deliver_finish(struct sk_buff *skb){struct iphdr *iph = skb->nh.iph;skb->h.raw = skb->nh.raw + iph->ihl*4; // 设置传输层头部(如TCP/UDP头部){int hash = iph->protocol & (MAX_INET_PROTOS - 1); // 传输层协议对应的hash值struct sock *raw_sk = raw_v4_htable[hash];struct inet_protocol *ipprot;int flag;...// 通过hash值找到传输层协议的处理函数ipprot = (struct inet_protocol *)inet_protos[hash];flag = 0;if (ipprot != NULL) {if (raw_sk == NULL&& ipprot->next == NULL&& ipprot->protocol == iph->protocol){// 调用传输层的数据包处理函数处理数据包return ipprot->handler(skb, (ntohs(iph->tot_len) - iph->ihl*4));} else {flag = ip_run_ipprot(skb, iph, ipprot, (raw_sk != NULL));}}...}return 0;}
ip_local_deliver_finish() 函数的主要工作就是根据上层协议(传输层)的类型,然后从 inet_protos 数组中找到其对应的数据包处理函数,然后通过此数据包处理函数处理数据。
也就是说,IP层对数据包的正确性验证完成和重组后,会将数据包上送给传输层去处理。对于 TCP协议 来说,数据包处理函数对应的是 tcp_v4_rcv()。