
用Pandas秒秒钟搞定24张Excel报表,还做了波投放分析!
共 3206字,需浏览 7分钟
· 2021-02-06

大家好,我是早起。
最近有不少粉丝问我关于Python批量操作Excel的问题。
大家的关注点主要是如何循环遍历表格、如何用Pandas批量处理,当然,还有在996的压迫下如何提效(来挤出更多摸鱼时间)。

为此,我特意肝了几天,用基于实际业务的脱敏数据,以完整小项目的形式,来集中解决这些问题。
我的Pandas实战系列老传统,完整案例代码和数据源,已经打包好放在文末,顺便剧透文末还有送书活动。
项目背景
不吹牛集团这几年孵化了50个品牌,在各渠道做了大量品宣层面的曝光。现在集团首席吹牛官提了两个需求:
1. 要一张大表,包含每个月搜索人数TOP5的品牌相关数据,以及对应品牌在当月的搜索份额和排名。
2. 在现有数据基础上,找到最近一年投放效果还不错的品牌,要吹吹牛,做年度表彰。
这是小z特别准备的两个具有代表性的需求:
第一种:业务方已经定好了条条框框,需要数据分析师做的是取数和处理的工作,这样的“分析”工作,坑往往在于取数和清洗的复杂性。
第二种:业务方自己想了个模糊的方向,需要分析师结合实际数据,定逻辑,给建议。
数据预览
话音未落,集团首席吹牛官的跟屁虫就把相关源数据丢过来了
一共24张Excel表格,按月存储,涵盖了从2019年1月到2020年12月的数据。
表格内部数据大同小异:
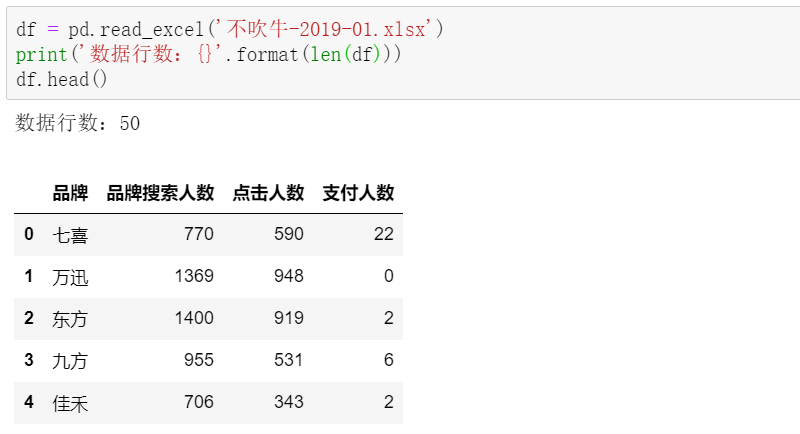
注:点击人数和支付人数,都是在搜索人数基础上统计的
每张表都有50个品牌,包括了品牌名、品牌搜索人数、点击人数和对应的支付人数这几个关键字段。
源数据就是这样简简单单中又透漏着麻麻烦烦,接下来,我们就开始手撕需求。
项目一:Python批量操作
开始动手前,我们要明确需求。
再回顾一下首席吹牛官的第一个需求:要一张大表,包含每个月搜索人数TOP5品牌的相关数据,以及对应品牌在当月的搜索份额和排名。
提炼:在现有源数据的基础上,我们还需要对各品牌月内按搜索人数排序,然后计算每个品牌搜索份额,取其前5,最后遍历汇总。
自动化之哥曾经说过:Python批量操作Excel,无论表格再多,处理逻辑再复杂,只要我们集中力量击破一张,就能够实现批量操作的全面胜利。
首先,我们要解决的是单张表的问题。
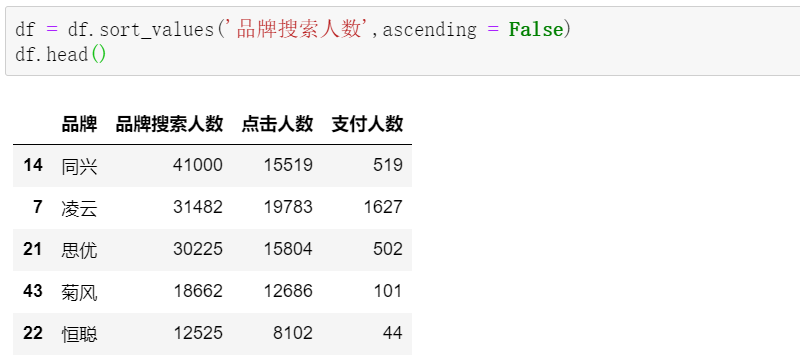
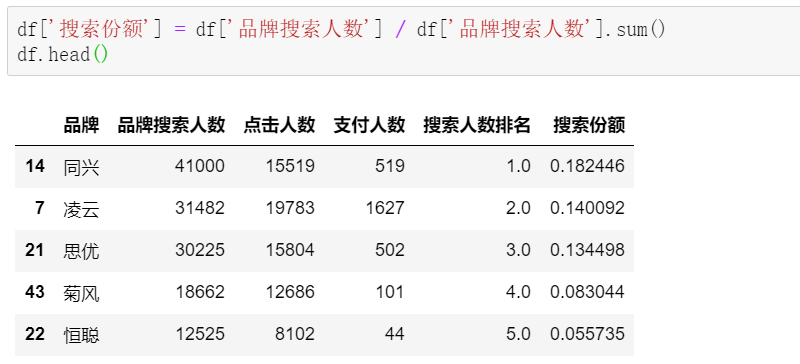
按搜索人数排序:
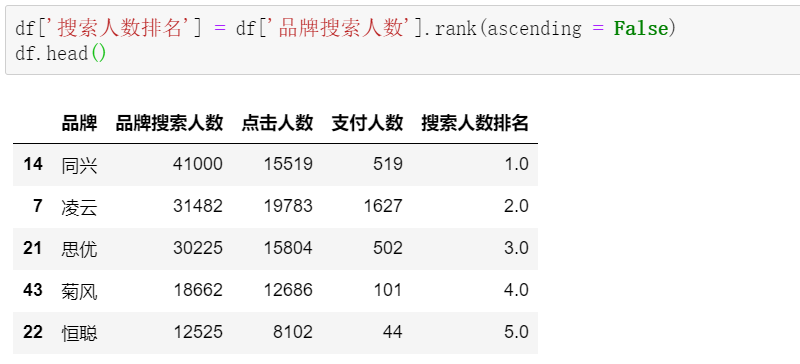
调用rank快速给到对应的排名:
再来计算搜索份额,搜索份额的计算公式:单品牌搜索人数/所有品牌搜索人数汇总,用Pandas计算,怎一个easy了的!
正当我们准备批量执行操作,首席吹牛官发来了消息:
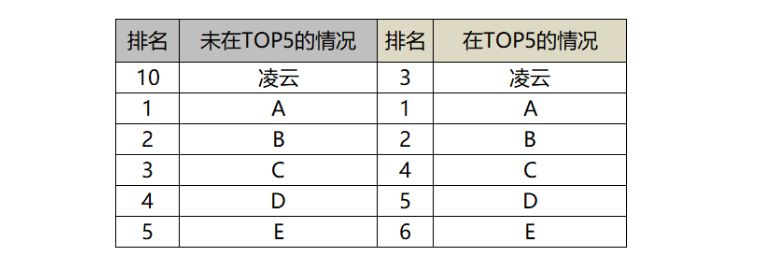
“需求一略有调整,投资人最关注的是凌云这个品牌,要求在汇总表中,每个月凌云品牌的相关指标排在最前面,后面跟着搜索排名TOP5的品牌”。
具体排名逻辑如图所示:
面对需求的临时改动,见过大风大浪的我们内心没有一丝波澜,甚至还有一点想笑。小事一桩,改改Pandas逻辑就好了。
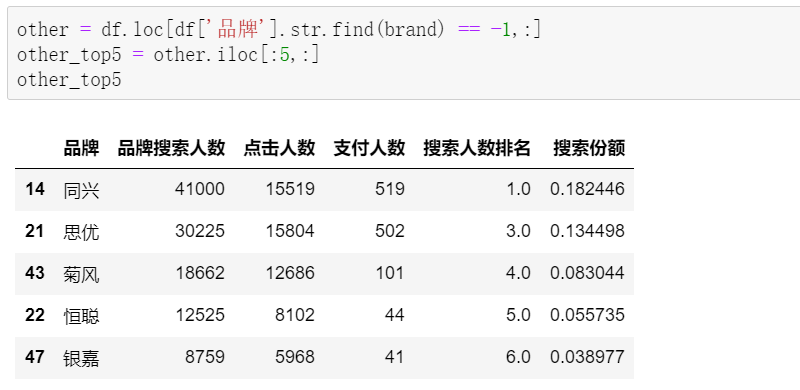
先找到目标品牌凌云:

再按照顺延的逻辑,定位TOP5品牌相关数据:
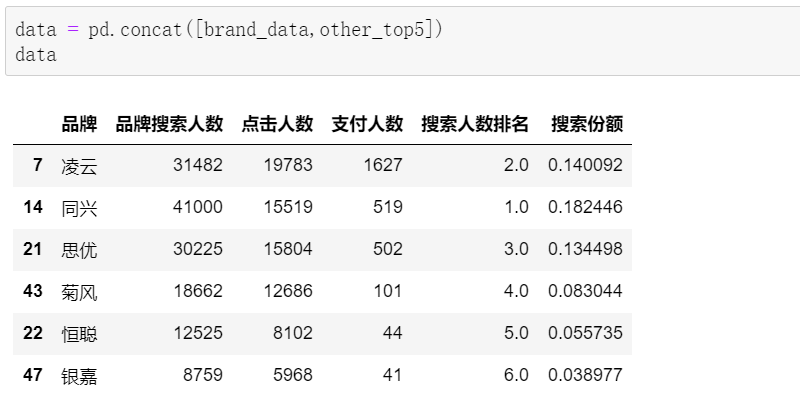
合并即可获取我们想要的结果:
单表操作完成,批量操作,只需要建立好循环+合并关系,并引入日期列,在合并结果中对不同的表数据做好区分:
result = pd.DataFrame()for name in os.listdir():df = pd.read_excel(name)df = df.sort_values('品牌搜索人数',ascending = False)df['搜索人数排名'] = df['品牌搜索人数'].rank(ascending = False)df['搜索份额'] = df['品牌搜索人数'] / df['品牌搜索人数'].sum()brand = '凌云'brand_data = df.loc[df['品牌'].str.find(brand) != -1,:]other = df.loc[df['品牌'].str.find(brand) == -1,:]other_top5 = other.iloc[:5,:]data = pd.concat([brand_data,other_top5])data['日期'] = name[4:-5]result = pd.concat([result,data])
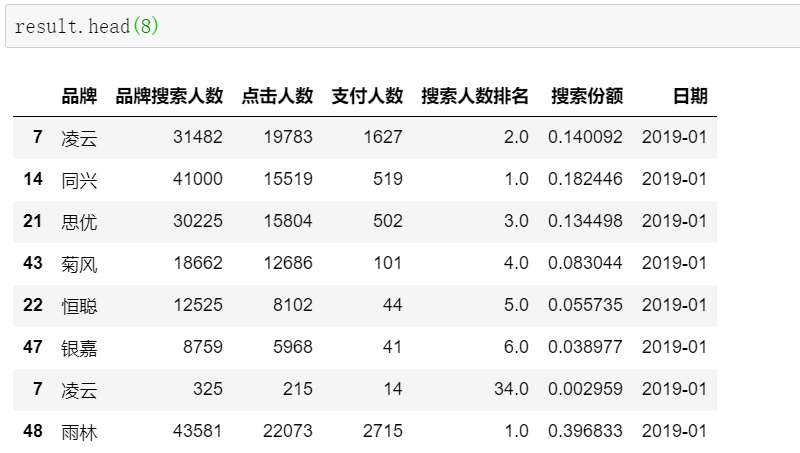
Pandas批量操作,就是如此丝滑~
第一个需求搞定。
项目二:品牌投放分析
还记得那个明(che)确(dan)的需求二吗?
“在现有数据基础上,找到最近一年投放效果还不错的品牌,要吹吹牛,做年度表彰。”
首席吹牛官以成本数据过于机密为由,除了说各品牌费用基本无差别之外,没有透露任何关于成本方面的数据,我们自然也无法计算投放ROI了这些核心指标了。
目前能够拿到的,只有品牌、搜索人数、点击人数和对应支付人数这几个指标。
要找到最近一年投放效果还不错的品牌,我们可以用漏斗思维,从量级(人数)和效率(转化率)两个角度来考虑:
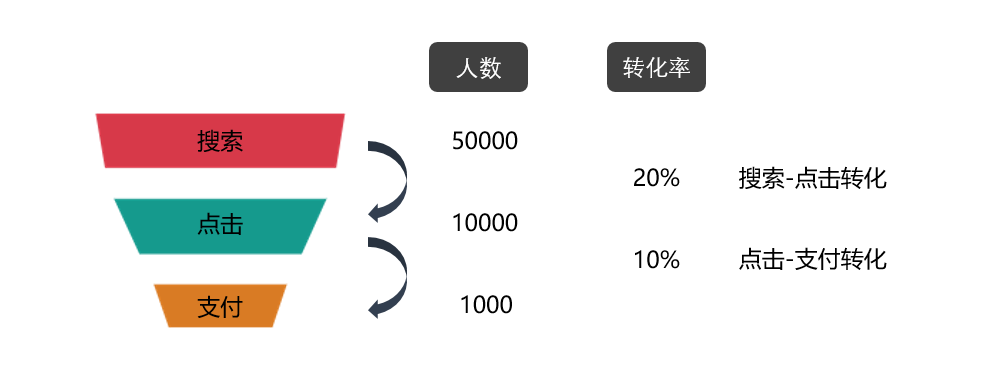
在费用无差别的情况下:
人群基数大(搜索人数),表示投放的心智效果不错,让更多用户被广告触达后,在平台主动搜相关的品牌。
搜索-点击转化率高,代表了搜索结果的精准度,搜索后展示页面的吸引力等等
点击-支付转化率高,更可能受产品详情页面、活动力度等影响
在项目二场景中,三个指标越高越好。接下来,我们就结合搜索人数,搜索-点击转化率和点击-支付转化率,用Pandas做一波分析。
要对最近一年的数据做分析,我们先把2020年所有数据合并,拿到汇总表:

再按品牌的维度,做指标汇总:
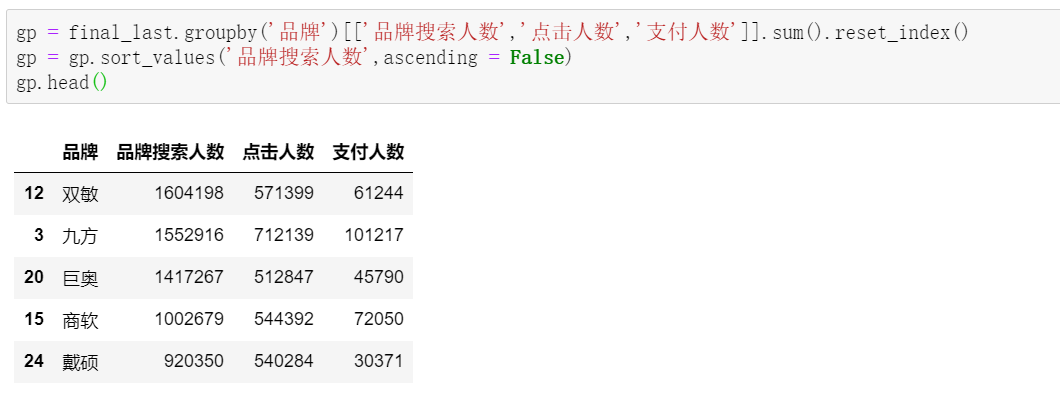
计算对应的搜索-点击转化率,点击-支付转化率:
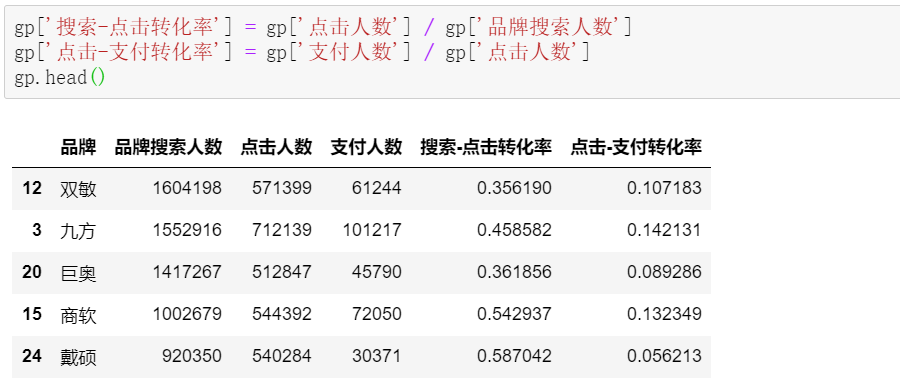
基础数据齐活了!
从仅有的head5数据可以看到,双敏品牌以160万的搜索人数独占鳌头,但是!排名第二的九方,虽然搜索人数少了40多万,却能凭借较高的搜索-点击转化率和点击-支付转化率,在支付人数上远超双敏,成为支付之王。
表格太晦涩,我们画个图吧:
注:因为分析背景是无差别投放,搜索人数重要性非常高,为了可视化简洁清晰,我们简单粗暴的筛选TOP15品牌来绘图
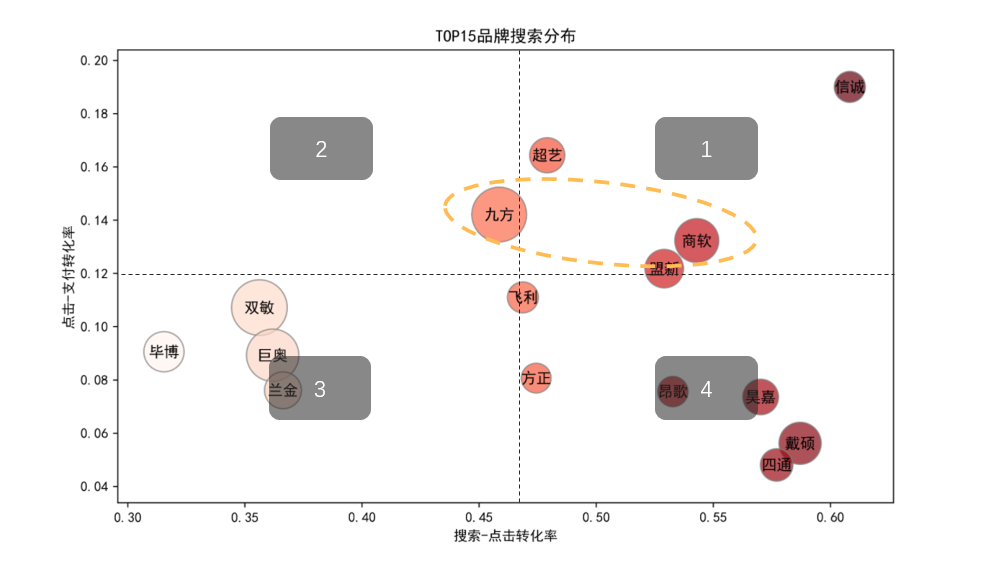
气泡大小代表着品牌搜索人数量级
根据气泡图,我们按照搜索-点击转化率和点击-支付转化率的高低划分了4个区间:
区间1:高搜索-点击转化,高点击-支付转化
区间2:低搜索-点击转化,高点击-支付转化
区间3:低搜索-点击转化,低点击-支付转化
区间4:高搜索-点击转化,低点击-支付转化
再结合数据表,看的更加清晰:
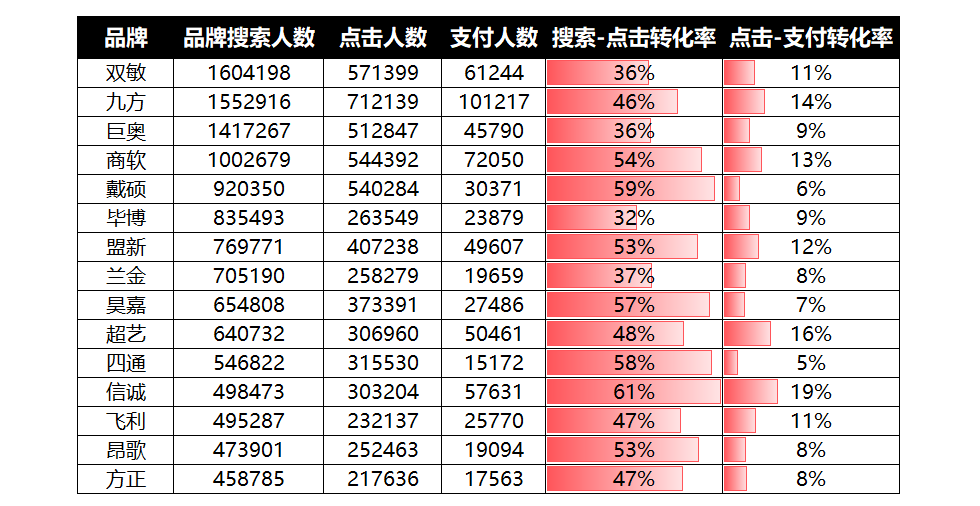
结果显而易见,高搜索量级的品牌,主要呈现出两种形态:
以双敏(排名第1)、巨奥(排名第3)为代表的品牌主要分布在第三区间,量级较大,但两种转化效率均需要进一步提升,品牌没能较好的承接蜂拥而至的流量。
九方(排名第2)、商软(排名第4)则是高搜索量级、高转化效率的代表,从现有数据看,他们才是不吹牛集团学习的榜样。
正当我们准备把这一步结果同步给首席吹牛官,顺便探讨进一步的数据分析方向,比如结合支付人数的金额贡献、留存率、LTV,以及引入两年增速的维度,结合业务动作来定位深层原因。
没想到首席吹牛官发来了这样的消息:
“第二个需求我可能没说清楚,这次不仅是表彰,也是给融资机构秀肌肉的一部分,我们关注的只是品牌声量,对应的就是品牌搜索人数这个指标,你汇总好排个序就好”
我们每个人会说超过5种语言的脏话,但在这个场景,大部分人只能条件反射般的打出这8个字:
“嗯嗯,好的,马上给到”
实例故事告一段落,上述数据维度和验证角度,大家可以做更多的探索。
相关数据源和代码已经打包好,公众号后台回复“品牌数据”即可获取。
文末福利

怎么获取呢?
扫码添加早小起微信,备注 "速查表" 获取