 3D视觉工坊
3D视觉工坊




点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

前段时间有思考过结合3D信息来辅助多目标跟踪任务,不过效果没有达到我的预期。一方面是多目标跟踪相关数据集除了KITTI之外缺乏多任务标注信息,另一方面单目深度估计对于密集拥挤人群的效果很差。所以我觉得对于稀疏场景、车辆跟踪或者提供真实3D信息和相机信息的场景任务更有意义。下面的总结主要是我2019年初整理的文献,时效性可能还没跟上。很多图都是我从我之前整理的word里面复制出来的,所以有些模糊,想看的话可以自行搜索相关论文。
1、任务介绍





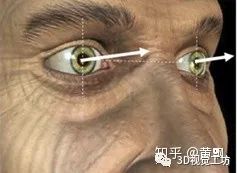

2、数据集介绍
2.1 KITTI

2.2vKITTI

2.3Cityscapes

2.4NYU Depth V2

2.5 ScanNet

2.6Make3D

3、数据处理
3.1数据组成
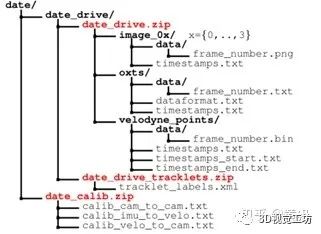

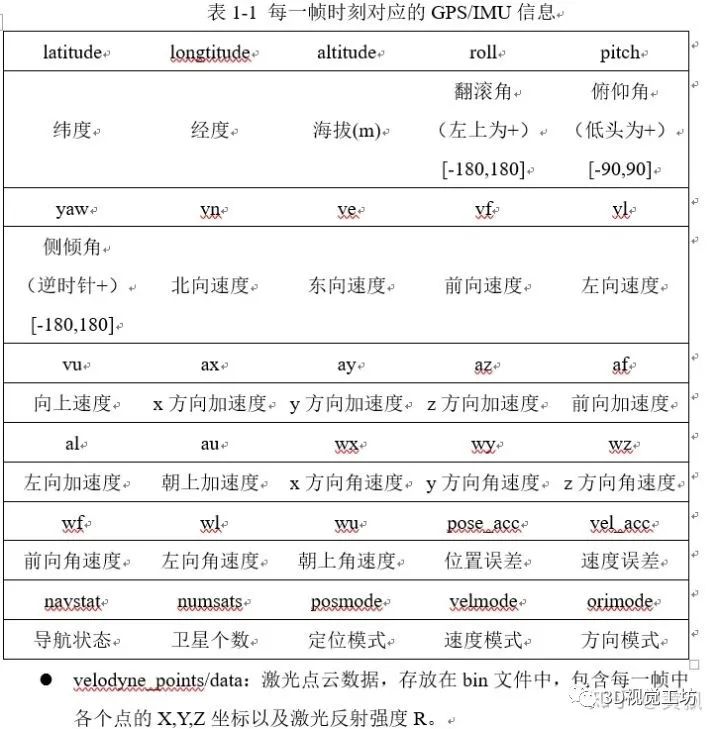

 对于GPS/imu中的点G:[X,Y,Z]^T,将其转化为相机左视图的像素点坐标Q:
对于GPS/imu中的点G:[X,Y,Z]^T,将其转化为相机左视图的像素点坐标Q: 其中最需要注意的是第一个公式,用于深度的信息的提取,以及P_rect_xx,其前三列数据为修正后的相机内参。
其中最需要注意的是第一个公式,用于深度的信息的提取,以及P_rect_xx,其前三列数据为修正后的相机内参。3.2 数据处理
 由于深度信息的转换需要用到相机内参,所以对于图像的缩放需要先处理,假如图像大小的放缩尺度为[zoom_x,zoom__y],那么相机内参的变化如下:
由于深度信息的转换需要用到相机内参,所以对于图像的缩放需要先处理,假如图像大小的放缩尺度为[zoom_x,zoom__y],那么相机内参的变化如下: 根据世界坐标系的转换:
根据世界坐标系的转换: 由于要求点云数据的反射强度为1,所以需要先将点云数据的反射强度置为1:
由于要求点云数据的反射强度为1,所以需要先将点云数据的反射强度置为1: 最后我们只需要保留满足图像边界约束的点的深度信息,如果映射得到的点坐标相同,则只保留深度更小的。
最后我们只需要保留满足图像边界约束的点的深度信息,如果映射得到的点坐标相同,则只保留深度更小的。·随机水平翻转,所以需要改变相机内参的水平平移量cx=w-cx; ·随机尺度变换并剪切至固定大小:

3.3评价指标

4 相关工作
4.1基于单目视觉的深度估计
深度估计任务是从二维图像到二维深度图像的预测,因此整个过程是一个自编码过程,包含编码和解码,通俗点就是下采样和上采样。这类结构主要有FCN框架和U-net框架,二者的下采样过程都是利用了卷积和池化,而上采样利用了逆卷积/转置卷积(Deconvolution)和upsample。
早期的单目深度估计网络框架基本上都是直接利用了上面所提到的两个基础框架进行了预测,为了让这类框架更好的应用于深度估计问题,一般都从以下几个方面着手:更好的backbone模型、多尺度、更深的网络。
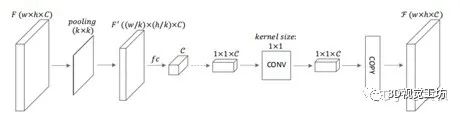
以3DV 2016中《Deeper Depth Prediction with Fully Convolutional Residual Networks》一文为例,其提出了FCRN网络框架:
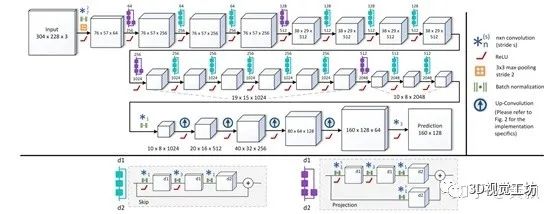
其网络框架主体是基于Resnet-50,在上采样过程中采用了独特的方式,将逆卷积用up-pooing+conv的方式替代了,将Resnet中的project模块进行了一定的改进。
其中上采样过程中将特征图利用0元素进行填充,然后利用一类特殊的卷积核进行特征提取,这一过程可以先卷积,然后错位相连得到,原理如下:
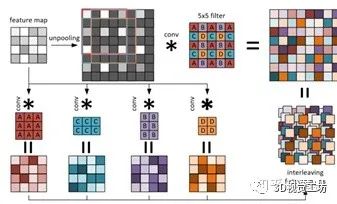

将深度估计问题变为回归问题的缺点在于,太依赖于数据集的场景,并且由于图像中深度往往是分层的,类似于等高线之类的,所以也有学者将深度估计变为一个分类问题,而类别数就是将最远实际距离划分为多份而制作的。
以此为代表的是CVPR2018中《Deep Ordinal Regression Network for Monocular Depth Estimation》所提出的DORN框架:
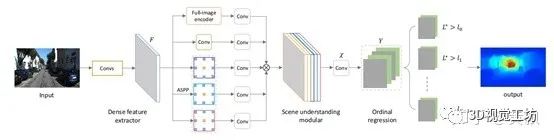
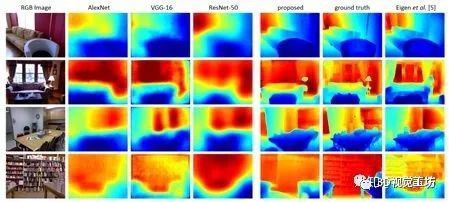
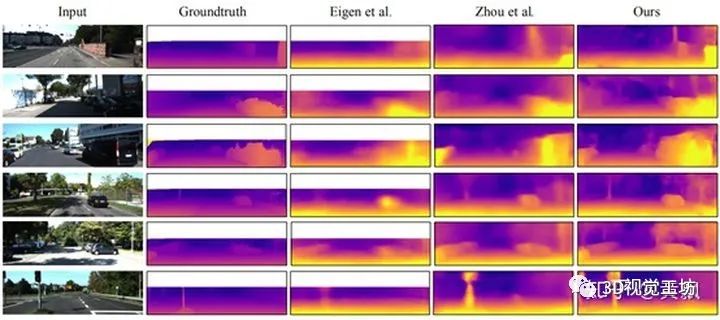
其效果如下:

无论是回归还是分类,都是以深度信息作为标签的监督算法,因此其受限于训练集场景,仅限于刷榜。
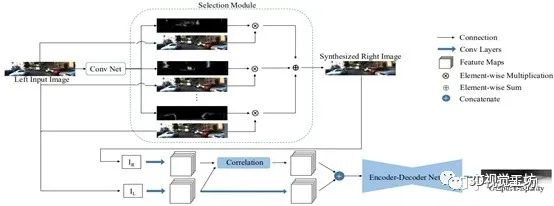
4.2结合双目视觉的单目深度估计
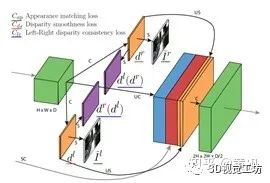
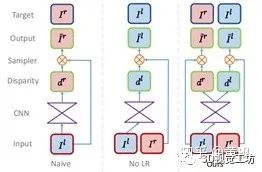
 其中SSIM指的是结构相似性。
其中SSIM指的是结构相似性。

由于其主要在KITTI_outdoor和Cityscapes上训练的,所以对于室外场景效果会略好,又因为其算法框架比较简单,所以深度信息中的细节比较模糊,尤其是存在遮挡或者物体相连的情况时。测试效果如下:

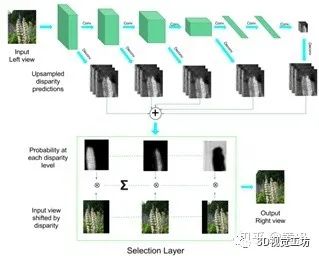


4.3基于视频的相机位姿估计和视觉测距
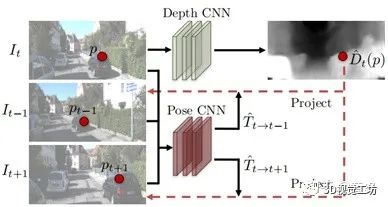
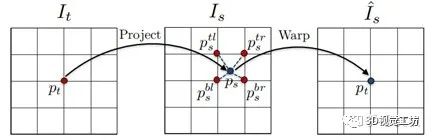


 l指的是尺度,s指的是图片,其中的平滑性约束跟上一节所讲的Monodepth一样,由于解释性掩膜无标签,如果不加约束的话会自动为0,所以利用交叉熵损失函数对其进行了约束,默认为全1矩阵。其效果如下:
l指的是尺度,s指的是图片,其中的平滑性约束跟上一节所讲的Monodepth一样,由于解释性掩膜无标签,如果不加约束的话会自动为0,所以利用交叉熵损失函数对其进行了约束,默认为全1矩阵。其效果如下:

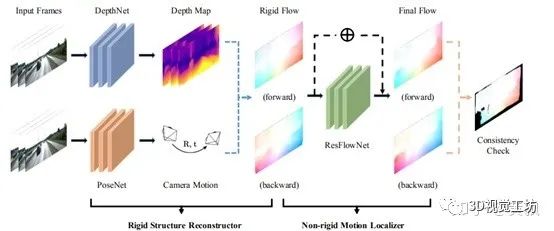



4.4基于图像风格迁移的单目深度估计
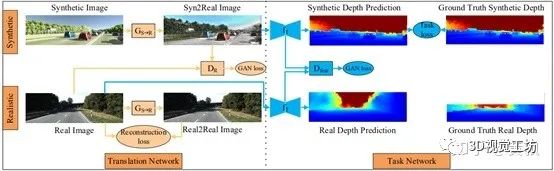
·由真实图像风格迁移生成的图像预原始图像的重构误差,这一部分计算L1 Loss; ·由合成图像风格迁移生成的图像与原始图像的编码特征的GAN Loss。


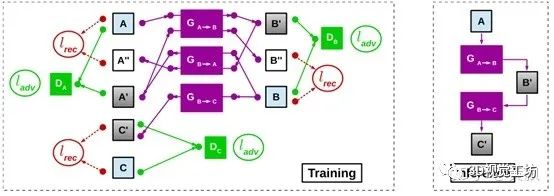


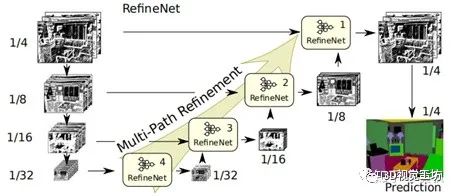
4.5多任务深度估计
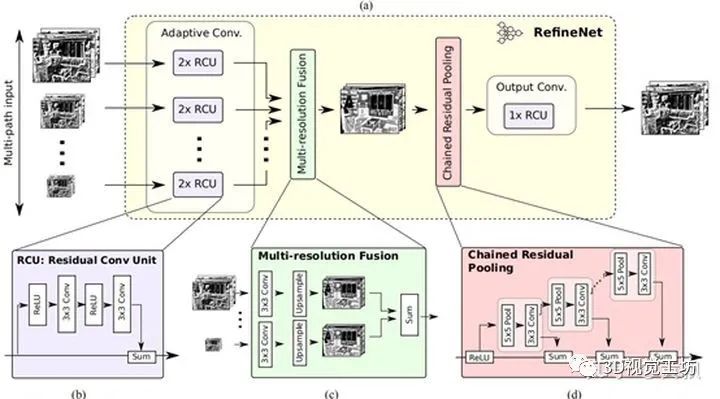

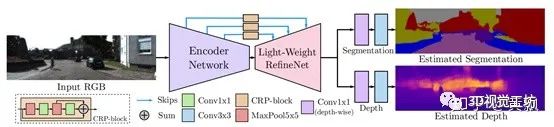


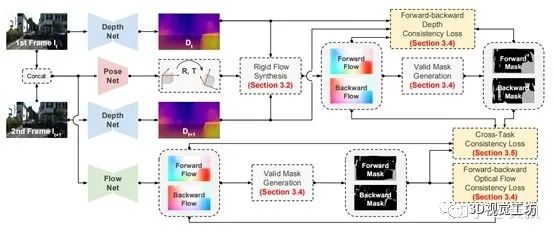

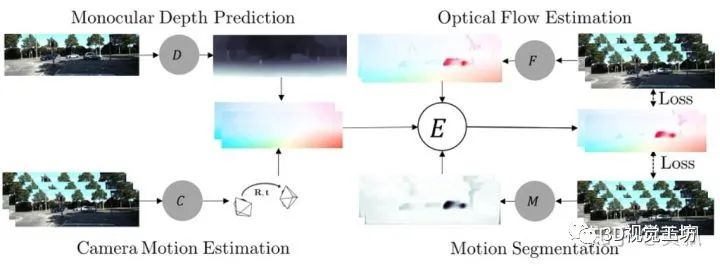
5、总结


6、参考文献
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿 
▲长按关注公众号
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 
圈里有高质量教程资料、可答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~ 

