 程序员的成长之路
程序员的成长之路





阅读本文大概需要 12 分钟。
来自:网络
本篇文章主要内容
数据缓存 为何要使用缓存 哪类数据适合缓存 缓存的利与弊 如何保证缓存和数据库一致性 不更新缓存,而是删除缓存 先操作缓存,还是先操作数据库 非要保证数据库和缓存数据强一致该怎么办 缓存和数据库一致性实战 实战:先删除缓存,再更新数据库 实战:先更新数据库,再删缓存 实战:缓存延时双删 实战:删除缓存重试机制 实战:读取binlog异步删除缓存
数据缓存
为何要使用缓存
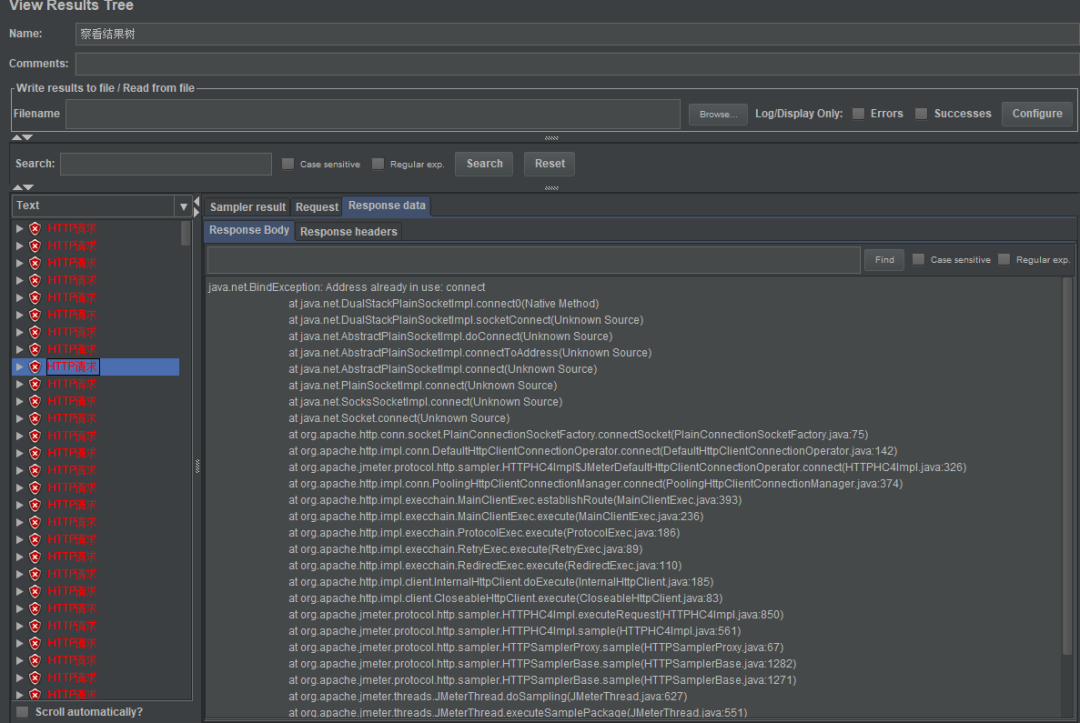
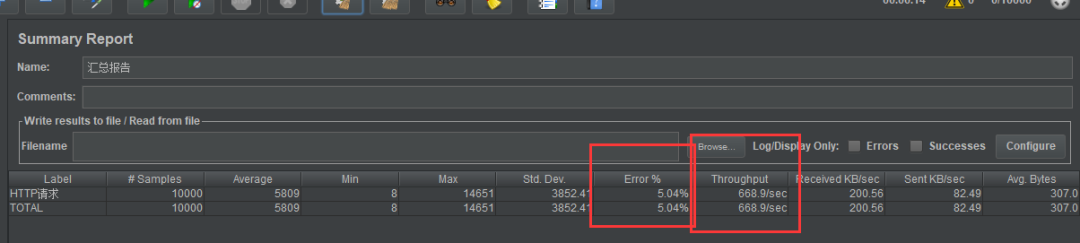
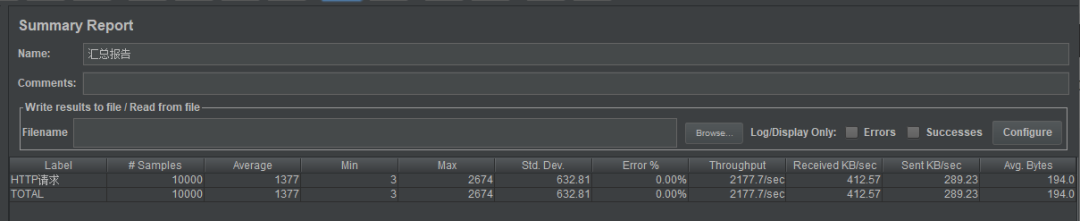
需要声明的是,我的测试并不严谨,只是作对比测试,不要作为实际服务性能的参考。
/**
* 查询库存:通过数据库查询库存
* @param sid
* @return
*/
@RequestMapping("/getStockByDB/{sid}")
@ResponseBody
public String getStockByDB(@PathVariable int sid) {
int count;
try {
count = stockService.getStockCountByDB(sid);
} catch (Exception e) {
LOGGER.error("查询库存失败:[{}]", e.getMessage());
return "查询库存失败";
}
LOGGER.info("商品Id: [{}] 剩余库存为: [{}]", sid, count);
return String.format("商品Id: %d 剩余库存为:%d", sid, count);
}
/**
* 查询库存:通过缓存查询库存
* 缓存命中:返回库存
* 缓存未命中:查询数据库写入缓存并返回
* @param sid
* @return
*/
@RequestMapping("/getStockByCache/{sid}")
@ResponseBody
public String getStockByCache(@PathVariable int sid) {
Integer count;
try {
count = stockService.getStockCountByCache(sid);
if (count == null) {
count = stockService.getStockCountByDB(sid);
LOGGER.info("缓存未命中,查询数据库,并写入缓存");
stockService.setStockCountToCache(sid, count);
}
} catch (Exception e) {
LOGGER.error("查询库存失败:[{}]", e.getMessage());
return "查询库存失败";
}
LOGGER.info("商品Id: [{}] 剩余库存为: [{}]", sid, count);
return String.format("商品Id: %d 剩余库存为:%d", sid, count);
}
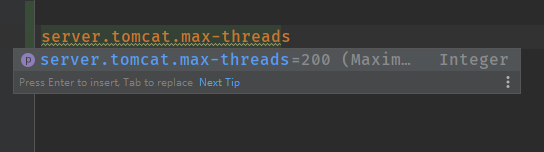
server.tomcat.max-threads=10000
server.tomcat.max-connections=10000
哪类数据适合缓存
缓存的利与弊
能够缩短服务的响应时间,给用户带来更好的体验。 能够增大系统的吞吐量,依然能够提升用户体验。 减轻数据库的压力,防止高峰期数据库被压垮,导致整个线上服务BOOM!
缓存有多种选型,是内存缓存,memcached还是redis,你是否都熟悉,如果不熟悉,无疑增加了维护的难度(本来是个纯洁的数据库系统)。 缓存系统也要考虑分布式,比如redis的分布式缓存还会有很多坑,无疑增加了系统的复杂性。 在特殊场景下,如果对缓存的准确性有非常高的要求,就必须考虑缓存和数据库的一致性问题。
如何保证缓存和数据库一致性
不更新缓存,而是删除缓存
原因一:线程安全角度 同时有请求A和请求B进行更新操作,那么会出现 (1)线程A更新了数据库 (2)线程B更新了数据库 (3)线程B更新了缓存 (4)线程A更新了缓存 这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。 原因二:业务场景角度 有如下两点: (1)如果你是一个写数据库场景比较多,而读数据场景比较少的业务需求,采用这种方案就会导致,数据压根还没读到,缓存就被频繁的更新,浪费性能。 (2)如果你写入数据库的值,并不是直接写入缓存的,而是要经过一系列复杂的计算再写入缓存。那么,每次写入数据库后,都再次计算写入缓存的值,无疑是浪费性能的。显然,删除缓存更为适合。
先操作缓存,还是先操作数据库
对于一个不能保证事务性的操作,一定涉及“哪个任务先做,哪个任务后做”的问题,解决这个问题的方向是:如果出现不一致,谁先做对业务的影响较小,就谁先执行。 假设先淘汰缓存,再写数据库:第一步淘汰缓存成功,第二步写数据库失败,则只会引发一次Cache miss。 假设先写数据库,再淘汰缓存:第一步写数据库操作成功,第二步淘汰缓存失败,则会出现DB中是新数据,Cache中是旧数据,数据不一致。
先删缓存,再更新数据库 该方案会导致请求数据不一致 同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形: (1)请求A进行写操作,删除缓存 (2)请求B查询发现缓存不存在 (3)请求B去数据库查询得到旧值 (4)请求B将旧值写入缓存 (5)请求A将新值写入数据库 上述情况就会导致不一致的情形出现。而且,如果不采用给缓存设置过期时间策略,该数据永远都是脏数据。
先更新数据库,再删缓存这种情况不存在并发问题么? 不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生 (1)缓存刚好失效 (2)请求A查询数据库,得一个旧值 (3)请求B将新值写入数据库 (4)请求B删除缓存 (5)请求A将查到的旧值写入缓存 ok,如果发生上述情况,确实是会发生脏数据。 然而,发生这种情况的概率又有多少呢? 发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
我非要数据库和缓存数据强一致怎么办
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性
缓存延时双删
(1)先淘汰缓存 (2)再写数据库(这两步和原来一样) (3)休眠1秒,再次淘汰缓存 这么做,可以将1秒内所造成的缓存脏数据,再次删除。
针对上面的情形,读者应该自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
ok,在这种情况下,造成数据不一致的原因如下,还是两个请求,一个请求A进行更新操作,另一个请求B进行查询操作。 (1)请求A进行写操作,删除缓存 (2)请求A将数据写入数据库了, (3)请求B查询缓存发现,缓存没有值 (4)请求B去从库查询,这时,还没有完成主从同步,因此查询到的是旧值 (5)请求B将旧值写入缓存 (6)数据库完成主从同步,从库变为新值 上述情形,就是数据不一致的原因。还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
ok,那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
删缓存失败了怎么办:重试机制
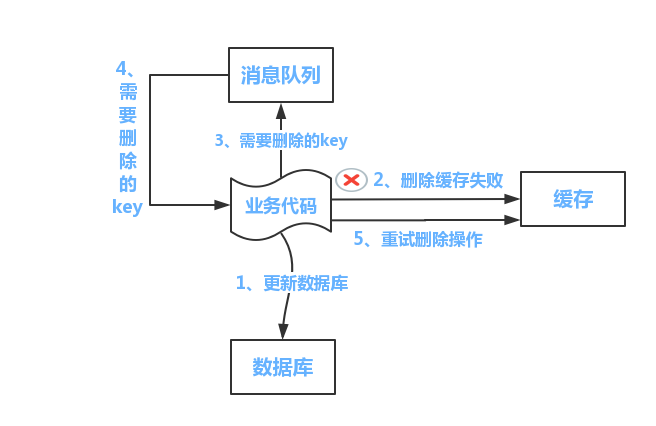
流程如下所示 (1)更新数据库数据; (2)缓存因为种种问题删除失败 (3)将需要删除的key发送至消息队列 (4)自己消费消息,获得需要删除的key (5)继续重试删除操作,直到成功 然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
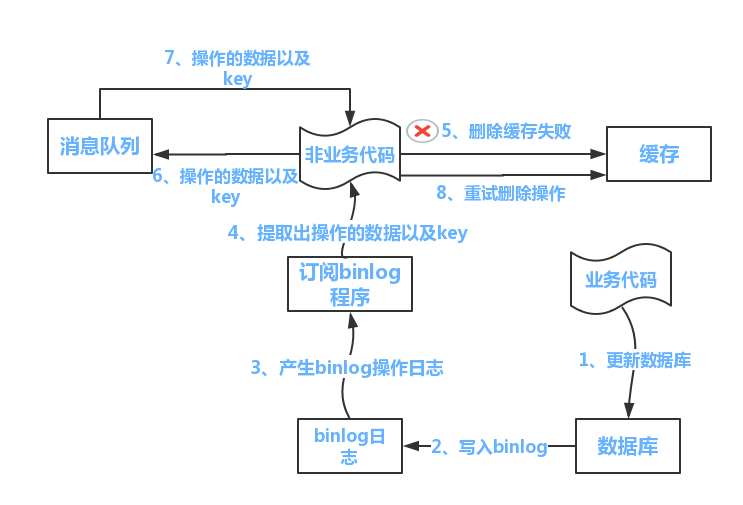
流程如下图所示: (1)更新数据库数据 (2)数据库会将操作信息写入binlog日志当中 (3)订阅程序提取出所需要的数据以及key (4)另起一段非业务代码,获得该信息 (5)尝试删除缓存操作,发现删除失败 (6)将这些信息发送至消息队列 (7)重新从消息队列中获得该数据,重试操作。
扩展阅读
Cache aside Read through Write through Write behind caching,这里有陈皓的总结文章可以进行学习。
小结
分布式系统里要么通过2PC或是Paxos协议保证一致性,要么就是拼命的降低并发时脏数据的概率 缓存系统适用的场景就是非强一致性的场景,所以它属于CAP中的AP,BASE理论。 异构数据库本来就没办法强一致,只是尽可能减少时间窗口,达到最终一致性。 还有别忘了设置过期时间,这是个兜底方案
结束语
对于读多写少的数据,请使用缓存。 为了保持数据库和缓存的一致性,会导致系统吞吐量的下降。 为了保持数据库和缓存的一致性,会导致业务代码逻辑复杂。 缓存做不到绝对一致性,但可以做到最终一致性。 对于需要保证缓存数据库数据一致的情况,请尽量考虑对一致性到底有多高要求,选定合适的方案,避免过度设计。
推荐阅读:

微信扫描二维码,关注我的公众号
朕已阅 

