
【NLP】不讲武德,只用标签名就能做文本分类
共 2795字,需浏览 6分钟
· 2021-01-23

文 | 谁动了我的炼丹炉
编 | 兔子酱
今天给大家介绍一篇微软研究院在EMNLP2020上发表的论文,主题是弱监督文本分类。看到标题的你可能会和我刚开始一样震惊,只是知道标签名怎么给文本分类呢?是的,虽然听起来不可思议,但看完下面的解读你会发现论文的思路是如此简单和精妙。
论文题目:
Text Classification Using Label Names Only: A Language Model Self-Training Approach
论文链接:
https://arxiv.org/pdf/2010.07245
Github:
https://github.com/yumeng5/LOTClass
 方法
方法
首先,概括一下这篇论文的核心思想,简单来说,就是先通过人的先验知识来为每个类别设定几个代表性的关键词,也就是论文中说的Label Names,你没看错,只需要知道有哪些类别和每个类别有哪些关键词,而不需要知道每条样本的标签!!然后通过基于预训练模型的方法来筛选掉一些低质量的语料,用剩余的精挑细选的语料来支撑后面的语言模型任务;最后通过自训练的方法充分利用大量不含关键词的样本,提高模型性能。下面我们再详细介绍这种方法的各个步骤。
设定关键词
事先给每一个类别选一些你认为对目标类别重要的一些代表性的关键词。比如通过文本判断描述的是什么动物,对于目标类别“鼠”,我们可以提出一系列关键词,“耗子”、“老鼠”。通过关键词匹配,我们可能会得到下面的语料。(1) 老鼠是哺乳纲、啮齿目的动物。(2) 耗子的体型较小,体型小,繁殖快。(3) 年轻人耗子尾汁。这一步在论文中并没有特别强调,但其实这是至关重要的一步,因为正是这一步为后面提供了一批粗糙的数据。
筛选正确的样本
可以看到,经过关键词匹配的样本中可能包含大量的错误样本,比如上面的(3),那怎么过滤掉这种样本呢?作者提出了一种方法,流程如下:首先创建一个类别词库,即根据每一个类别的类别名选出该类别的关键词表。建立类别词库要用到预训练语言模型BERT,利用关键词位置的上下文embedding向量预测整个词库各个单词的概率分布。
对于(2)中关键词“耗子”,可能排在前面的是“耗子”、“鼠科”、“老鼠”。但对于(3)中关键词“耗子”,排在前面的就可能是“武德”、“大力士”、“大E”。
很显然,(3)的目标类别就不是“鼠”,但这种词也是少数,毕竟我们在选关键词的时候肯定会选择能代表目标类别的词。如果文本中出现类别名,利于预训练模型的通用知识预测该类别名位置的可能出现的词,选出概率最高的top50的词作为候选词,然后选择频次排名前100的词来组成该类别的关键词库(注意这其中不能有停止词,也不能有同时属于多个类别的词)。
构建好了类别词库之后,我们就能用它来筛选掉一些含关键词的错误样本,做法也很简单。如图所示,对于样本中某个关键词,将其上下文embedding向量传进MLM head,得到预测出来的单词分布,如果top50里有20个以上的单词出现在类别词库中,就算是正确样本(这里的超参可以根据酌情调整,来控制约束力度)。
我们对(3)使用这种方法,发现top50的关联词里一个出现在类别词库的词都没有,因此(3)不是属于目标类别的样本;文中把能指代目标类别含义的关键词称为类别提示词(category-indicative)。
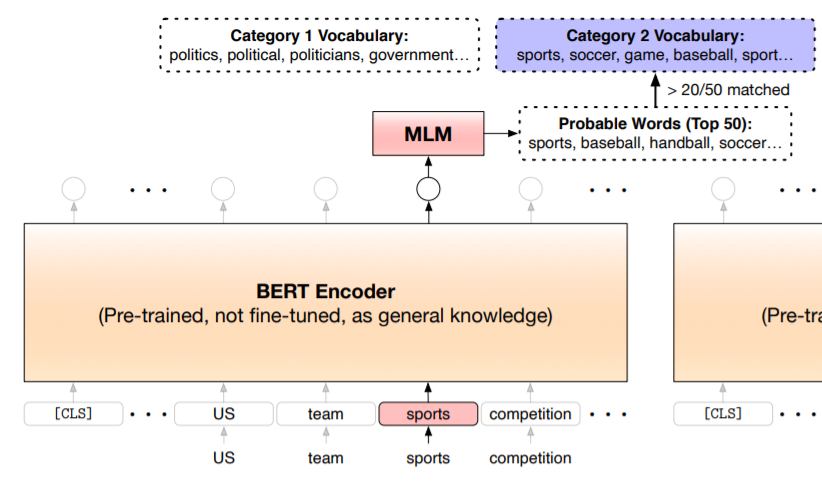
Masked Category Prediction
通过上一步,我们已经得到了一批精挑细选的带类别提示词的样本,如何利用这些样本呢?本文提出了一个MCP任务用于 fine tuning 我们的模型。
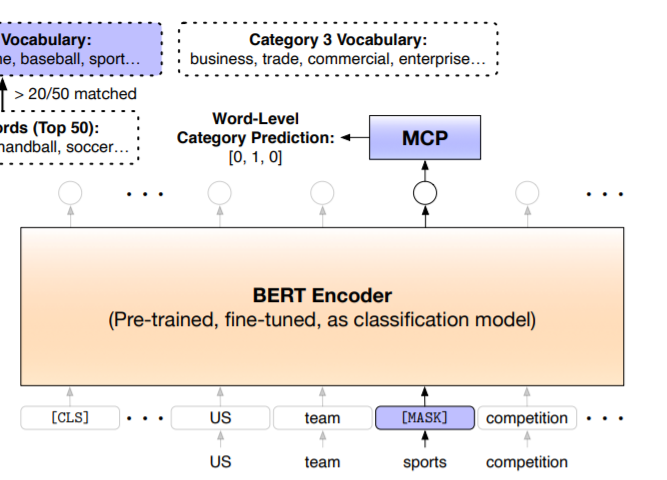
如图所示,这里跟前面预测单词分布一样,将类别提示词的上下文embedding向量传进MCP head(全连接+softmax),来预测类别提示词的目标类别。注意,这里需要先Mask掉类别提示词然后进行预测。为什么这里需要Mask但前面却不用呢?道理很简单。如果不Mask掉类别提示词那么任务就太简单了,而我们希望模型能学习到更多的上下文信息。前面在构建类别词库的时候不需要Mask,是因为那只是一个预测过程,只用关注预测结果的正确性。
自训练
我们很容易能发现,被关键词匹配到的样本毕竟还是少数,大量无关键词的样本也不能就这样浪费啊。因此作者还使用自训练的方法在无关键词样本上训练,自训练的目标函数可以用KL散度来表示。
K代表类别数量,这里的q是类别概率的目标分布,p是预测分布。q的取值有两种选择:(1) Hard Labeling:概率最大的类别取1,其他为0;(2) Soft Labeling :
实验下来(2)的效果更好。由于自训练是通过[CLS]的embedding向量来进行预测的,因此它不仅让大量的无关键词数据得到利用,还弥补了MCP任务没有用到[CLS]进行训练的短板。
实验结果
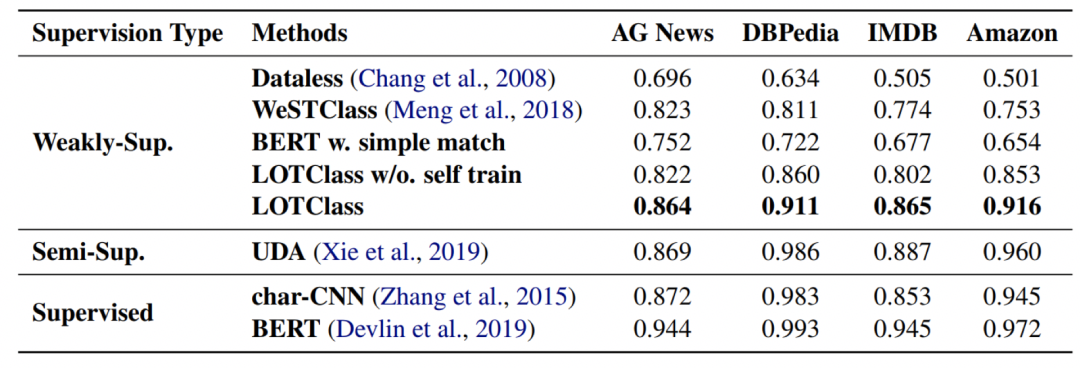 从表中我们可以看到,本文提出的方法在四个数据集上相比其他弱监督方法有很大的提升,并且自训练的作用看来也是非常显著,比不使用自训练提升了约5个点。并且论文的第5节还提到,所用的方法还有进一步提升的手段。包括使用更先进的预训练模型,为每个类别设置更多关键词(文中每个类别对应3个关键词),以及使用数据增强。
从表中我们可以看到,本文提出的方法在四个数据集上相比其他弱监督方法有很大的提升,并且自训练的作用看来也是非常显著,比不使用自训练提升了约5个点。并且论文的第5节还提到,所用的方法还有进一步提升的手段。包括使用更先进的预训练模型,为每个类别设置更多关键词(文中每个类别对应3个关键词),以及使用数据增强。
思考和小结
看完上面的文字,明白了作者提出的方法是属于弱监督学习中的不准确监督学习,使用BERT预训练模型构建类别词库的方法来找出错误样本。同时还用到了自训练的方法利用无标注样本,让模型的性能得到进一步提升。整套流程还是很系统的,有参考的价值。
[1]Y Meng,Y Zhang,J Huang,C Xiong,J Han. 2020. Text Classification Using Label Names Only: A Language Model Self-Training Approach. In Proceedings of EMNLP.
[2]Junyuan Xie, Ross B. Girshick, and Ali Farhadi. 2016. Unsupervised deep embedding for clustering analysis. In ICML.
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码:
