
2020年这10大ML、NLP研究最具影响力:为什么?接下来如何发展?
选自ruder.io
去年有哪些机器学习重要进展是你必须关注的?听听 DeepMind 研究科学家怎么说。

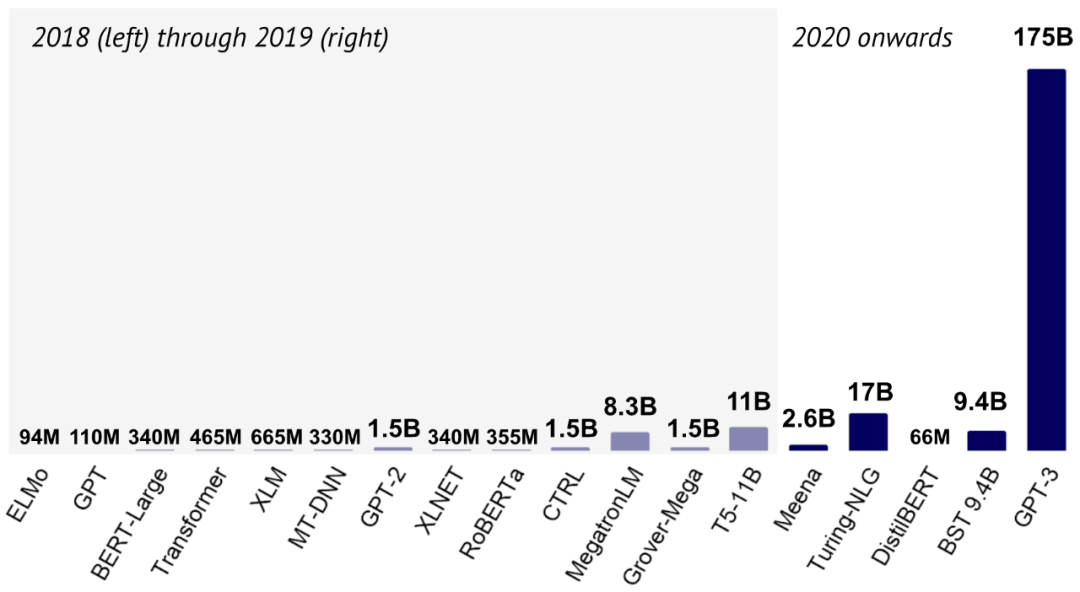
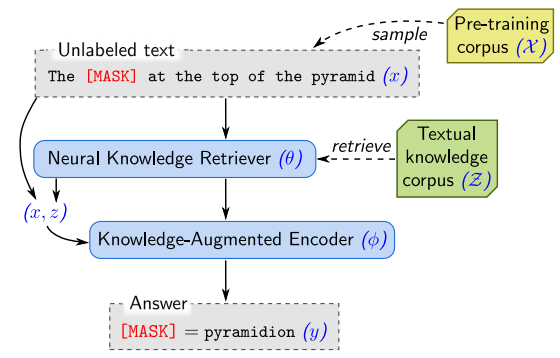



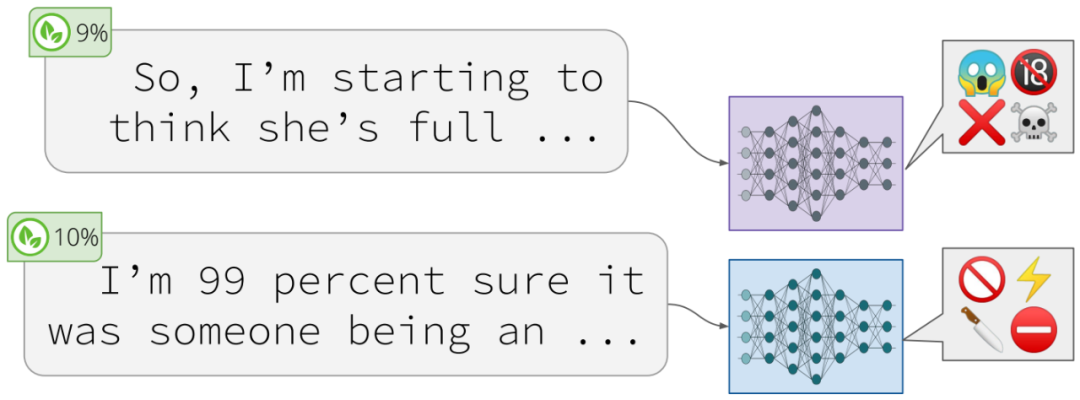
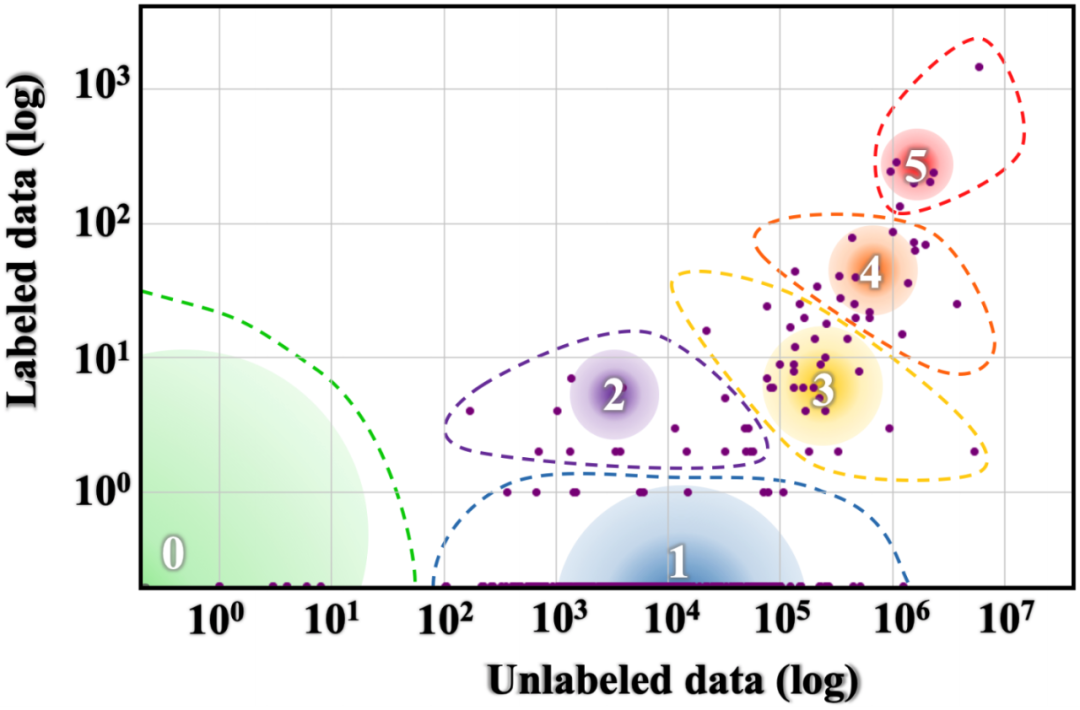
SQuAD: XQuAD (Artetxe et al., 2020), MLQA (Lewis et al., 2020), FQuAD (d'Hoffschmidt et al., 2020);
Natural Questions: TyDiQA (Clark et al., 2020), MKQA (Longpre et al., 2020);
MNLI: OCNLI (Hu et al., 2020), FarsTail (Amirkhani et al., 2020);
the CoNLL-09 dataset: X-SRL (Daza and Frank, 2020);
the CNN/Daily Mail dataset: MLSUM (Scialom et al., 2020)。

© THE END
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码:
评论