 极市平台
极市平台





极市导读
本文介绍了作者一篇最新的TPAMI关于无监督多类域适应的工作,提出了Multi-Class Scoring Disagreement (MCSD) divergence来衡量两个域数据分布之间的差异。算法方面基于MCSD divergence 的理论,提出了一套新的代码框架McDalNets。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
输入有标签的源域数据和无标签的目标域数据,输出一个适用于目标域的模型。源域和目标域假设任务相同但是数据分布不同
找到一个特征空间,将分布不同的源域和目标域数据映射到该特征空间后,希望源域和目标域的数据分布差异尽可能小;这样基于源域数据训练的模型,就可以用于目标域数据上
理论方面:提出了Multi-Class Scoring Disagreement (MCSD) divergence来衡量两个域数据分布之间的差异;其中MCSD可以充分衡量两个scoring hypotheses(可以理解为分类器) 之间的差异。基于MCSD divergence, 我们提出了新的Adaptation Bound, 并详细讨论了我们理论框架和之前框架的关系。 算法方面:基于MCSD divergence 的理论,我们提出了一套新的代码框架Multi-class Domain-adversarial learning Networks (McDalNets)。McDalNets的不同实现与近期的流行方法相似或相同,因此从理论层面支撑了这些方法 [2,3,4,5]。此外,我们提出了一个新的算法SymmNets-V2, 该方法是我们之前会议工作[3]的改进版本。 实践方面:我们在closed set, partial, and open set 三种实验设置下验证了我们提出方法的有效性。代码链接:https://github.com/YBZh/MultiClassDA
理论方面:

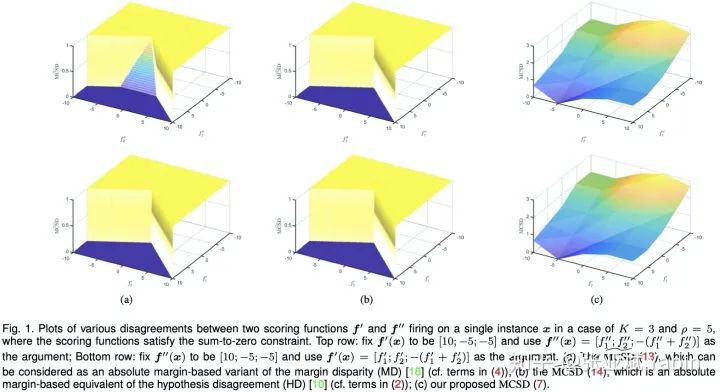
理论角度:MCSD可以充分度量两个scoring functions 的差异!!同时导出后续的bound.
算法角度:对scoring functions 的差异的充分度量可以直接支撑基于分类器进行对抗训练的方法[2,3,4,5].
 采用0-1二值loss只衡量了
采用0-1二值loss只衡量了  的最终类别预测是否一致。
的最终类别预测是否一致。相对
, 通过引入margin 在0和1之间做了一个平滑的过渡。
通过引入margin 在0和1之间做了一个平滑的过渡。以上两者都只考虑了scoring functions的部分输出,
 首次将scoring functions 的所有输出值加以考虑。故而MCSD可以充分度量scoring functions 的差异。
首次将scoring functions 的所有输出值加以考虑。故而MCSD可以充分度量scoring functions 的差异。
算法方面:
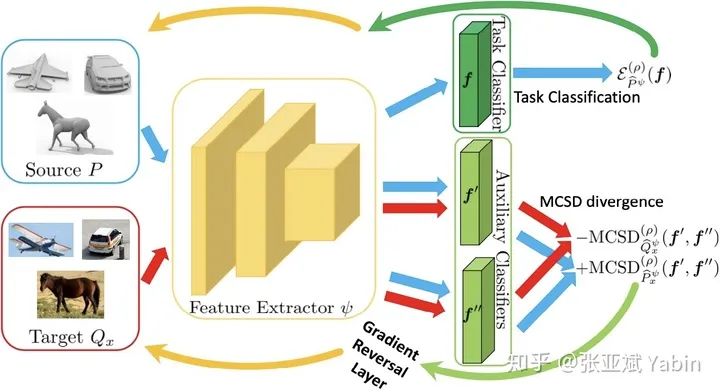
当 在domain 上的输出越趋于一致,替代度量方法的值越小 当 在domain 上的输出越差异越大,替代度量方法的值越大

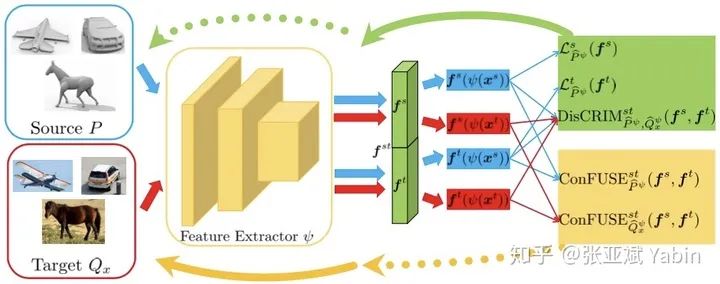
实践方面:

推荐阅读




