
Python爬虫 | 爬虫基础入门看这一篇就够了
共 5619字,需浏览 12分钟
· 2021-01-18
腾讯课堂 | Python网络爬虫与文本分析(现在只需198元)~~

大家好,今天我们来聊聊Python爬虫的基础操作,反正我是这样入门了,哈哈。

其实,一开始学python的时候,我是冲着数据处理分析去了,那个pandas什么的。后来,发现爬虫挺好玩,可以解决纯手工采集网上数据的繁琐问题,比如我用的比较多的爬取taptap某游戏评价内容、某视频网站某剧的弹幕、某评的店铺信息、某牙主播信息等等。

关于爬虫,我也只会一些比较基础的操作,不过个人经验上感觉这些基础基本可以满足比较常规化的需求。对于进阶的爬虫技巧,大家在了解熟悉爬虫基础后自然会有进阶学习的思路与途径。
接下来,我们进入主题吧~
0.爬虫基础流程
把爬虫的过程模块化,基本上可以归纳为以下几个步骤:
[√] 分析网页URL:打开你想要爬取数据的网站,然后寻找真实的页面数据URL地址; [√] 请求网页数据:模拟请求网页数据,这里我们介绍 requests库的使用;[√] 解析网页数据:根据请求获得的网页数据我们用不同的方式解析成我们需要用的数据(如果网页数据为html源码,我们用 Beautiful Soup、xpath和re正则表达式三种解析;若网页数据为json格式,我们可以直接用字典列表等基础知识处理)[√] 存储网页数据:一般来说,解析后的数据是比较结构化的,可以保存为txt、csv、json或excel等文本,亦或者可以存储在数据库如MySql、MongoDB或SqlLite中。
1.分析网页URL
当我们有一个目标网站,有时候会发现对于静态网页,我们只需要把网页地址栏中的URL传到get请求中就可以直接取到网页的数据。但如果这是动态网页,我们便无法通过简单的传递网页地址栏的URL给get请求来获取网页数据,往往这个时候,我们进行翻页的时候还会发现网页地址栏中的URL是不会发生变化的。
接下来,我们来分别介绍这两种情况下如何获取真实的页面数据URL地址。
1.1 静态网页
对于静态网页来说,其实网页地址栏中的URL就是我们需要的。
以 贝壳二手房网(https://bj.ke.com/ershoufang/) 为例,我们可以看到进行翻页(如到第2页)的时候网页地址栏的URL变为了(https://bj.ke.com/ershoufang/pg2/)。类型这种情况,多半就是静态网页了,而且翻页的URL规律十分明显。
1.2 动态网页
对于动态网页来说,我们一般可以通过以下几个步骤找到真实URL地址:
需要按“F12”进入到浏览器的开发者模式; 点击“Network”—>XHR或JS或者你全部查找看; 进行翻页(可能是点击下一页或者下滑加载更多); 观察第2步中name模块的内容变化,寻找。
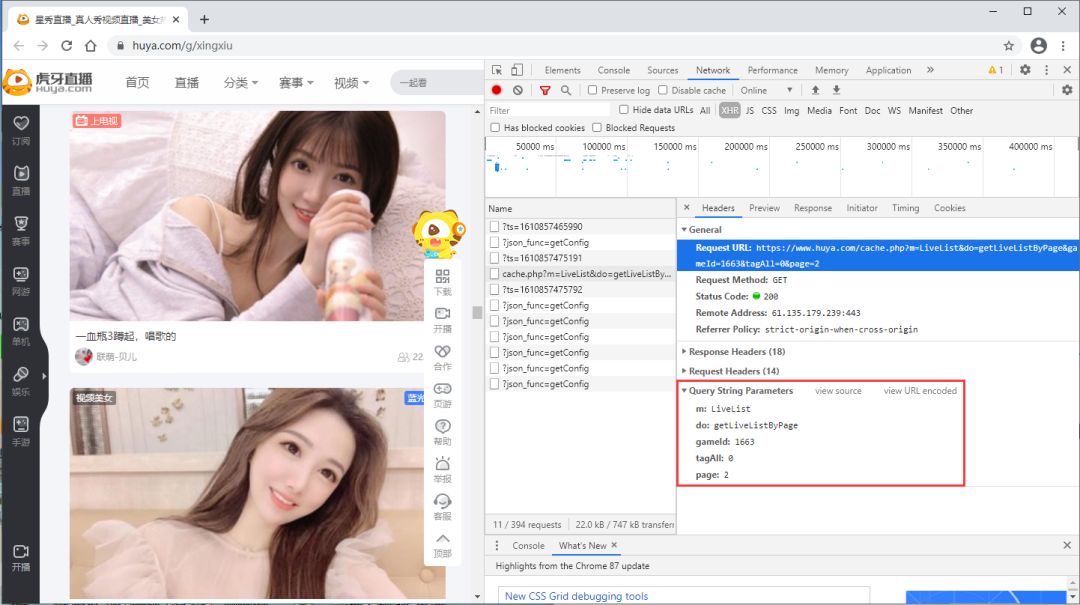
以 虎牙星秀区(https://www.huya.com/g/xingxiu) 为例,我们可以看到进行翻页(如到第2页)的时候网页地址栏的URL没有发生任何改变。
为了便于找到真实的URL地址,我们可以在开发者模式中找以下截图中的几点,preview是预览结果,可以便于我们进行匹配定位具体的Name。

当我们定位到具体的Name后,右侧选择Headers可以查看到请求网页需要的相关参数信息,而且比较好拟清其变化规律。以虎牙星秀为例,其真实URL地址及变化规律如下:
URL= 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=2'
基础 url 地址如下:
url = 'https://www.huya.com/cache.php’请求参数parames如下:
parames = {
'm': 'LiveList',
'do': 'getLiveListByPage',
'gameId': 1663,
'tagAll': 0,
'page': 2, # 翻页变化的就是这个参数
}
2.请求网页数据
当我们确定了真实数据的URL后,这里便可以用requests的get或post方法进行请求网页数据。
关于requests库的更多使用方式,大家可以前往(https://requests.readthedocs.io/zh_CN/latest/)查看。
2.1 发送get请求
In [1]: import requests
In [2]: url = 'https://bj.ke.com/ershoufang/'
In [3]: r = requests.get(url)
In [4]: type(r)
Out[4]: requests.models.Response
In [5]: r.status_code
Out[5]: 200
我们得到的是一个Response对象,如果我们想要获取网页数据,可以使用text或content属性来获取,另外如果获取的网页数据是json格式的则可以使用Requests 中内置的 **json()**解码器方法,助你处理json 数据。
r.text:字符串类型的数据,一般网页数据为文本类用此属性 r.content:二进制类型的数据,一般网页数据为视频或者图片时用此属性 r.json():json数据解码,一般网页数据为json格式时用此方法
对于一些动态网页,请求的网址是基础url和关键字参数组合而成,这个时候我们可以使用 params 关键字参数,以一个字符串字典来提供这些参数。
In [6]: url = 'https://www.huya.com/cache.php'
...: parames = {
...: 'm': 'LiveList',
...: 'do': 'getLiveListByPage',
...: 'gameId': 1663,
...: 'tagAll': 0,
...: 'page': 2, # 翻页变化的就是这个参数
...: }
...:
...: r = requests.get(url, params=parames)
In [7]: r.url
Out[7]: 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=2'
2.2 发送post请求
通常,你想要发送一些编码为表单形式的数据——非常像一个 HTML 表单。要实现这个,只需简单地传递一个字典给 data 参数。你的数据字典在发出请求时会自动编码为表单形式:
>>> payload = {'key1': 'value1', 'key2': 'value2'}
>>> r = requests.post("http://httpbin.org/post", data=payload)
很多时候你想要发送的数据并非编码为表单形式的。如果你传递一个 string 而不是一个 dict,那么数据会被直接发布出去。
>>> import json
>>> url = 'https://api.github.com/some/endpoint'
>>> payload = {'some': 'data'}
>>> r = requests.post(url, data=json.dumps(payload))
此处除了可以自行对 dict 进行编码,你还可以使用 json 参数直接传递,然后它就会被自动编码。
>>> url = 'https://api.github.com/some/endpoint'
>>> payload = {'some': 'data'}
>>> r = requests.post(url, json=payload)
2.3 定制请求头
在模拟请求时,如果不设置请求头的话是比较容易被网站发现是来自爬虫脚本,一些网站会对这种模拟请求进行拒绝。因此我们可以简单设置一下请求头做伪装,一般是设置浏览器。
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",
}
r = requests.get(url, headers=headers)
其实,对于请求头还可以设置很多参数,具体大家可以在实际爬虫过程中在开发者模式看看里面的请求头模块进行分析处理。

2.4 响应码
我们在 2.1 中看到获取响应码的是通过 r.status_code属性,一般来说如果 返回 数字 200,则表示成功获取了网页数据。
响应码分为五种类型,由它们的第一位数字表示:1xx:信息,请求收到,继续处理 2xx:成功,行为被成功地接受、理解和采纳 3xx:重定向,为了完成请求,必须进一步执行的动作 4xx:客户端错误,请求包含语法错误或者请求无法实现 5xx:服务器错误,服务器不能实现一种明显无效的请求
3.解析数据
上面有提到我们请求的网页数据有Html源码文本或者是json字符串文本,两者的解析方式不同。以下我们分别进行简单说明,大家在实际操作中视情况而定即可。
3.1 网页html文本解析
对于网页html文本来说,这里介绍Beautiful Soup、xpath和re正则表达式三种解析方法。
以贝壳二手房最新房源(https://bj.ke.com/ershoufang/co32/)为例,其html源码如下,我们通过get请求后的数据进行解析。
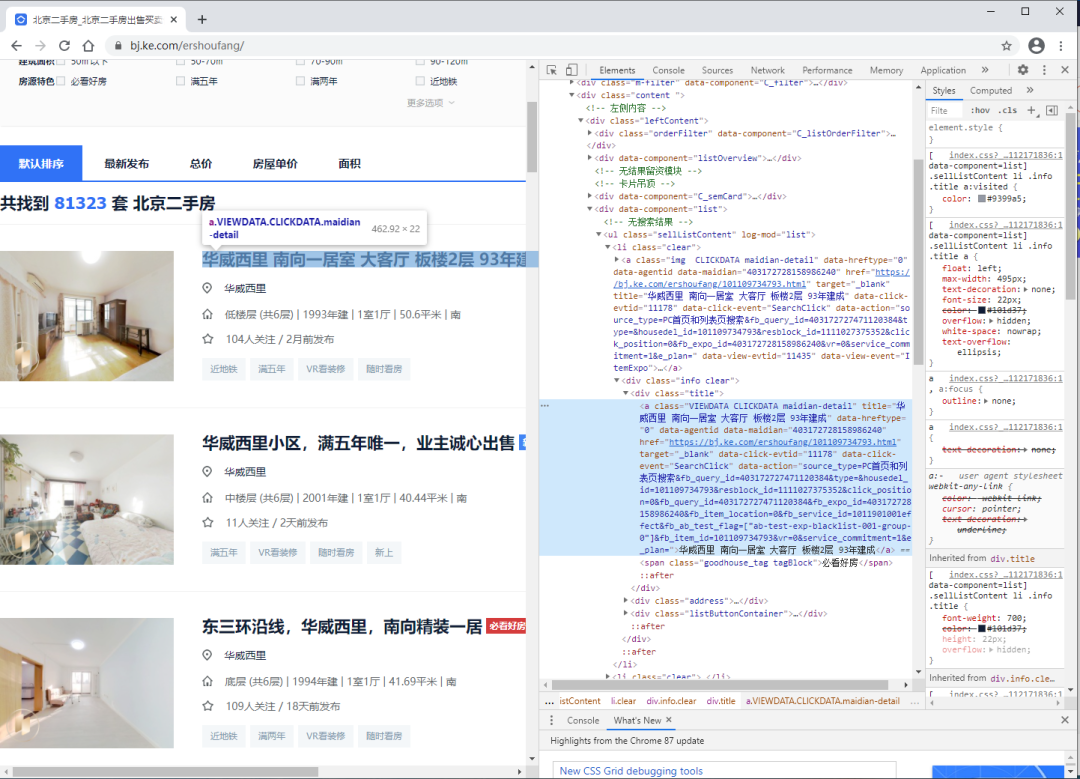
3.1.1 Beautiful Soup
关于Beautiful Soup库的更多使用方式,大家可以前往查看(https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/)
首先安装pip install beautifulsoup4。
我们将网页html文本内容r.text当作第一个参数传给BeautifulSoup对象,该对象的第二个参数为解析器的类型(这里使用lxml),此时就完成了BeaufulSoup对象的初始化。然后,将这个对象赋值给soup变量。
from bs4 import BeautifulSoup
import requests
url = 'https://bj.ke.com/ershoufang/co32/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')

获取房源的名称的代码如下:
# 获取全部房源 所在的节点
sellList = soup.find(class_="sellListContent")
# 获取全部房源节点列表
lis = sellList.find_all('li',class_="clear")
# 选取第一个房源节点
div = lis[0].find('div',class_="info clear")
# 采集房源名称
title = div.find('div',class_="title")
print(title.text)
明春西园 2室1厅 南 北
房源其他信息大家可以自己处理,强化学习!
3.1.2 xpath
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中查找信息的语言。
首先安装lxmlpip install lxml。
常见的规则如下:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
首先导入 lxml 库的 etree 模块,然后声明一段 HTML 文本,调用 HTML 类进行初始化,成功构造一个 XPath 解析对象。
from lxml import etree
import requests
url = 'https://bj.ke.com/ershoufang/co32/'
r = requests.get(url)
html = etree.HTML(r.text)
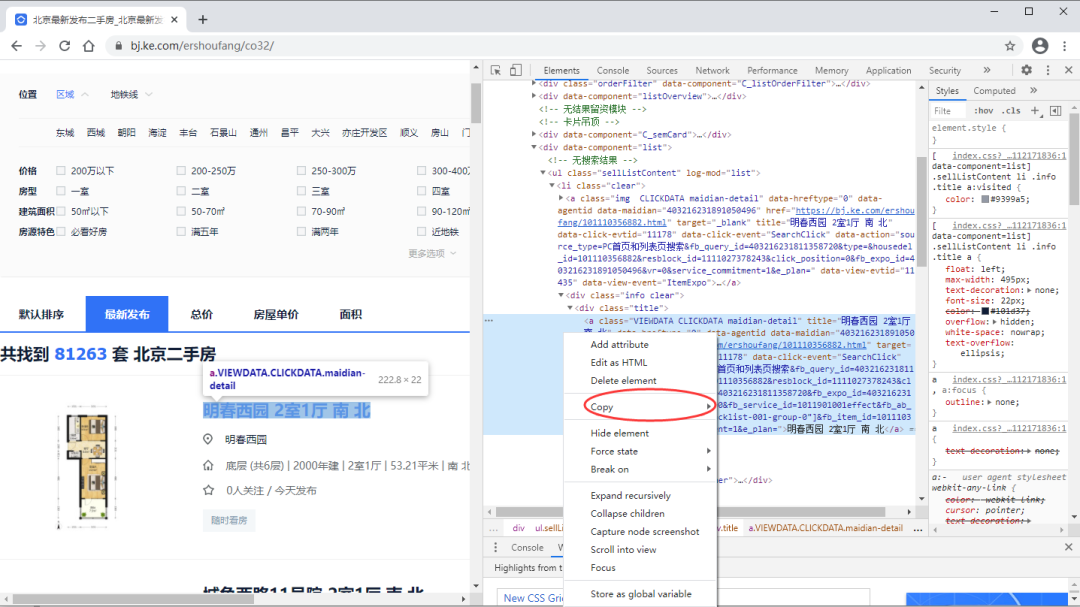
通过copy获取的xpath://*[@id="beike"]/div[1]/div[4]/div[1]/div[4]/ul/li[1]/div/div[1]/a
# 获取 全部房源所在节点 ul,根据属性匹配精准查找
ul = html.xpath('.//ul[@class="sellListContent"]')[0]
# 获取房源列表
lis = ul.xpath('.//li[@class="clear"]')
# 选取第一个房源节点
li = lis[0]
# 获取其房源名称
li.xpath('./div/div[1]/a/text()')
['明春西园 2室1厅 南 北']
其他房源信息,大家可以自行处理,强化学习!
3.1.3 re正则
关于re正则解析网页html大家也可以前往查看此前发布的文章《对着爬虫网页HTML学习Python正则表达式re》。
# 找到房源名称所在的前后字符,然后组成正则表达式
re.findall(r',r.text,re.S)[0]
'明春西园 2室1厅 南 北'
3.2 json文本解析
在requests提供了r.json(),可以用于json数据解码,一般网页数据为json格式时用此方法。除此之外,还可以通过json.loads()和eval()方法进行处理,具体可以参考此前文章《Python爬取美团网数据这么简单,别再说你不会了哦!》。
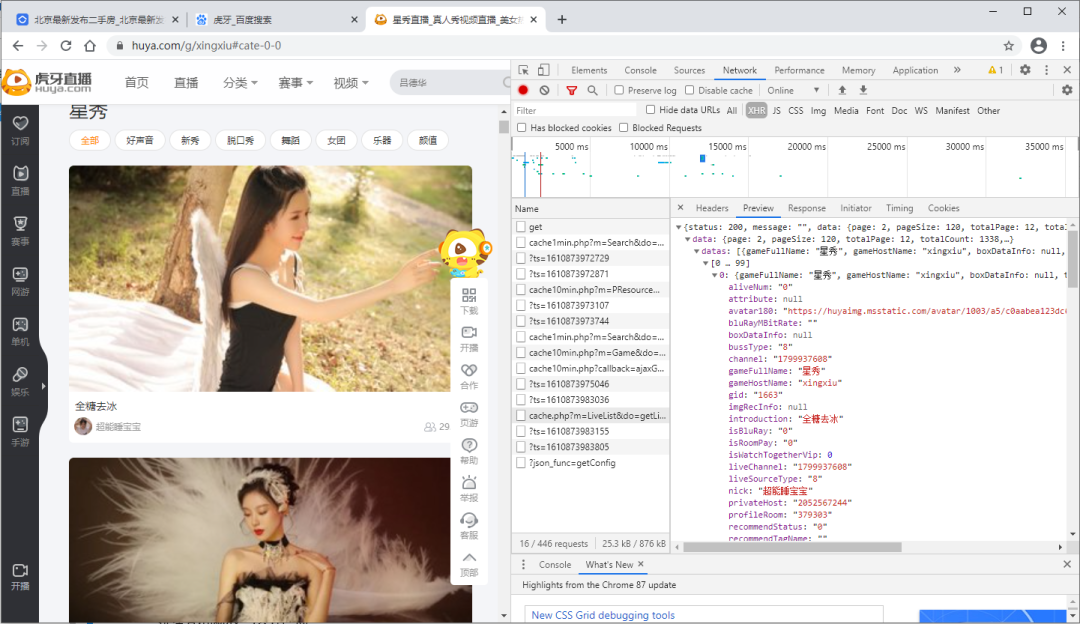
url = 'https://www.huya.com/cache.php'
parames = {
'm': 'LiveList',
'do': 'getLiveListByPage',
'gameId': 1663,
'tagAll': 0,
'page': 2, # 翻页变化的就是这个参数
}
r = requests.get(url, params=parames)
data = r.json()
type(data)
dict
如此解析后得到的数据就是字典,然后我们在看看字典中哪些字段是我们需要的,取出即可。
4.存储数据
当我们获取了到想要的数据后,便可以写入本地了。
对于文本类数据,可以通过csv模块或pandas模块进行写入到本地csv文件或excel文件;同时也可以用pymysql模块写入到数据库或者sqlite写入到本地数据库。
对于视频或者图片,可以open一个文件然后写入二进制内容后保存本地亦可。
关于存储数据大家可以结合实际案例进行学习。
近期文章
Python网络爬虫与文本数据分析 bsite库 | 采集B站视频信息、评论数据 爬虫实战 | 采集&可视化知乎问题的回答 pdf2docx库 | 转文件格式,支持抽取文件中的表格数据 rpy2库 | 在jupyter中调用R语言代码 tidytext | 耳目一新的R-style文本分析库 reticulate包 | 在Rmarkdown中调用Python代码 plydata库 | 数据操作管道操作符>> plotnine: Python版的ggplot2作图库 七夕礼物 | 全网最火的钉子绕线图制作教程 读完本文你就了解什么是文本分析 文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用 plotnine: Python版的ggplot2作图库 小案例: Pandas的apply方法 stylecloud:简洁易用的词云库 用Python绘制近20年地方财政收入变迁史视频 Wow~70G上市公司定期报告数据集 漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
“分享”和“在看”是更好的支持!