感谢读者胖子大佬提供的企业面试题。本文因为时间关系只有部分答案,后续的答案小编会持续补全,请持续关注本系列。部分答案可以参考《Flink面试通关手册》。
年后升职加薪就靠它了。胖子大佬就在交流群里,需要加群的公众号回复【加群】。
【开了赞赏,大家可以随意打赏,小编会用打赏金额✖️10倍奖励给我们的胖子大佬】
1、Flink如何保证精确一次性消费
Flink 保证精确一次性消费主要依赖于两种Flink机制
主要是当Flink开启Checkpoint的时候,会往Source端插入一条barrir,然后这个barrir随着数据流向一直流动,当流入到一个算子的时候,这个算子就开始制作checkpoint,制作的是从barrir来到之前的时候当前算子的状态,将状态写入状态后端当中。然后将barrir往下流动,当流动到keyby 或者shuffle算子的时候,例如当一个算子的数据,依赖于多个流的时候,这个时候会有barrir对齐,也就是当所有的barrir都来到这个算子的时候进行制作checkpoint,依次进行流动,当流动到sink算子的时候,并且sink算子也制作完成checkpoint会向jobmanager 报告 checkpoint n 制作完成。
Flink 提供了CheckpointedFunction与CheckpointListener这样两个接口,CheckpointedFunction中有snapshotState方法,每次checkpoint触发执行方法,通常会将缓存数据放入状态中,可以理解为一个hook,这个方法里面可以实现预提交,CheckpointListyener中有notifyCheckpointComplete方法,checkpoint完成之后的通知方法,这里可以做一些额外的操作。例如FLinkKafkaConumerBase使用这个来完成Kafka offset的提交,在这个方法里面可以实现提交操作。在2PC中提到如果对应流程例如某个checkpoint失败的话,那么checkpoint就会回滚,不会影响数据一致性,那么如果在通知checkpoint成功的之后失败了,那么就会在initalizeSate方法中完成事务的提交,这样可以保证数据的一致性。最主要是根据checkpoint的状态文件来判断的。
2、flink和spark区别
flink是一个类似spark的“开源技术栈”,因为它也提供了批处理,流式计算,图计算,交互式查询,机器学习等。flink也是内存计算,比较类似spark,但是不一样的是,spark的计算模型基于RDD,将流式计算看成是特殊的批处理,他的DStream其实还是RDD。而flink吧批处理当成是特殊的流式计算,但是批处理和流式计算的层的引擎是两个,抽象了DataSet和DataStream。flink在性能上也表现的很好,流式计算延迟比spark少,能做到真正的流式计算,而spark只能是准流式计算。而且在批处理上,当迭代次数变多,flink的速度比spark还要快,所以如果flink早一点出来,或许比现在的Spark更火。
3、Flink的状态可以用来做什么?
checkpoint的数据恢复
逻辑计算
4、Flink的waterMark机制,Flink watermark传递机制
Flink 中的watermark机制是用来处理乱序的,flink的时间必须是event time ,有一个简单的例子就是,假如窗口是5秒,watermark是2秒,那么 总共就是7秒,这个时候什么时候会触发计算呢,假设数据初始时间是1000,那么等到6999的时候会触发5999窗口的计算,那么下一个就是13999的时候触发10999的窗口
其实这个就是watermark的机制,在多并行度中,例如在kafka中会所有的分区都达到才会触发窗口
5、Flink的时间语义
Ingestion time 事件进入Flink的时间
processing time 事件进入算子的时间
6、Flink window join
1、window join,即按照指定的字段和滚动滑动窗口和会话窗口进行 inner join
2、是coGoup 其实就是left join 和 right join,
3、interval join 也就是 在窗口中进行join 有一些问题,因为有些数据是真的会后到的,时间还很长,那么这个时候就有了interval join但是必须要是事件时间,并且还要指定watermark和水位以及获取事件时间戳。并且要设置 偏移区间,因为join 也不能一直等的。
7、flink窗口函数有哪些
8、keyedProcessFunction 是如何工作的。假如是event time的话
keyedProcessFunction 是有一个ontime 操作的,假如是 event时间的时候 那么 调用的时间就是查看,event的watermark 是否大于 trigger time 的时间,如果大于则进行计算,不大于就等着,如果是kafka的话,那么默认是分区键最小的时间来进行触发。
9、flink是怎么处理离线数据的例如和离线数据的关联?
4、open方法中读取,然后定时线程刷新,缓存更新是先删除,之后再来一条之后再负责写入缓存
10、flink支持的数据类型
DataSet Api 和 DataStream Api、Table Api
11、Flink出现数据倾斜怎么办
在flink的web ui中可以看到数据倾斜的情况,就是每个subtask处理的数据量差距很大,例如有的只有一M 有的100M 这就是严重的数据倾斜了。
例如上游kafka发送的时候指定的key出现了数据热点问题,那么就在接入之后,做一个负载均衡(前提下游不是keyby)。
12、flink 维表关联怎么做的
4、open方法中读取,然后定时线程刷新,缓存更新是先删除,之后再来一条之后再负责写入缓存
13、Flink checkpoint的超时问题 如何解决。
4、有数据倾斜的话,那么解决数据倾斜后,会有改善,
14、flinkTopN与离线的TopN的区别
topn 无论是在离线还是在实时计算中都是比较常见的功能,不同于离线计算中的topn,实时数据是持续不断的,这样就给topn的计算带来很大的困难,因为要持续在内存中维持一个topn的数据结构,当有新数据来的时候,更新这个数据结构
15、sparkstreaming 和flink 里checkpoint的区别
sparkstreaming 的checkpoint会导致数据重复消费
但是flink的 checkpoint可以 保证精确一次性,同时可以进行增量,快速的checkpoint的,有三个状态后端,memery、rocksdb、hdfs
16、简单介绍一下cep状态编程
Complex Event Processing(CEP):
FLink Cep 是在FLink中实现的复杂时间处理库,CEP允许在无休止的时间流中检测事件模式,让我们有机会掌握数据中重要的部分,一个或多个由简单事件构成的时间流通过一定的规则匹配,然后输出用户想得到的数据,也就是满足规则的复杂事件。
17、 Flink cep连续事件的可选项有什么
18、如何通过flink的CEP来实现支付延迟提醒
19、Flink cep 你用过哪些业务场景
20、cep底层如何工作
21、cep怎么老化
22、cep性能调优
23、Flink的背压,介绍一下Flink的反压,你们是如何监控和发现的呢。
Flink 没有使用任何复杂的机制来解决反压问题,Flink 在数据传输过程中使用了分布式阻塞队列。我们知道在一个阻塞队列中,当队列满了以后发送者会被天然阻塞住,这种阻塞功能相当于给这个阻塞队列提供了反压的能力。
当你的任务出现反压时,如果你的上游是类似 Kafka 的消息系统,很明显的表现就是消费速度变慢,Kafka 消息出现堆积。
如果你的业务对数据延迟要求并不高,那么反压其实并没有很大的影响。但是对于规模很大的集群中的大作业,反压会造成严重的“并发症”。首先任务状态会变得很大,因为数据大规模堆积在系统中,这些暂时不被处理的数据同样会被放到“状态”中。另外,Flink 会因为数据堆积和处理速度变慢导致 checkpoint 超时,而 checkpoint 是 Flink 保证数据一致性的关键所在,最终会导致数据的不一致发生。
Flink 的后台页面是我们发现反压问题的第一选择。Flink 的后台页面可以直观、清晰地看到当前作业的运行状态。
Web UI,需要注意的是,只有用户在访问点击某一个作业时,才会触发反压状态的计算。在默认的设置下,Flink的TaskManager会每隔50ms触发一次反压状态监测,共监测100次,并将计算结果反馈给JobManager,最后由JobManager进行反压比例的计算,然后进行展示。
在生产环境中Flink任务有反压有三种OK、LOW、HIGH
24、Flink的CBO,逻辑执行计划和物理执行计划
Flink的优化执行其实是借鉴的数据库的优化器来生成的执行计划。
CBO,成本优化器,代价最小的执行计划就是最好的执行计划。传统的数据库,成本优化器做出最优化的执行计划是依据统计信息来计算的。Flink 的成本优化器也一样。Flink 在提供最终执行前,优化每个查询的执行逻辑和物理执行计划。这些优化工作是交给底层来完成的。根据查询成本执行进一步的优化,从而产生潜在的不同决策:如何排序连接,执行哪种类型的连接,并行度等等。
25、Flink中数据聚合,不使用窗口怎么实现聚合
26、Flink中state有哪几种存储方式
27、Flink 异常数据怎么处理
异常数据在我们的场景中,一般分为缺失字段和异常值数据。
异常值: 例如宝宝的年龄的数据,例如对于母婴行业来讲,一个宝宝的年龄是一个至关重要的数据,可以说是最重要的,因为宝宝大于3岁几乎就不会在母婴上面购买物品。像我们的有当日、未知、以及很久的时间。这样都属于异常字段,这些数据我们会展示出来给店长和区域经理看,让他们知道多少个年龄是不准的。如果要处理的话,可以根据他购买的时间来进行实时矫正,例如孕妇服装、奶粉的段位、纸尿裤的大小,以及奶嘴啊一些能够区分年龄段的来进行处理。我们并没有实时处理这些数据,我们会有一个底层的策略任务夜维去跑,一个星期跑一次。
缺失字段: 例如有的字段真的缺失的很厉害,能修补就修补。不能修补就放弃,就像上家公司中的新闻推荐过滤器。
28、Flink 监控你们怎么做的
29、Flink 有数据丢失的可能吗
At Most Once 最多消费一次 发生故障有可能丢失
At Least Once 最少一次 发生故障有可能重复
Exactly-Once 精确一次 如果产生故障,也能保证数据不丢失不重复。
flink 新版本已经不提供 At-Most-Once 语义。
30、Flink interval join 你能简单的写一写吗
DataStream
keyed1 = ds1.keyBy(o -> o.getString("key"))
DataStream
keyed2 = ds2.keyBy(o -> o.getString("key"))
//右边时间戳-5s<=左边流时间戳<=右边时间戳-1s
keyed1.intervalJoin(keyed2).between(Time.milliseconds(-5), Time.milliseconds(5))
31、Flink 提交的时候 并行度如何制定,以及资源如何配置
并行度根据kafka topic的并行度,一个并行度3个G
32、Flink的boardcast join 的原理是什么
利用 broadcast State 将维度数据流广播到下游所有 task 中。这个 broadcast 的流可以与我们的事件流进行 connect,然后在后续的 process 算子中进行关联操作即可。
33、flink的source端断了,比如kafka出故障,没有数据发过来,怎么处理?
34、flink有什么常用的流的API?
window join 啊 cogroup 啊 map flatmap,async io 等
35、flink的水位线,你了解吗,能简单介绍一下吗
Flink 的watermark是一种延迟触发的机制。
一般watermark是和window结合来进行处理乱序数据的,Watermark最根本就是一个时间机制,例如我设置最大乱序时间为2s,窗口时间为5秒,那么就是当事件时间大于7s的时候会触发窗口。当然假如有数据分区的情况下,例如kafka中接入watermake的话,那么watermake是会流动的,取的是所有分区中最小的watermake进行流动,因为只有最小的能够保证,之前的数据都已经来到了,可以触发计算了。
36、Flink怎么维护Checkpoint?在HDFS上存储的话会有小文件吗
默认情况下,如果设置了Checkpoint选项,Flink只保留最近成功生成的1个Checkpoint。当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活。Flink支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置指定最多需要保存Checkpoint的个数。
37、Spark和Flink的序列化,有什么区别吗?
Spark 默认使用的是 Java序列化机制,同时还有优化的机制,也就是kryo
Flink是自己实现的序列化机制,也就是TypeInformation
38、Flink是怎么处理迟到数据的?但是实际开发中不能有数据迟到,怎么做?
Flink 的watermark是一种延迟触发的机制。
一般watermark是和window结合来进行处理乱序数据的,Watermark最根本就是一个时间机制,例如我设置最大乱序时间为2s,窗口时间为5秒,那么就是当事件时间大于7s的时候会触发窗口。当然假如有数据分区的情况下,例如kafka中接入watermake的话,那么watermake是会流动的,取的是所有分区中最小的watermake进行流动,因为只有最小的能够保证,之前的数据都已经来到了,可以触发计算了。
39、画出flink执行时的流程图。
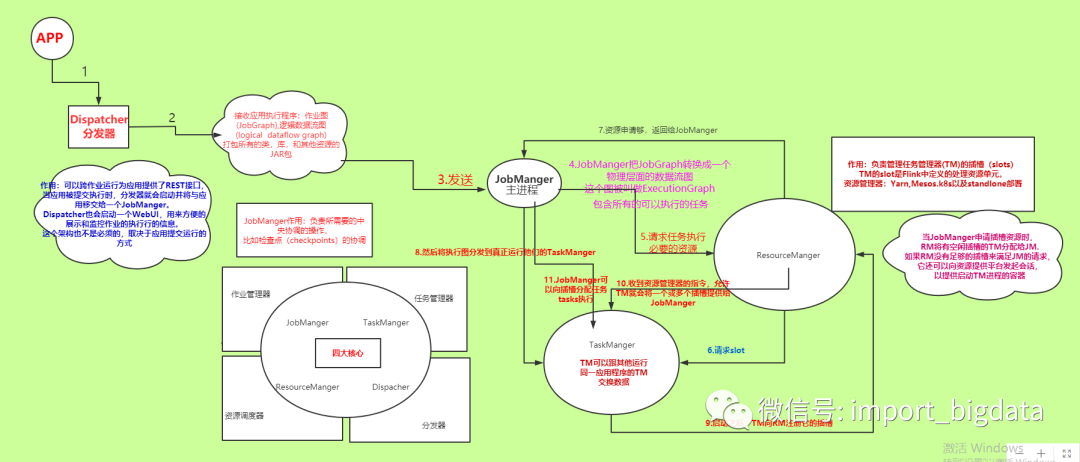
40、Flink分区分配策略
41、Flink关闭后状态端数据恢复得慢怎么办?
42、了解flink的savepoint吗?讲一下savepoint和checkpoint的不同和各有什么优势
43、flink的状态后端机制
Flink的状态后端是Flink在做checkpoint的时候将状态快照持久化,有三种状态后端 Memery、HDFS、RocksDB
44、flink中滑动窗口和滚动窗口的区别,实际应用的窗口是哪种?用的是窗口长度和滑动步长是多少?
45、用flink能替代spark的批处理功能吗
Flink 未来的目标是批处理和流处理一体化,因为批处理的数据集你可以理解为是一个有限的数据流。Flink 在批出理方面,尤其是在今年 Flink 1.9 Release 之后,合入大量在 Hive 方面的功能,你可以使用 Flink SQL 来读取 Hive 中的元数据和数据集,并且使用 Flink SQL 对其进行逻辑加工,不过目前 Flink 在批处理方面的性能,还是干不过 Spark的。
目前看来,Flink 在批处理方面还有很多内容要做,当然,如果是实时计算引擎的引入,Flink 当然是首选。
46、flink计算的UV你们是如何设置状态后端保存数据
47、sparkstreaming和flink在执行任务上有啥区别,不是简单的流处理和微批,sparkstreaming提交任务是分解成stage,flink是转换graph,有啥区别?
48、flink把streamgraph转化成jobGraph是在哪个阶段?
49、Flink中的watermark除了处理乱序数据还有其他作用吗?
50、flink你一般设置水位线设置多少
52、Flink任务提交流程
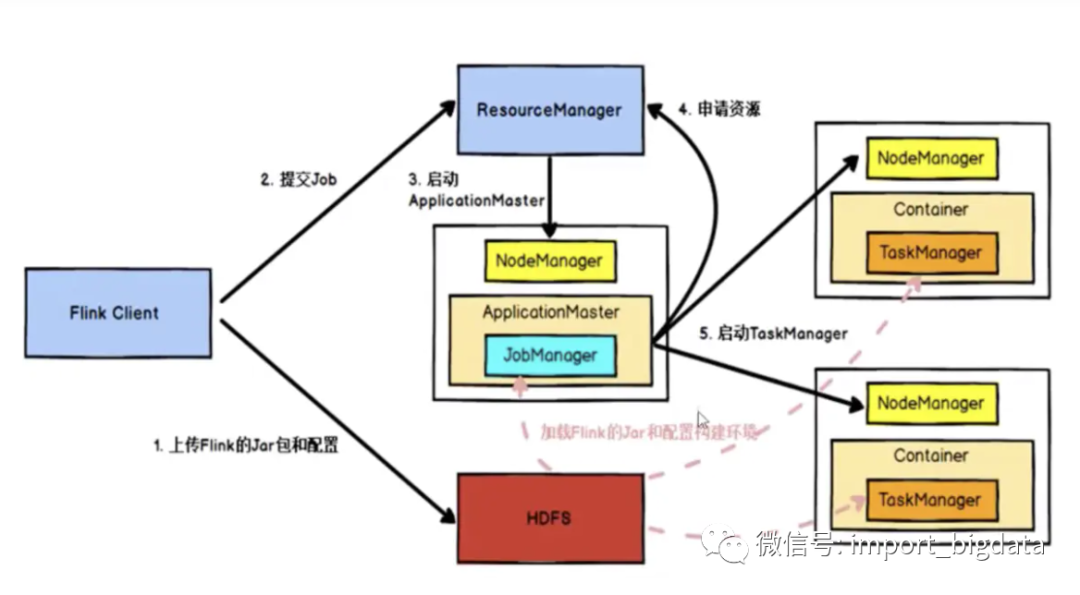
Flink任务提交后,Client向HDFS上传Flink的jar包和配置,之后向Yarn ResourceManager提交任务,ResourceManager分配Container资源并通知对应的NodeManager启动 ApplicationMaster,ApplicationMaster启动后加载Flink的jar包和配置构建环境,然后启动JobManager;之后Application Master向ResourceManager申请资源启动TaskManager ,ResourceManager分配Container资源后,由ApplicationMaster通知资源所在的节点的NodeManager启动TaskManager,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager,TaskManager启动向JobManager发送心跳,并等待JobManager向其分配任务。
53、Flink技术架构图
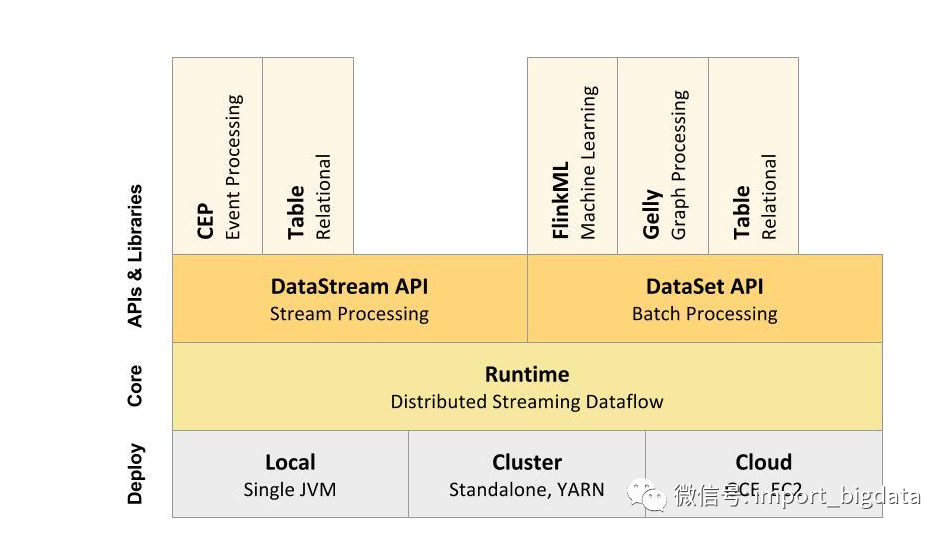
54、flink如何实现在指定时间进行计算。
55、手写Flink topN
57、Flink的Join算子有哪些
1、window join,即按照指定的字段和滚动滑动窗口和会话窗口进行 inner join
2、是coGoup 其实就是left join 和 right join,
3、interval join 也就是 在窗口中进行join 有一些问题,因为有些数据是真的会后到的,时间还很长,那么这个时候就有了interval join但是必须要是事件时间,并且还要指定watermark和水位以及获取事件时间戳。并且要设置 偏移区间,因为join 也不能一直等的。
58、Flink1.10 有什么新特性吗?
Flink 目前的 TaskExecutor 内存模型存在着一些缺陷,导致优化资源利用率比较困难,例如:
为了让内存配置变的对于用户更加清晰、直观,Flink 1.10 对 TaskExecutor 的内存模型和配置逻辑进行了较大的改动 (FLIP-49 [7])。这些改动使得 Flink 能够更好地适配所有部署环境(例如 Kubernetes, Yarn, Mesos),让用户能够更加严格的控制其内存开销。
Managed 内存的范围有所扩展,还涵盖了 RocksDB state backend 使用的内存。尽管批处理作业既可以使用堆内内存也可以使用堆外内存,使用 RocksDB state backend 的流处理作业却只能利用堆外内存。因此为了让用户执行流和批处理作业时无需更改集群的配置,我们规定从现在起 managed 内存只能在堆外。
此前,配置像 RocksDB 这样的堆外 state backend 需要进行大量的手动调试,例如减小 JVM 堆空间、设置 Flink 使用堆外内存等。现在,Flink 的开箱配置即可支持这一切,且只需要简单地改变 managed 内存的大小即可调整 RocksDB state backend 的内存预算。
另一个重要的优化是,Flink 现在可以限制 RocksDB 的 native 内存占用,以避免超过总的内存预算—这对于 Kubernetes 等容器化部署环境尤为重要。
在此之前,提交作业是由执行环境负责的,且与不同的部署目标(例如 Yarn, Kubernetes, Mesos)紧密相关。这导致用户需要针对不同环境保留多套配置,增加了管理的成本。
在 Flink 1.10 中,作业提交逻辑被抽象到了通用的 Executor 接口。新增加的 ExecutorCLI (引入了为任意执行目标指定配置参数的统一方法。此外,随着引入 JobClient负责获取 JobExecutionResult,获取作业执行结果的逻辑也得以与作业提交解耦。
对于想要在容器化环境中尝试 Flink 的用户来说,想要在 Kubernetes 上部署和管理一个 Flink standalone 集群,首先需要对容器、算子及像 kubectl 这样的环境工具有所了解。
在 Flink 1.10 中,我们推出了初步的支持 session 模式的主动 Kubernetes 集成(FLINK-9953)。其中,“主动”指 Flink ResourceManager (K8sResMngr) 原生地与 Kubernetes 通信,像 Flink 在 Yarn 和 Mesos 上一样按需申请 pod。用户可以利用 namespace,在多租户环境中以较少的资源开销启动 Flink。这需要用户提前配置好 RBAC 角色和有足够权限的服务账号。
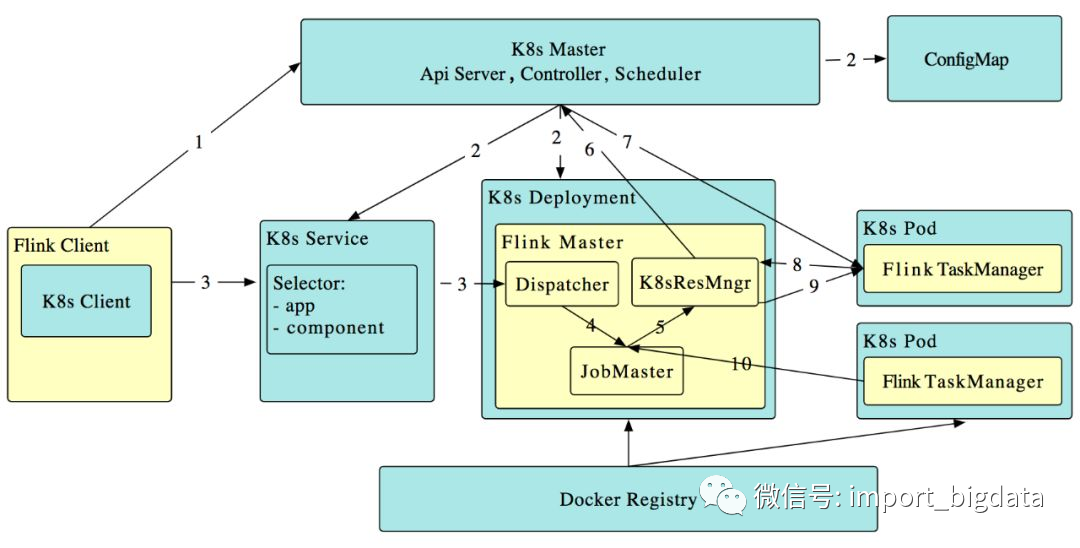
Table API/SQL: 生产可用的 Hive 集成
Flink 1.9 推出了预览版的 Hive 集成。该版本允许用户使用 SQL DDL 将 Flink 特有的元数据持久化到 Hive Metastore、调用 Hive 中定义的 UDF 以及读、写 Hive 中的表。Flink 1.10 进一步开发和完善了这一特性,带来了全面兼容 Hive 主要版本的生产可用的 Hive 集成。
此前,Flink 只支持写入未分区的 Hive 表。在 Flink 1.10 中,Flink SQL 扩展支持了 INSERT OVERWRITE 和 PARTITION 的语法(FLIP-63 ),允许用户写入 Hive 中的静态和动态分区。
写入静态分区
INSERT { INTO | OVERWRITE } TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
写入动态分区
INSERT { INTO | OVERWRITE } TABLE tablename1 select_statement1 FROM from_statement;
对分区表的全面支持,使得用户在读取数据时能够受益于分区剪枝,减少了需要扫描的数据量,从而大幅提升了这些操作的性能。
另外,除了分区剪枝,Flink 1.10 的 Hive 集成还引入了许多数据读取方面的优化,例如:
投影下推:Flink 采用了投影下推技术,通过在扫描表时忽略不必要的域,最小化 Flink 和 Hive 表之间的数据传输量。这一优化在表的列数较多时尤为有效。
LIMIT 下推:对于包含 LIMIT 语句的查询,Flink 在所有可能的地方限制返回的数据条数,以降低通过网络传输的数据量。
读取数据时的 ORC 向量化:为了提高读取 ORC 文件的性能,对于 Hive 2.0.0 及以上版本以及非复合数据类型的列,Flink 现在默认使用原生的 ORC 向量化读取器。
59、Flink的重启策略
固定延迟重启策略是尝试给定次数重新启动作业。如果超过最大尝试次数,则作业失败。在两次连续重启尝试之间,会有一个固定的延迟等待时间。
故障率重启策略在故障后重新作业,当设置的故障率(failure rate)超过每个时间间隔的故障时,作业最终失败。在两次连续重启尝试之间,重启策略延迟等待一段时间。
使用群集定义的重新启动策略。这对于启用检查点的流式传输程序很有帮助。默认情况下,如果没有定义其他重启策略,则选择固定延迟重启策略。
60、Flink什么时候用aggregate()或者process()
当计算累加操作时候可以使用aggregate操作。
当计算窗口内全量数据的时候使用process,例如排序等操作。
61、Flink优化 你了解多少
62、Flink内存溢出怎么办
63、说说Flink中的keyState包含哪些数据结构
64、Flink shardGroup的概念
 版权声明:本文为大数据技术与架构原创整理,转载需作者授权。未经作者允许转载追究侵权责任。
版权声明:本文为大数据技术与架构原创整理,转载需作者授权。未经作者允许转载追究侵权责任。

