
胖哥的经验 | 一款普适的实时数仓架构设计
共 3236字,需浏览 7分钟
· 2021-01-15

什么?胖哥的经验,没错这是来自我们大数据成神之路小伙伴的经验。有什么问题,欢迎大家加群讨论,公众号回复【加群】。
一、实时数仓的架构背景
首先我们来聊一聊实时数仓是怎么诞生的,在离线数仓的时候数据是T+1的也就是隔一天才能看到昨天的数据,这种形式持续了很久的时间,但是有些场景真的只有实时的数据才有用武之地。例如推荐、风控、考核等。那么这个时候实时指标也就应运而生,在最开始的时候,采用flink\spark streaming来进行数据的指标统计。在这个时候,数据存在哪里又是一个问题。例如大屏计算结果可能存储在redis中,可以参考如下图所示的,实时大屏架构图。
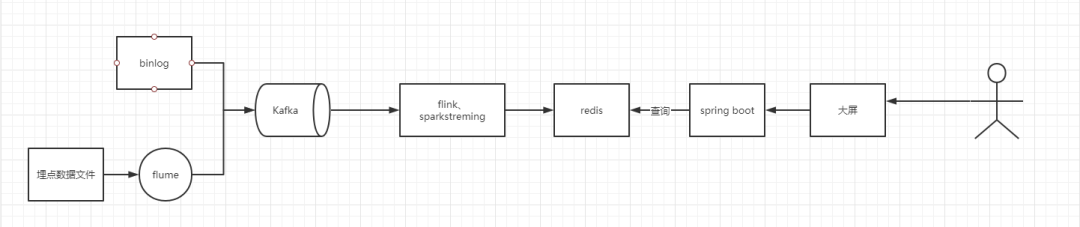
那么这个时候问题来了,你有多少指标?业务的需求是 无穷无尽 的,作为技术能做的是怎么能更好的服务他们,以数据驱动业务的成长,就像在一号线上,京东数科做的广告,以AI驱动产业数字化。我一直坚信,技术是可以改变未来的。
那么通过以上的架构图,我们可以发现,在上述的场景中,有一些问题,你的指标可能是无穷无尽的,导致的也就是开发速度可能不尽人意。可能两天才有一个指标的产出,复杂的可能一个星期乃至更长。那么我们有没有可能在牺牲一些查询速度的时候,来提升我们的开发速度,我们应该都知道spark streaming 和flink都是支持sql开发的。那么flink 或者spark streaming 来进行sql 开发真的好吗?这是一个很值得思考的问题。那么我们如何解决这个问题呢,我们是不是可以尝试将我们的binlog 数据以及埋点数据进行拉宽,也就是宽表化的一些操作,那么这个时候就是实时数仓的诞生!
实时数仓在我理解中呢,可以对外进行服务,并且可以实时的进行OLAP查询,也就是在线化查询 Ad-hoc化的查询。
二、实时数仓的架构演进
2.1 初始
在我刚来我司的时候,并没有实时数仓,只是一些批处理化的时候,这个时候对于风控和指标来讲,是不是很好的。并且是一种烟囱式的开发,数据流程是这样的,我们采用的greenplum来做的实时数仓,每15分钟去业务库和神策系统拉取实时数据到greenplum中进行计算,可以参考一下下面的图。
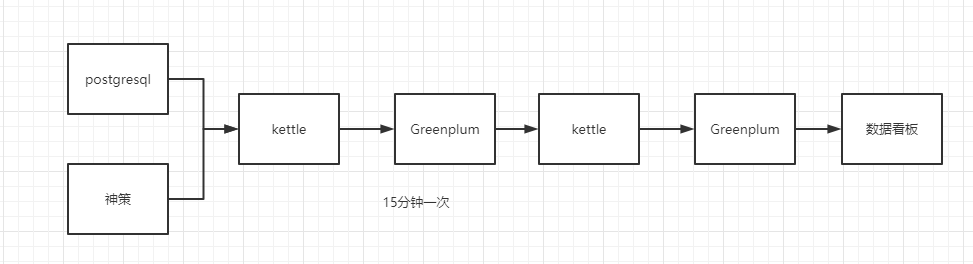
我们这个时候肯定可以发现,假如指标多的时候,那么对于开发速度来讲是一个十分缓慢的一个过程,并且会造成很多数据的冗余计算,有些指标并不能复用。
2.1 实时数仓0.1
我刚来公司,领导让开始做实时数仓,当初我并不会flink,但是我知道flink是未来,我就花了1个星期的时间把flink学了学。学完之后我就坚定了实时要用flink。不得不说真的好强啊,不强的话,阿里也不会买了flink的母公司。然后熟悉了几天业务,之后就开干,然后给我了一个线上分析的需求,这个要求用我自己的想法来做,我当时想的是我拿flink来算不是很好嘛,然后就撸起袖子加油干。写了一段时间就写完上线了,那个时候的数据流向是这样的。
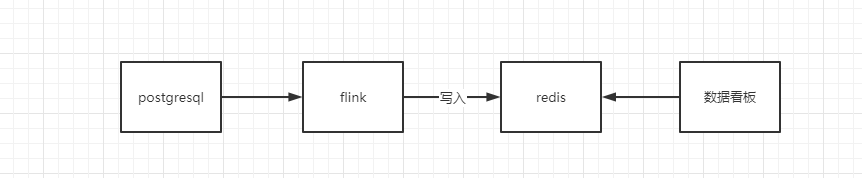
那个时候我还是很沾沾自喜的,我拿flink也能计算指标了,然后效果还不错。但是后来慢慢的需求多了起来,我天啊,我拿flink写什么时候是个头啊,然后我就想应该怎么把这些数据解耦!也就是不要烟囱式的开发。
2.1 实时数仓1.0
然后我就开始想,我假如我的表都是宽表的话,那么我直接在宽表上进行计算不就好了吗。说到就做,然后就跟总监申请了一下,要做实时数仓,也把我的困难说了一些,然后就开始设计和架构。
我当初想的是,我要拉宽这些数据表,我得有场景,我们公司是比较关心销售的,那么假如我把离线的销售宽表拿实时展现出来不就是很好的一个场景吗,那么第一个要做的宽表就是销售宽表。
那么我知道我的数据从业务库来,但是我们的postgresql 比较老了。并不能有binlog这些的操作,我当初就和研发的架构探讨了一下,他们那边借助触发器来进行给我往kafka来打一些数据,然后我对数据先进行了校验,也就是看看我要的字段都给我打过来了吗。后来数据感觉字段都有了,就开始了一番尝试拿flink接入kafka的数据。
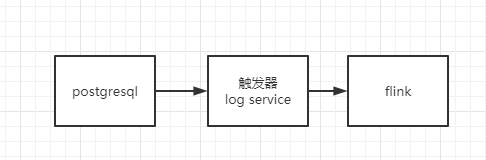
这个时候我数据是拿到了,但是我需要拉宽,我应该怎么拉宽。我把维度表放置到redis把,这样比较快。这样在flink的map方法中进行查询redis中的数据来进行拉宽维度表。
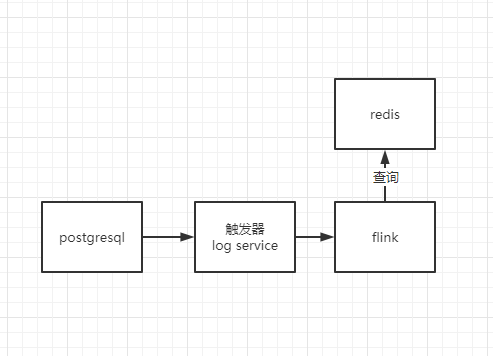
这个时候就来问题了,我的维度表是会更新的啊。我也就问了我们组的业务大佬,咨询了一下,发现维度表无非就是门店维表、品类维表(一级类、二级类、三级类等)、城市维表、商品维表、主推表等。这些维度表的更新都是很缓慢的,即使是更新,也会提前上线几天进行更新。并且我们在凌晨0点到2点是不进行出库操作的,我在这个时候进行维度表更新操作不就好了吗。那么也就有下面的思考了。

那么接下来我们就可以进行销售宽表的拉宽操作了,但是我这个时候又发现了一个问题,我拉宽之后存在哪里,这个时候我得思考的几点是。第一单表查询足够快、最好支持join。那么我开始的调研过几款 Tidb、Doris、Druid、Clickhouse。我在单机测试的表现上来看,clickhouse给我带来了无与伦比的感觉。并且考虑到当时的业务场景,也就毅然决然的采用了Clickhouse为基础的实时数仓。
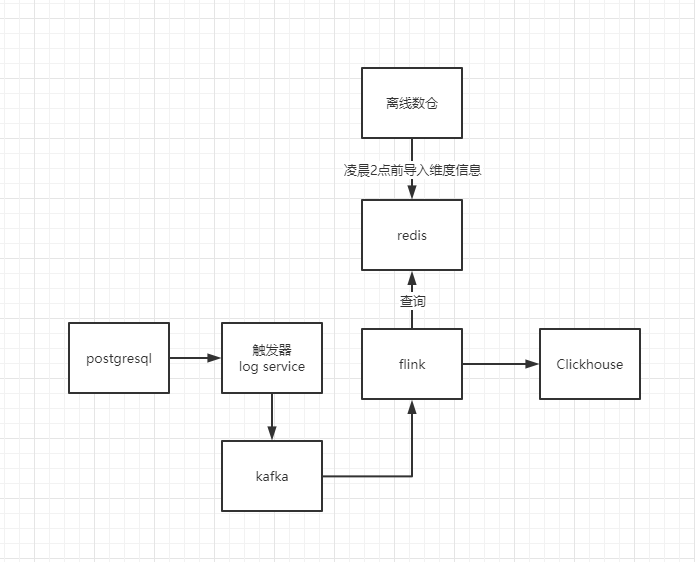
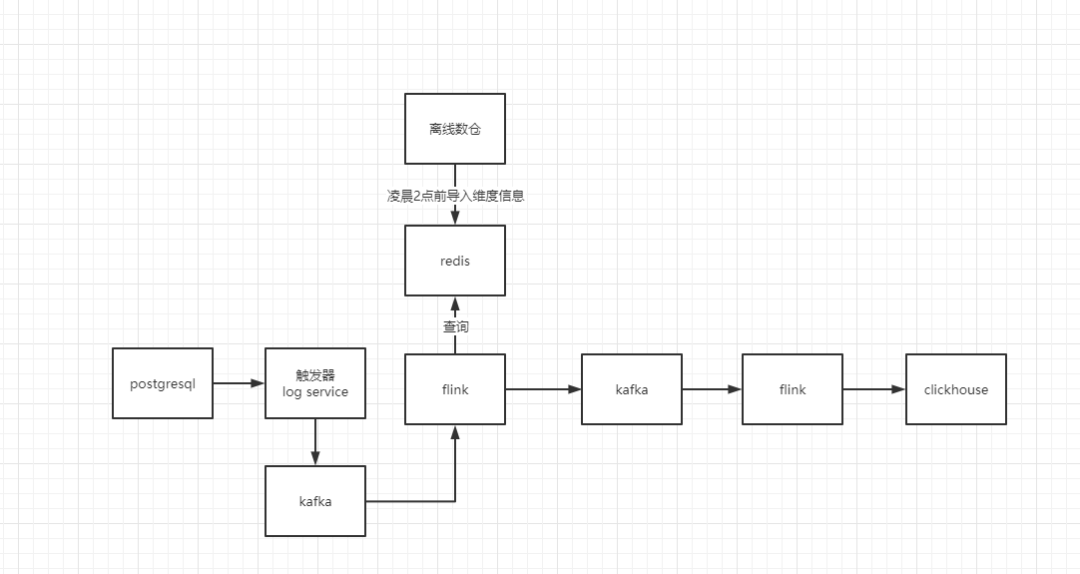
然后就这样的一个架构持续了大概两个月的时间,业务也越来越复杂,当初的架构设计已经不满足当时的业务了。我们要接入一些实时维度表,这个维度表就是用户维度表。因为门店需要对导购拉新来做当日的绩效考核。那么我们总计有2000多万的用户,我全部都导入的redis话会有一些问题。而且还要求是实时的,例如要在用户宽表中标记出来这个用户是不是新会员、是否是孕妇等。但是当初我面临的困难不是这个问题,是因为回溯分摊的问题,例如一个用户购买了一个A 赠了一个B那么这个时候,品类间的毛利就有了一些损失。例如买一件衣服送一罐奶粉,那么这个时候就有了问题。衣服的总监愿意啊,买的人多了,但是奶粉的总监不干了,我毛利没了啊。所以就有了回溯分摊这一个事情。
我就写了个flink程序,自定义了一个source实时的去库里面拉取数据,因为没有binlog。但是不能实时的去啊,对库的影响太大了。那么这个时候就想到了我每次间隔一分钟去拉取一次放到redis当中,然后flink join 的时候就写入到clickhouse中。假如没有join上的,就放到kafka的另一个topic中例如 dws_sold_detail_retry 然后再开一个flink 专门消费这个。假如还没有join上 就继续放到这个topic中,在日志中追加一个重试次数,假如这个消息重试了超过5次则,认为失败。也就不管他了。但是会报警,每天的销售额差异不能超过百分之3,就可以接受。
就这样 慢慢的加入了其他的一些宽表。例如库存、优惠券、会员宽表、促销宽表等。但是慢慢的问题也有了,那就是flink写入clickhouse的时候假如表特别宽的话,代码量是很大的。后来我就引入了waterdrop。
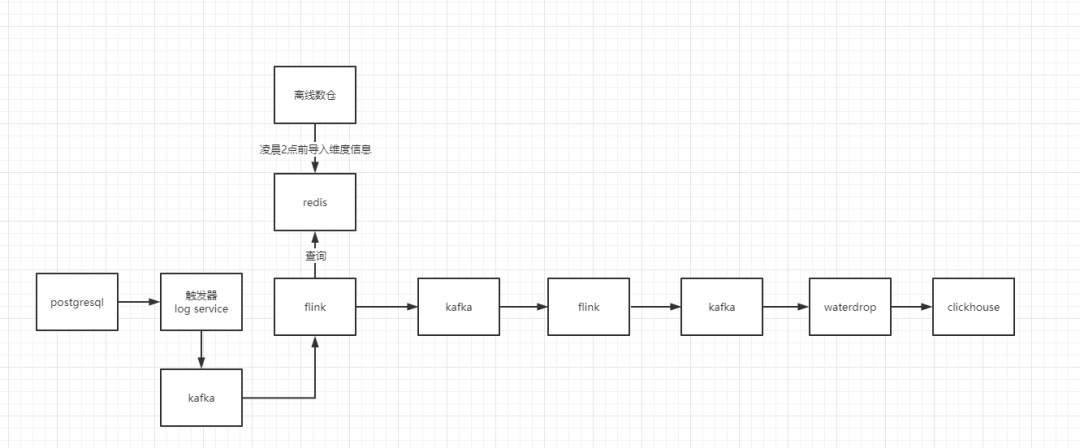
也就是以上的架构图。
三、总结
在以上的架构中,我的思想就是,flink就是拉宽,计算交给olap引擎去做起到了解耦合的作用。
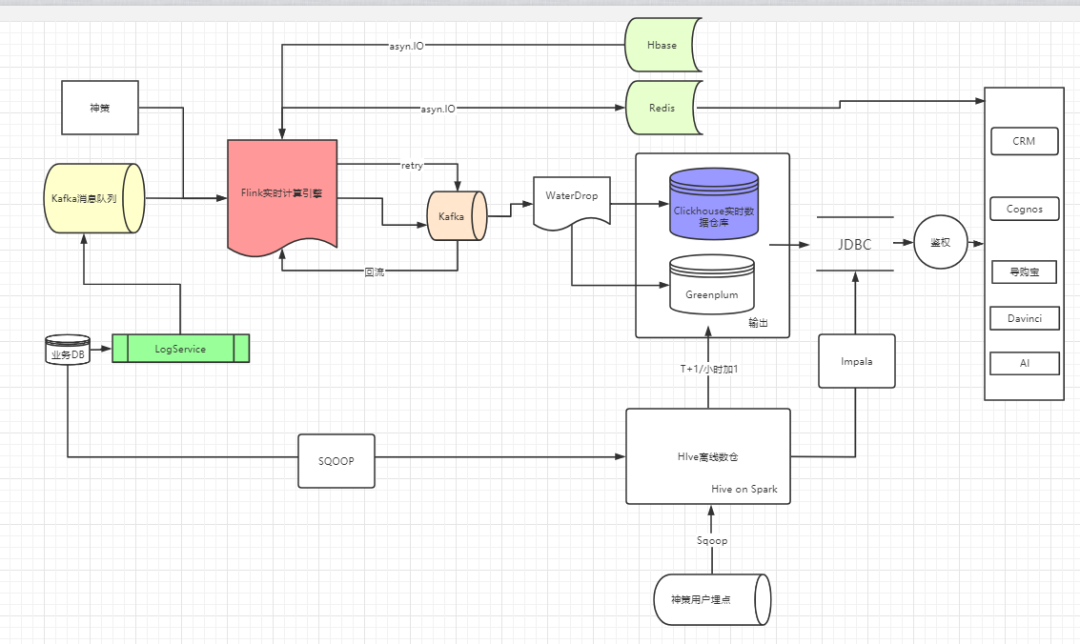
那么上面的架构也有一些问题,例如维度表太大了怎么办,后面我又引入了二级缓存。也就是引入的hbase,并且支持对外提供查询三个月内的数据实时查询。
最终架构图:

你需要的不是实时数仓 | 你需要的是一款强大的OLAP数据库(上)
你需要的不是实时数仓 | 你需要的是一款强大的OLAP数据库(下)
文章不错?点个【在看】吧! 👇