 3D视觉工坊
3D视觉工坊




点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

导读
1.各框架分布式简介 2.分布式常见问题汇总(踩坑指南)
1.各框架分布式简介
Distributed Data-Parallel Training (DDP) RPC-Based Distributed Training (RPC) Collective Communication (c10d)
接口
torch.nn.DataParallel接口或torch.nn.parallel.DistributedDataParallel接口。不过官方更推荐使用DistributedDataParallel(DDP);分布式多机情况下,则只能使用DDP接口。DistributedDataParallel和 之间的区别DataParallel是:DistributedDataParallel使用multiprocessing,即为每个GPU创建一个进程,而DataParallel使用多线程。通过使用multiprocessing,每个GPU都有其专用的进程,这避免了Python解释器的GIL导致的性能开销。如果您使用DistributedDataParallel,则可以使用 torch.distributed.launch实用程序来启动程序 参考:Use nn.parallel.DistributedDataParallel instead of multiprocessing or nn.DataParallel(https://pytorch.org/docs/master/notes/cuda.html#cuda-nn-ddp-instead)
torch.nn.parallel.DistributedDataParallel来实现数据并行的分布式训练,DistributedDateParallel,简称DDP。DDP的上层调用是通过dispatch.py实现的,即dispatch.py是DDP的python入口,它实现了 调用C ++库forward的nn.parallel.DistributedDataParallel模块的初始化步骤和功能;DDP的底层依赖c10d库的ProcessGroup进行通信,可以在ProcessGroup中找到3种开箱即用的实现,即 ProcessGroupGloo,ProcessGroupNCCL和ProcessGroupMPI。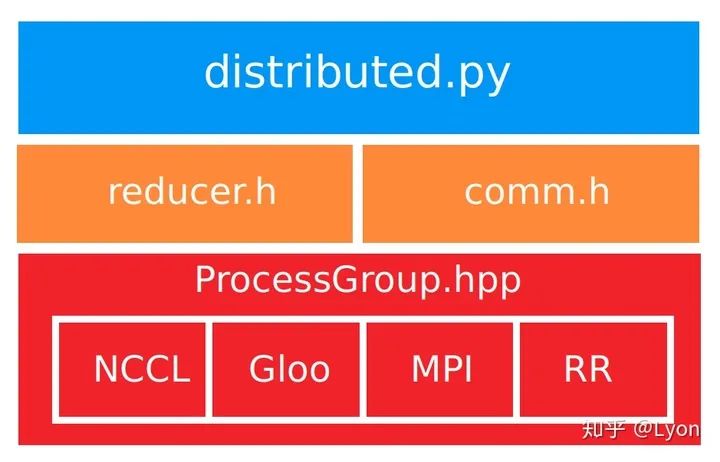
Gloo NCCL MPI
参考:Distributed Data Parallel https://pytorch.org/docs/master/notes/ddp.html
分布式示例
dist.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
world_size=args.world_size, rank=args.rank)
parser.add_argument('--world-size', default=-1, type=int,
help='number of nodes for distributed training')
parser.add_argument('--rank', default=-1, type=int,
help='node rank for distributed training')
parser.add_argument('--dist-url', default='tcp://224.66.41.62:23456', type=str,
help='url used to set up distributed training')
parser.add_argument('--dist-backend', default='nccl', type=str,
help='distributed backend')
parser.add_argument('--seed', default=None, type=int,
help='seed for initializing training. ')
parser.add_argument('--gpu', default=None, type=int,
help='GPU id to use.')
parser.add_argument('--multiprocessing-distributed', action='store_true',
help='Use multi-processing distributed training to launch '
'N processes per node, which has N GPUs. This is the '
'fastest way to use PyTorch for either single node or '
'multi node data parallel training')
--world-size 表示分布式训练中,机器节点总数 --rank 表示节点编号(n台节点即:0,1,2,..,n-1) --multiprocessing-distributed 是否开启多进程模式(单机、多机都可开启) --dist-url 本机的ip,端口号,用于多机通信 --dist-backend 多机通信后端,默认使用nccl
if args.distributed:
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
else:
train_sampler = None
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=args.batch_size, shuffle=(train_sampler is None),
num_workers=args.workers, pin_memory=True, sampler=train_sampler)
完整的利用ResNet50训练ImageNet的示例可参考:Pytorch官方仓库(https://github.com/pytorch/examples/tree/49ec0bd72b85be55579ae8ceb278c66145f593e1/imagenet) 分布式训练速度测评及结果,可以参考DLPerf:PyTorch ResNet50 v1.5测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/PyTorch/resnet50v1.5)

2.TensorFlow
接口
tf.distribute.Strategy接口来定义分布式策略,并通过这些不同的策略,来进行模型的分布式训练。tf.distribute.Strategy 旨在实现以下目标:易于使用,支持多种用户(包括研究人员和 ML 工程师等)。 提供开箱即用的良好性能。 轻松切换策略。
MirroredStrategy TPUStrategy MultiWorkerMirroredStrategy CentralStorageStrategy ParameterServerStrategy
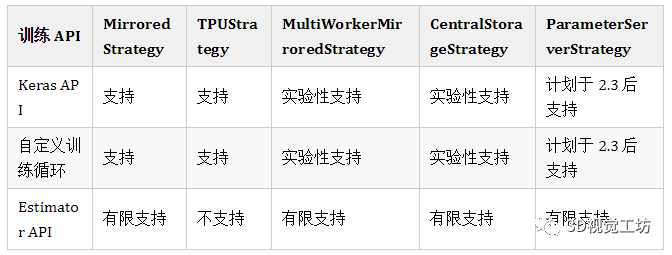
注:实验性支持指不保证该 API 的兼容性。
注:对 Estimator 提供有限支持。基本训练和评估都是实验性的,而未实现高级功能(如基架)。如未涵盖某一用例,建议您使用 Keras 或自定义训练循环。
MirroredStrategy 非常相似。它实现了跨多个工作进程的同步分布式训练,而每个工作进程可能有多个 GPU。简单来说,多机分布式通常使用的就是这个策略。该策略支持3种不同的collective communication模式:CollectiveCommunication.RINGCollectiveCommunication.NCCLCollectiveCommunication.AUTO
分布式示例
if distribution_strategy == "tpu":
# When tpu_address is an empty string, we communicate with local TPUs.
cluster_resolver = tpu_lib.tpu_initialize(tpu_address)
return tf.distribute.experimental.TPUStrategy(cluster_resolver)
if distribution_strategy == "multi_worker_mirrored":
return tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=_collective_communication(all_reduce_alg))
if distribution_strategy == "one_device":
if num_gpus == 0:
return tf.distribute.OneDeviceStrategy("device:CPU:0")
if num_gpus > 1:
raise ValueError("`OneDeviceStrategy` can not be used for more than "
"one device.")
return tf.distribute.OneDeviceStrategy("device:GPU:0")
if distribution_strategy == "mirrored":
if num_gpus == 0:
devices = ["device:CPU:0"]
else:
devices = ["device:GPU:%d" % i for i in range(num_gpus)]
return tf.distribute.MirroredStrategy(
devices=devices,
cross_device_ops=_mirrored_cross_device_ops(all_reduce_alg, num_packs))
if distribution_strategy == "parameter_server":
return tf.distribute.experimental.ParameterServerStrategy()
raise ValueError(
"Unrecognized Distribution Strategy: %r" % distribution_strategy)
tf.distribute.experimental.TPUStrategy tf.distribute.OneDeviceStrategy tf.distribute.experimental.MultiWorkerMirroredStrategy tf.distribute.MirroredStrategy tf.distribute.experimental.ParameterServerStrategy
if distribution_strategy == "tpu":
# When tpu_address is an empty string, we communicate with local TPUs.
cluster_resolver = tpu_lib.tpu_initialize(tpu_address)
return tf.distribute.experimental.TPUStrategy(cluster_resolver)
if distribution_strategy == "multi_worker_mirrored":
return tf.distribute.experimental.MultiWorkerMirroredStrategy(
communication=_collective_communication(all_reduce_alg))
if distribution_strategy == "one_device":
if num_gpus == 0:
return tf.distribute.OneDeviceStrategy("device:CPU:0")
if num_gpus > 1:
raise ValueError("`OneDeviceStrategy` can not be used for more than "
"one device.")
return tf.distribute.OneDeviceStrategy("device:GPU:0")
if distribution_strategy == "mirrored":
if num_gpus == 0:
devices = ["device:CPU:0"]
else:
devices = ["device:GPU:%d" % i for i in range(num_gpus)]
return tf.distribute.MirroredStrategy(
devices=devices,
cross_device_ops=_mirrored_cross_device_ops(all_reduce_alg, num_packs))
if distribution_strategy == "parameter_server":
return tf.distribute.experimental.ParameterServerStrategy()
raise ValueError(
"Unrecognized Distribution Strategy: %r" % distribution_strategy)
datasets = [builder.build(strategy)
if builder else None for builder in builders]
完整的利用ResNet50训练ImageNet的示例可参考:TensorFlow官方仓库(https://github.com/tensorflow/models/tree/r2.3.0/official/vision/image_classification) 分布式训练速度测评及结果,可以参考DLPerf:【DLPerf】TensorFlow 2.x-ResNet50V1.5测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/TensorFlow/resnet50v1.5)
3.PaddlePaddle

接口
分布式策略相关接口:paddle.fluid.incubate.fleet.collective.DistributedStrategy role_maker相关接口:paddle.fluid.incubate.fleet.base.role_maker optimizer相关接口:fluid.optimizer 分布式optimizer封装接口:fleet.distributed_optimizer
参考:Fleet Design Doc https://www.paddlepaddle.org.cn/tutorials/projectdetail/487871
分布式示例
# -*- coding: utf-8 -*-
import os
import numpy as np
import paddle.fluid as fluid
# 区别1: 导入分布式训练库
from paddle.fluid.incubate.fleet.collective import fleet, DistributedStrategy
from paddle.fluid.incubate.fleet.base import role_maker
# 定义网络
def mlp(input_x, input_y, hid_dim=1280, label_dim=2):
fc_1 = fluid.layers.fc(input=input_x, size=hid_dim, act='tanh')
fc_2 = fluid.layers.fc(input=fc_1, size=hid_dim, act='tanh')
prediction = fluid.layers.fc(input=[fc_2], size=label_dim, act='softmax')
cost = fluid.layers.cross_entropy(input=prediction, label=input_y)
avg_cost = fluid.layers.mean(x=cost)
return avg_cost
# 生成数据集
def gen_data():
return {"x": np.random.random(size=(128, 32)).astype('float32'),
"y": np.random.randint(2, size=(128, 1)).astype('int64')}
input_x = fluid.layers.data(name="x", shape=[32], dtype='float32')
input_y = fluid.layers.data(name="y", shape=[1], dtype='int64')
# 定义损失
cost = mlp(input_x, input_y)
optimizer = fluid.optimizer.SGD(learning_rate=0.01)
# 区别2: 定义训练策略和集群环境定义
dist_strategy = DistributedStrategy()
role = role_maker.PaddleCloudRoleMaker(is_collective=True)
fleet.init(role)
# 获得当前gpu的id号
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
print(gpu_id)
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
# 区别3: 对optimizer封装,并调用封装后的minimize方法
optimizer = fleet.distributed_optimizer(optimizer, strategy=DistributedStrategy())
optimizer.minimize(cost, fluid.default_startup_program())
train_prog = fleet.main_program
# 获得当前gpu的id号
gpu_id = int(os.getenv("FLAGS_selected_gpus", "0"))
print(gpu_id)
place = fluid.CUDAPlace(gpu_id)
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
step = 100
for i in range(step):
cost_val = exe.run(program=train_prog, feed=gen_data(), fetch_list=[cost.name])
print("step%d cost=%f" % (i, cost_val[0]))
# 区别4: 模型保存
model_path = "./"
if os.path.exists(model_path):
fleet.save_persistables(exe, model_path)
基于paddle.fluid接口,利用ResNet50网络训练ImageNet的示例可参考:PaddlePaddle官方仓库(https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleCV/image_classification) 分布式训练速度测评及结果,可以参考DLPerf:PaddlePaddle-ResNet50V1.5测评(https://github.com/Oneflow-Inc/DLPerf/tree/master/PaddlePaddle/resnet50v1.5) 基于Paddle分布式Fleet API,将单机的训练代码改造成分布式,可以参考:多机多卡训练(https://www.paddlepaddle.org.cn/tutorials/projectdetail/479613)
4.MXNet
概念
Worker Server Scheduler
1.聚合梯度但不应用更新 2.聚合梯度且更新权重
参考:
https://mxnet.cdn.apache.org/versions/1.7.0/api/faq/distributed_traininghttps://mxnet.apache.org/get_started/build_from_source
分布式示例
# Horovod: initialize Horovod
hvd.init()
num_workers = hvd.size()
rank = hvd.rank()
local_rank = hvd.local_rank()
num_workers,即当前节点上horovod工作进程数量,通常等于GPU数量; rank = hvd.rank(),是一个全局GPU资源列表; local_rank = hvd.local_rank()是当前节点上的GPU资源列表;
# Fetch and broadcast parameters
params = model.collect_params()
if params is not None:
hvd.broadcast_parameters(params, root_rank=0)
train_sampler = SplitSampler(len(train_set), num_parts=num_workers, part_index=rank)
train_data = gluon.data.DataLoader(train_set, batch_size=batch_size,# shuffle=True,
last_batch='discard', num_workers=data_nthreads,
sampler=train_sampler)
# Horovod: create DistributedTrainer, a subclass of gluon.Trainer
trainer = hvd.DistributedTrainer(params, opt)
if args.resume_states != '':
trainer.load_states(args.resume_states)
5.OneFlow
为什么单机版的代码/api不能应用到多机? 为什么还要手动管理数据集切分、分布式optimizer、参数更新这些脏活累活? 难道没有一种框架屏蔽掉单机和分布式代码的差异,让我们愉快地写代码?

单机/分布式下,共用一套接口(是真的共用,而不是外面一套,内部却有其各自的实现) 单机/分布式下,无需操心数据切分; 单机/分布式下,无需操心optimizer梯度更新、参数状态同步等问题; 单机/分布式下,性能最强(对GPU利用率最高),训练速度最快;


1.为什么能做到单机/分布式如此简单?
maste/worker 架构,最大程度优化节点网络通信效率 2.极简配置,由单一节点的训练程序转变为分布式训练程序,只需要几行配置代码更多oneflow底层设计、actor机制等请参考:OneFlow官方文档—分布式训练(https://docs.oneflow.org/basics_topics/distributed_train.html) ;OneFlow官方文档—系统设计(https://docs.oneflow.org/basics_topics/essentials_of_oneflow.html)
2.OneFlow分布式这么容易用,运行效率怎么样?
概念
分布式示例
单机
# 单机单卡
flow.config.gpu_device_num(1)
# 单机8卡
flow.config.gpu_device_num(8)
分布式
#每个节点的 gpu 使用数目
flow.config.gpu_device_num(8)
# 通信节点ip
nodes = [{"addr":"192.168.1.12"}, {"addr":"192.168.1.11"}]
flow.env.machine(nodes)
#通信端口
flow.env.ctrl_port(9988)
# see : http://docs.oneflow.org/basics_topics/distributed_train.html#_5
import oneflow as flow
import oneflow.typing as tp
BATCH_SIZE = 100
def mlp(data):
initializer = flow.truncated_normal(0.1)
reshape = flow.reshape(data, [data.shape[0], -1])
hidden = flow.layers.dense(
reshape,
512,
activation=flow.nn.relu,
kernel_initializer=initializer,
name="hidden",
)
return flow.layers.dense(
hidden, 10, kernel_initializer=initializer, name="output-weight"
)
def config_distributed():
print("distributed config")
# 每个节点的gpu使用数目
flow.config.gpu_device_num(8)
# 通信端口
flow.env.ctrl_port(9988)
# 节点配置
nodes = [{"addr": "192.168.1.12"}, {"addr": "192.168.1.11"}]
flow.env.machine(nodes)
@flow.global_function(type="train")
def train_job(
images: tp.Numpy.Placeholder((BATCH_SIZE, 1, 28, 28), dtype=flow.float),
labels: tp.Numpy.Placeholder((BATCH_SIZE,), dtype=flow.int32),
) -> tp.Numpy:
logits = mlp(images)
loss = flow.nn.sparse_softmax_cross_entropy_with_logits(
labels, logits, name="softmax_loss"
)
lr_scheduler = flow.optimizer.PiecewiseConstantScheduler([], [0.1])
flow.optimizer.SGD(lr_scheduler, momentum=0).minimize(loss)
return loss
if __name__ == "__main__":
config_distributed()
flow.config.enable_debug_mode(True)
check_point = flow.train.CheckPoint()
check_point.init()
(train_images, train_labels), (test_images, test_labels) = flow.data.load_mnist(
BATCH_SIZE, BATCH_SIZE
)
for epoch in range(1):
for i, (images, labels) in enumerate(zip(train_images, train_labels)):
loss = train_job(images, labels)
if i % 20 == 0:
print(loss.mean())
完整的利用ResNet50训练ImageNet的示例可参考:OneFlow官方Benchmark仓库(https://github.com/Oneflow-Inc/OneFlow-Benchmark/tree/637bb9cdb4cc1582f13bcc171acbc8a8089d9435/Classification/cnns) 分布式训练速度测评及结果,可以参考DLPerf:【DLPerf】OneFlow Benchmark评测(https://github.com/Oneflow-Inc/DLPerf/tree/master/OneFlow)
6.分布式训练常用库
数据层面 多机通讯层面 代码层面
6.1 DALI
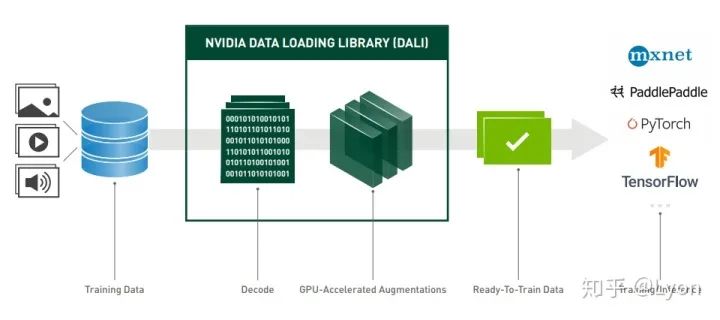
安装
# CUDA 10
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist nvidia-dali-cuda100
# CUDA 11
pip install --extra-index-url https://developer.download.nvidia.com/compute/redist nvidia-dali-cuda110
使用
DALI Home https://developer.nvidia.com/DALI Fast AI Data Preprocessing with NVIDIA DALI https://developer.nvidia.com/blog/fast-ai-data-preprocessing-with-nvidia-dali/ DALI Developer Guide https://docs.nvidia.com/deeplearning/dali/user-guide/docs/index.html Getting Started https://docs.nvidia.com/deeplearning/dali/user-guide/docs/examples/getting%20started.html nvidia-dali-speeding-up-pytorch https://towardsdatascience.com/nvidia-dali-speeding-up-pytorch-876c80182440
6.2 NCCL
安装
sudo dpkg -i nccl-repo-ubuntu1604-2.7.3-ga-cuda10.2_1-1_amd64.deb
sudo apt update
sudo apt install libnccl2=2.7.3-1+cuda10.2 libnccl-dev=2.7.3-1+cuda10.2
使用
export NCCL_DEBUG=INFO
export NCCL_DEBUG=WARN
export NCCL_SOCKET_IFNAME=enp
NCCL官方文档——故障排除 https://docs.nvidia.com/deeplearning/nccl/archives/nccl_273/user-guide/docs/troubleshooting.html NCCL官方文档——环境变量 https://docs.nvidia.com/deeplearning/nccl/archives/nccl_273/user-guide/docs/env.html
6.3 Horovod
我们需要使用框架提供的分布式API或者使用Horovod来对单机版(单机单卡/多卡)代码进行改造,以使其支持分布式任务。
安装
1.安装NCCL 2.安装nv_peer_memory(https://github.com/Mellanox/nv_peer_memory)以提供GPUDirect RDMA支持 3.安装Open MPI或者其他MPI实现 4.安装horovod
HOROVOD_WITH_MXNET=1 HOROVOD_GPU_OPERATIONS=NCCL HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_GPU_BROADCAST=NCCL
使用
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
torch.cuda.set_device(hvd.local_rank())
# Define dataset...
train_dataset = ...
# Partition dataset among workers using DistributedSampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=..., sampler=train_sampler)
# Build model...
model = ...
model.cuda()
optimizer = optim.SGD(model.parameters())
# Add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer, named_parameters=model.named_parameters())
# Broadcast parameters from rank 0 to all other processes.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
2.分布式常见问题汇总(踩坑指南)
通过以上的介绍,相信你已经具备了进行分布式训练的能力,在刚参与 DLPerf 时,我也是这样想的,直到多次跪倒在实际训练中。分布式训练本身也是各复杂工程,遇到的问题不难,但是可能因为第一次遇见而耽误进度很久。为了避免大家重蹈我的覆辙,特总结了一些经验教训,欢迎参考和补充。
2.1 精确到commit
2.2 使用具体到版本的库/依赖
2.2 多机问题
horovod/mpi多机运行失败 docker环境下ssh连通问题 多机没连通/长时间卡住没反应 多机下速度提升不明显,加速比低的问题
2.2.1 horovod/mpi多机运行失败
# export PORT=10001
horovodrun -np ${gpu_num} \
-H ${node_ip} -p ${PORT} \
--start-timeout 600 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}
# 或者:
mpirun --allow-run-as-root -oversubscribe -np ${gpu_num} -H ${node_ip} \
-bind-to none -map-by slot \
-x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_args "-p ${PORT} -q -o StrictHostKeyChecking=no" \
-mca btl_tcp_if_include ib0 \
python3 train.py ${CMD} 2>&1 | tee ${log_file}
ssh vs002或ssh vs002 \-p 100012.2.2 docker容器连通问题
docker的host模式 docker的bridge模式
2.2.3 多机没连通/长时间卡住没反应
通信库没有正确安装 存在虚拟网卡,nccl需指定网卡类型 通信端口被占用
wget https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.0.tar.gz
gunzip -c openmpi-4.0.0.tar.gz | tar xf -
cd openmpi-4.0.0
sudo ./configure --prefix=/usr/local/openmpi --with-cuda=/usr/local/cuda-10.2 --enable-orterun-prefix-by-default
sudo make && make install
sudo apt-get install libnuma-dev
vim ~/.bashrc
export PATH=$PATH:/usr/local/openmpi/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/openmpi/lib
source ~/.bashrc
HOROVOD_GPU_OPERATIONS=NCCL python -m pip install --no-cache-dir horovod
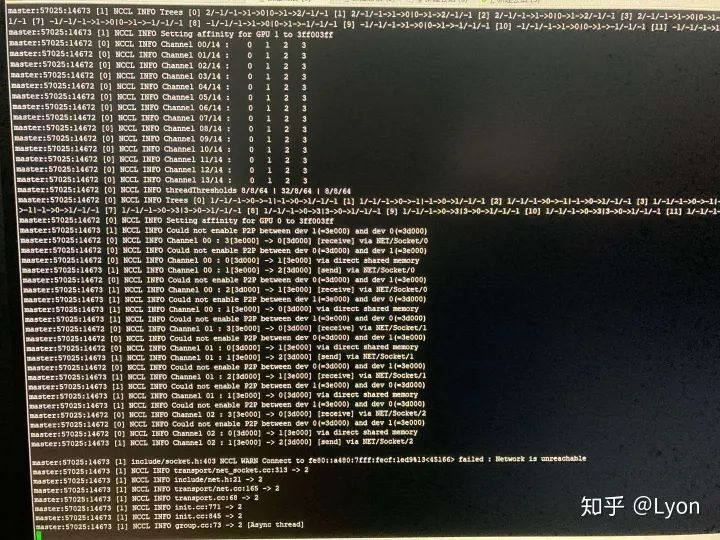
我们排查时,通过在发送端ping一个较大的数据包(如ping -s 10240 10.11.0.4),接收端通过bwm-ng命令查看每个网卡的流量波动情况(找出ping相应ip时,各个网卡的流量情况),发现可以正常连通,且流量走的是enp类型的网卡。
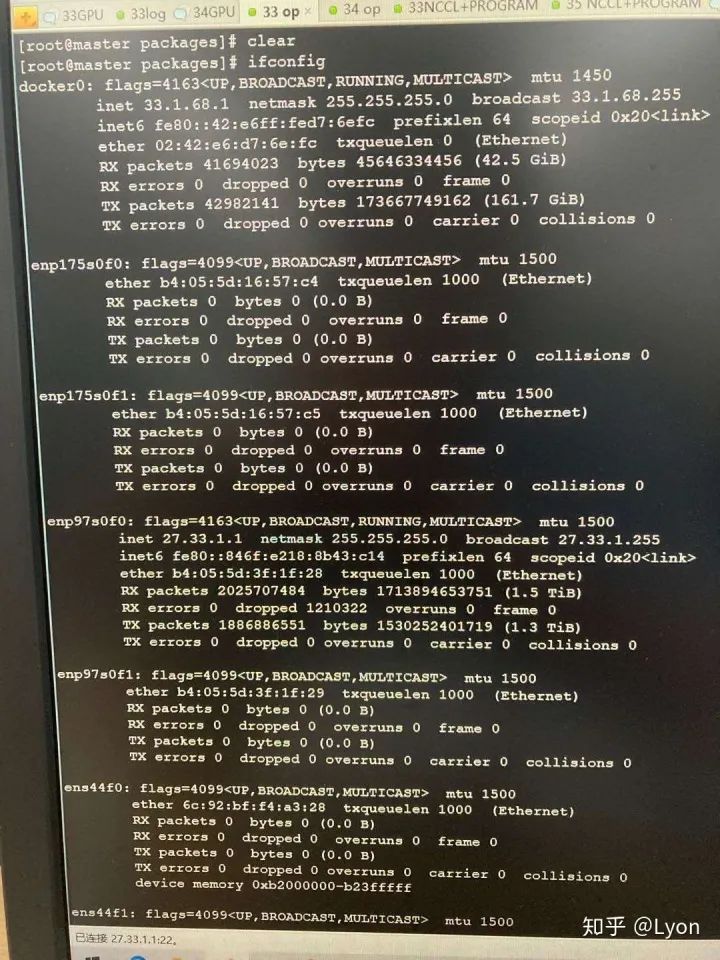
export NCCL_SOCKET_IFNAME=enp
2.2.4 加速比低
IB驱动安装
cd MLNX_OFED_LINUX-4.9-0.1.7.0-ubuntu18.04-x86_64 && ./mlnxofedinstall --user-space-only --without-fw-update --all --force
ibstat命令检查驱动是否安装成功。更详细的IB驱动安装,请参考:mellanox官方文档(https://community.mellanox.com/s/article/howto-install-mlnx-ofed-driver)horovod/mpi参数设置
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py
mpirun -oversubscribe -np ${gpu_num} -H ${nodes} \
-bind-to none -map-by numa \
-x NCCL_DEBUG=INFO -x LD_LIBRARY_PATH -x PATH \
-mca pml ob1 -mca btl ^openib \
-mca plm_rsh_args "-p 22 -q -o StrictHostKeyChecking=no" \
-mca btl_tcp_if_include ib0 \
python3 ${WORKSPACE}/run_pretraining.py
没有使用dali
数据读取线程数设置不合理
2.4 查看GPU拓扑
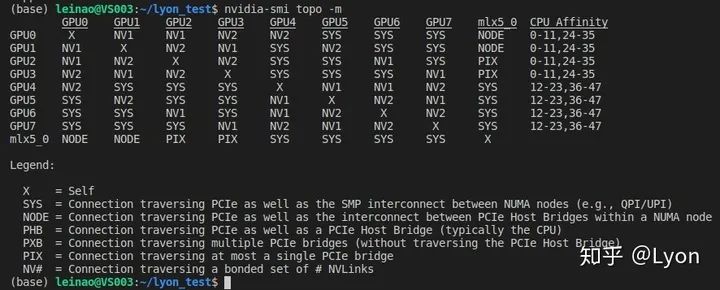
NV表示通过NVIDIA-nvlink互联,速度最快; PIX表示GPU间至多通过一个PCIe网桥连接; PHB表示通过PCIe和PCIe主网桥连接(通常PCIe 主网桥是存在于cpu之中,所以PHB可以理解为通过PCIe和cpu相连); NODE表示通过PCIe以及NUMA节点内PCIe主网桥之间的互连(通常NUMA节点内,包含多个cpu节点,每个cpu节点都包含一个PCIe主网桥,所以NODE可以理解为在一个NUMA节点内,通过PCIe和多个CPU相连); SYS表示通过PCIe以及NUMA节点之间的SMP互连(例如,QPI/UPI),这个可以理解为通过PCIe,且跨过多个NUMA节点及其内部的SMP(多个cpu节点)进行互联。 X表示gpu节点自身;
关于NUMA,SMP等服务器结构的简单介绍可参考:服务器体系(SMP, NUMA, MPP)与共享存储器架构(UMA和NUMA) https://blog.csdn.net/gatieme/article/details/52098615
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿 
▲长按关注公众号
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的知识点汇总、入门进阶学习路线、最新paper分享、疑问解答四个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近2000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款 
圈里有高质量教程资料、可答疑解惑、助你高效解决问题 觉得有用,麻烦给个赞和在看~ 

