 印象Python
印象Python





点击上方蓝字关注我们
[课程亮点]
1.系统分析网页性质
2.结构化的数据解析
3. csv数据保存
爬虫案例的一般步骤;
1.找到数据所对应的链接地址
2.发送指定链接地址的请求(代码)
3.解析出我们需要的数据
4.数据的保存
[环境介绍]:
python 3.9
pycharm 2020.3
requests
parsel
CSV
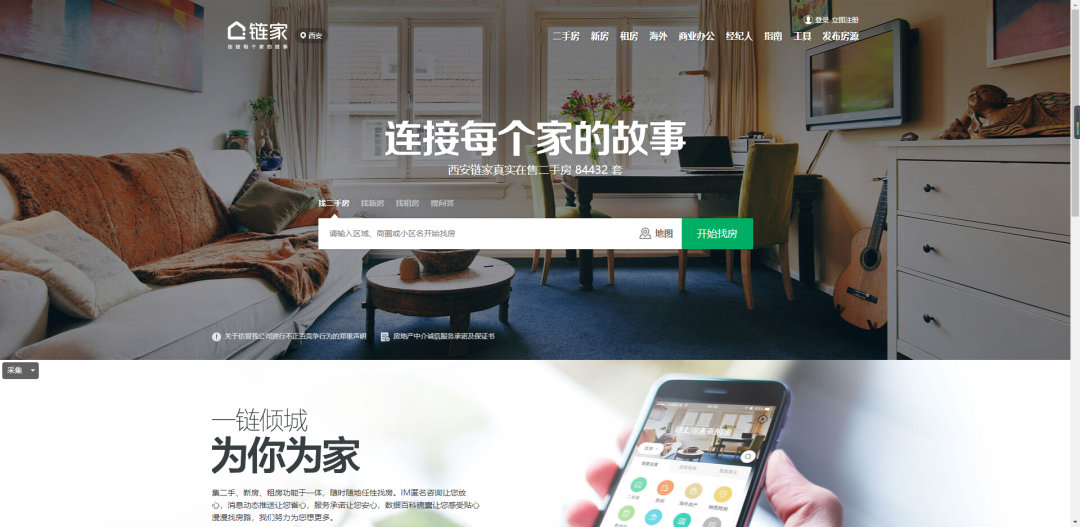
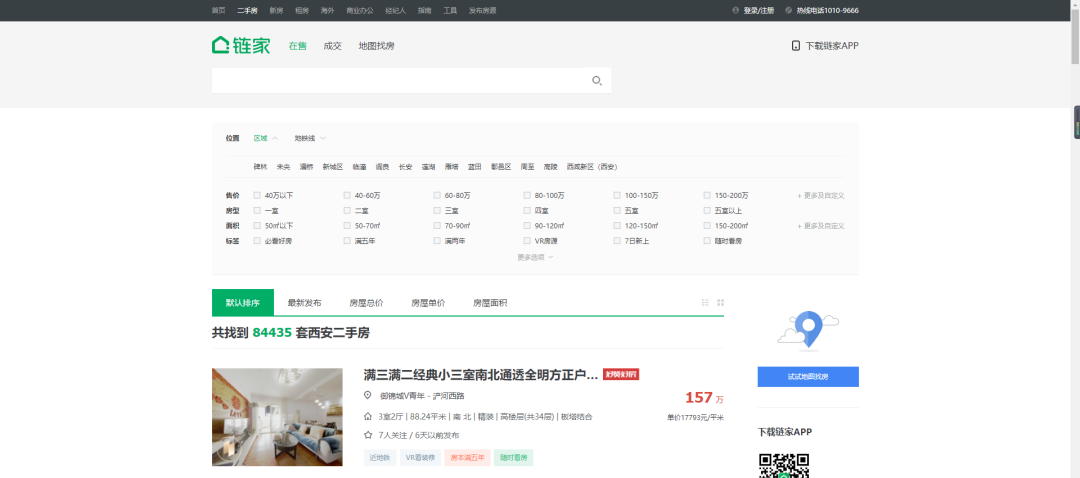
1.找到数据所对应的链接地址。咱们要采集的数据是二手房的房源信息。
https://xa.lianjia.com/ershoufang/
def get_url(url):
#伪装成浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4356.6 Safari/537.36',
'Referer': 'https://xa.lianjia.com/?utm_source=baidu&utm_medium=pinzhuan&utm_term=biaoti&utm_content=biaotimiaoshu&utm_campaign=wyxian',
}
try:
#发送链接请求响应
html = requests.get(url,headers = headers)
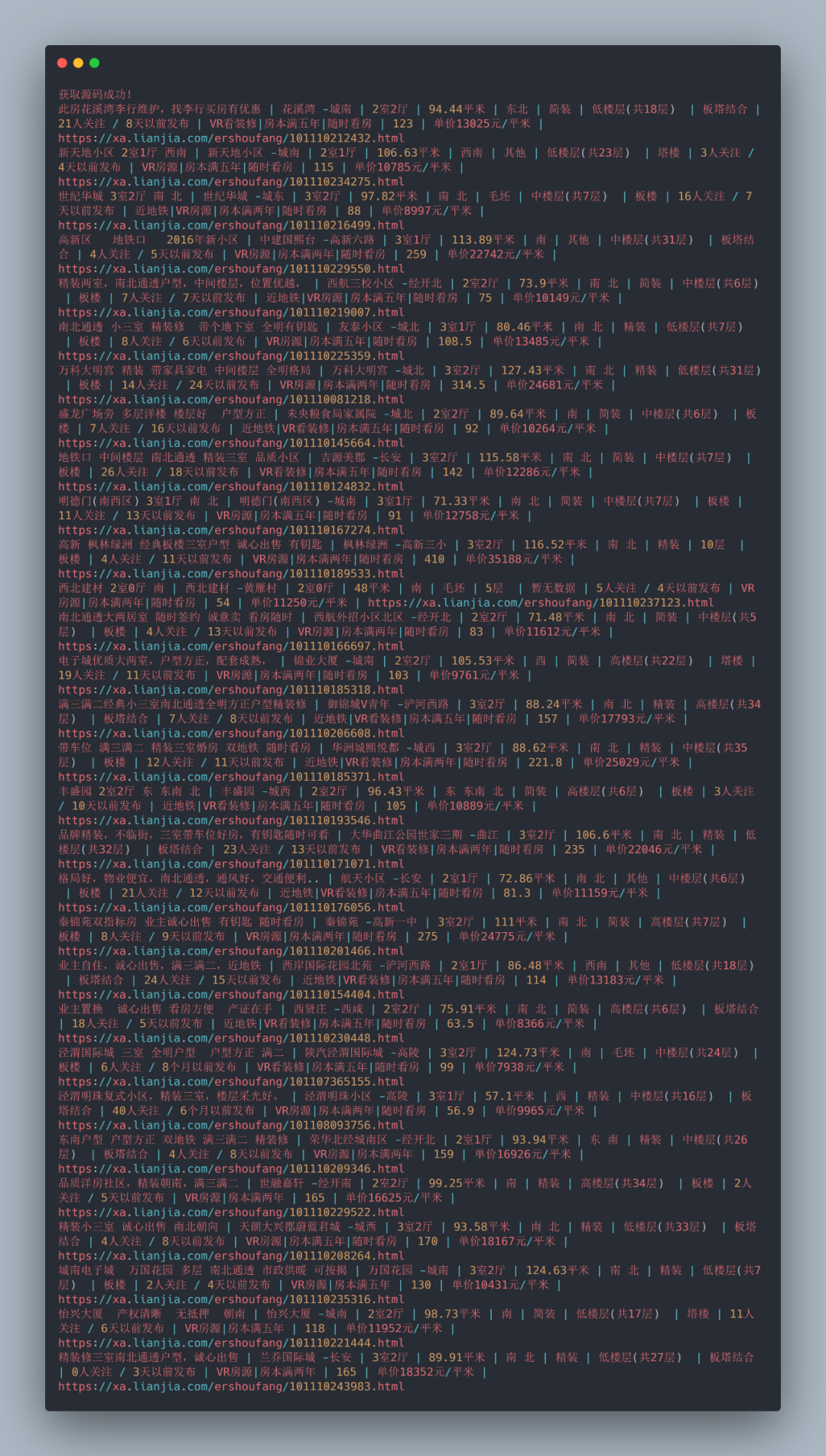
if html.status_code == 200:
print('获取源码成功!')
print(html.text)
except Exception as e:
print('获取源码失败:%s' % e)
return html.text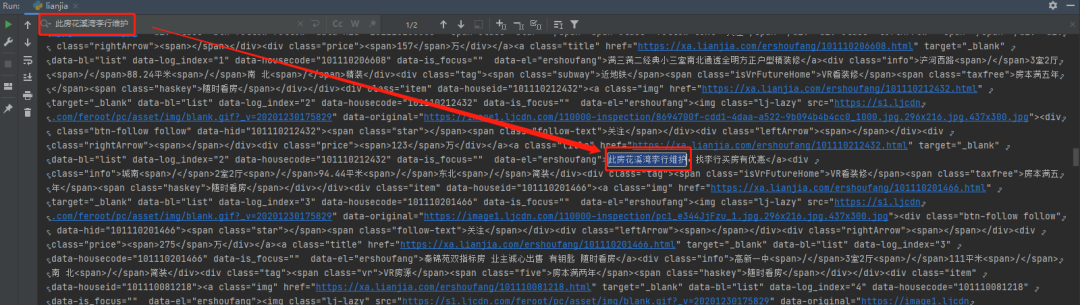
#解析源码
def parse_html(html):
#转换数据类型
html = etree.HTML(html)
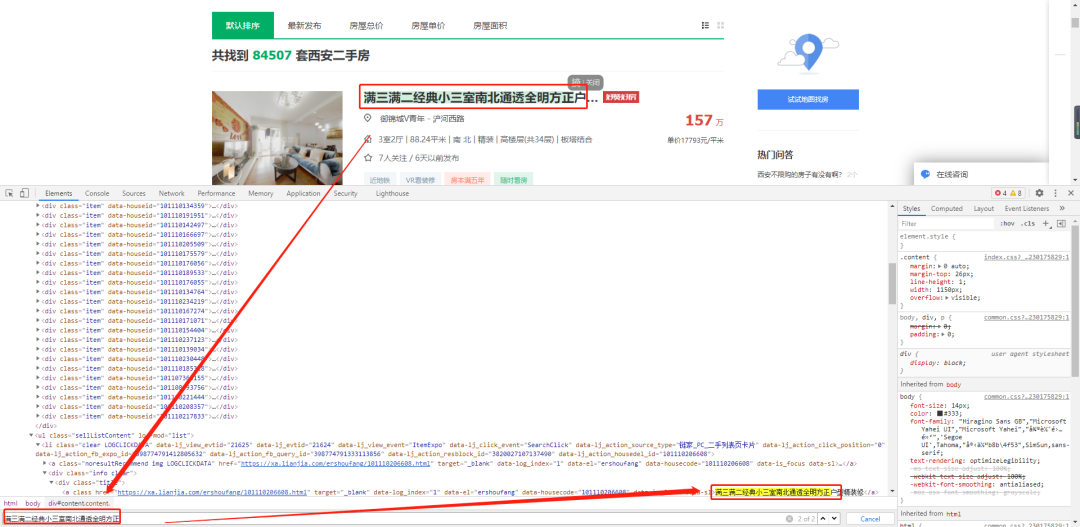
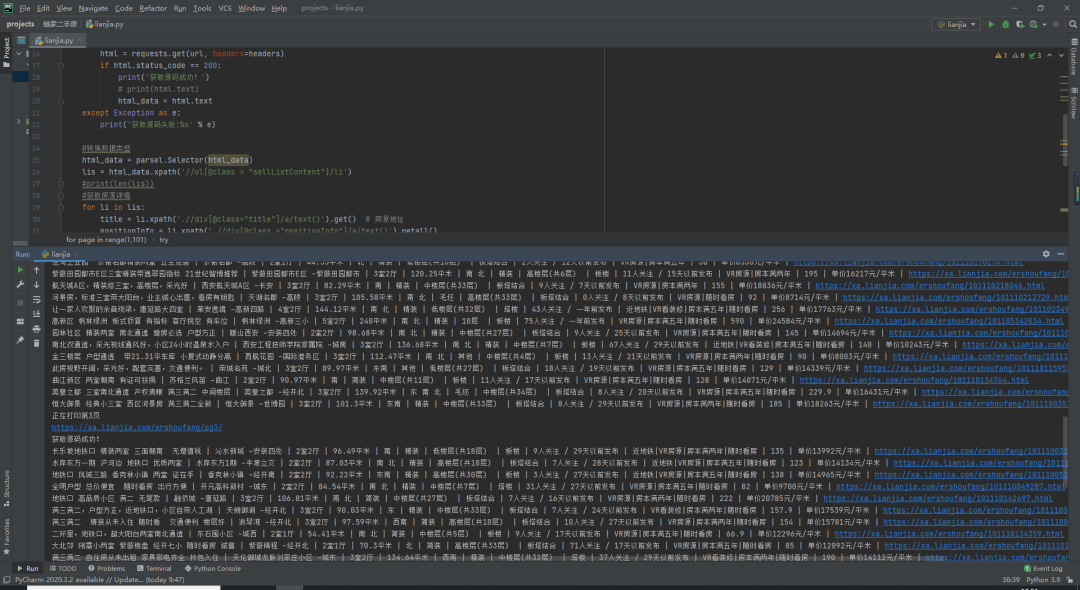
lis = html.xpath('//ul[@class = "sellListContent"]/li')
print(len(lis)) #31

#获取房源详情
for li in lis:
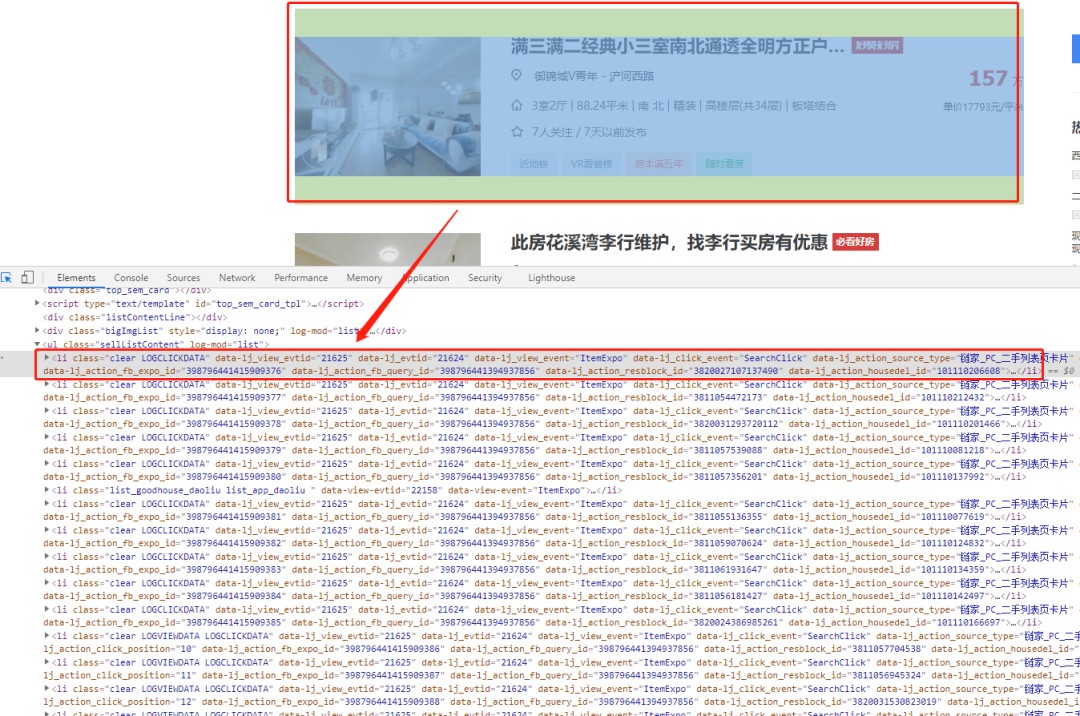
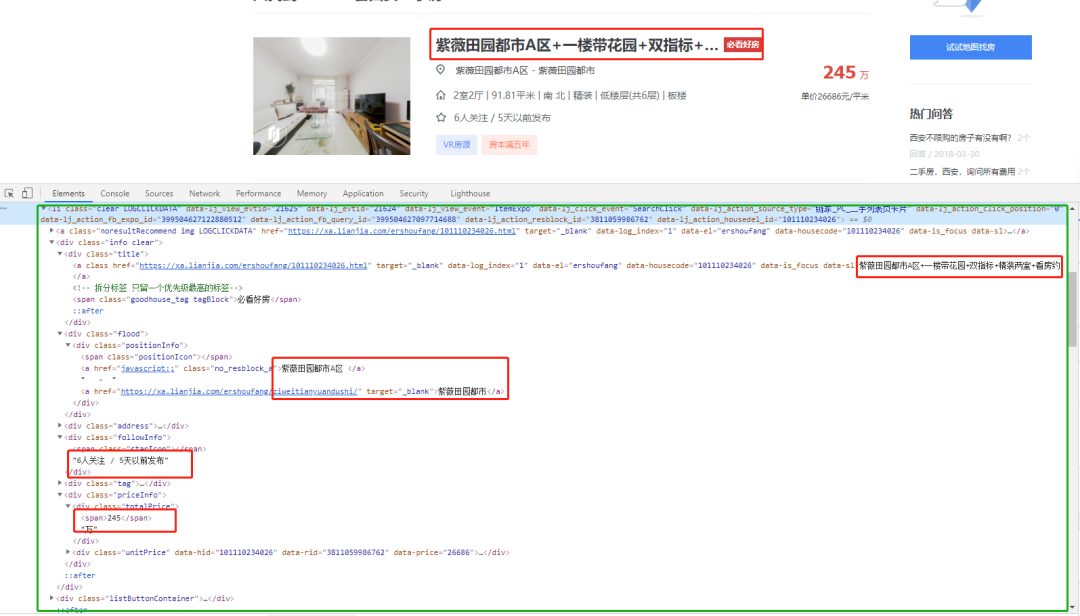
title = li.xpath('.//div[@class="title"]/a/text()').get() # 房源地址
positionInfo = li.xpath('.//div[@class ="positionInfo"]/a/text()').getall()
positionInfo = '-'.join(positionInfo) # 房源位置
houseInfo = li.xpath('.//div[@class = "houseInfo"]/text()').get() # 房源信息
followinfo = li.xpath('.//div[@class = "followInfo"]/text()').get() # 关注信息
tag = li.xpath('.//div[@class = "tag"]/span/text()').getall()
tag = '|'.join(tag) # 房源标签
TotalPrice = li.xpath('.//div[@class = "totalPrice"]/span/text()').get() # 房源总价
unitPrice = li.xpath('.//div[@class = "unitPrice"]/span/text()').get() # 房源单价
detaillink = li.xpath('.//div[@class = "title"]/a/@href').get() # 房源详情
print(title, positionInfo, houseInfo, followinfo, tag, TotalPrice, unitPrice, detaillink, sep=' | ')
with open('穷游网数据.csv', mode='a', encoding='utf-8', newline='') as f:
csv_write = csv.writer(f)
csv_write.writerow([title, positionInfo, houseInfo, followinfo, tag, TotalPrice, unitPrice, detaillink])
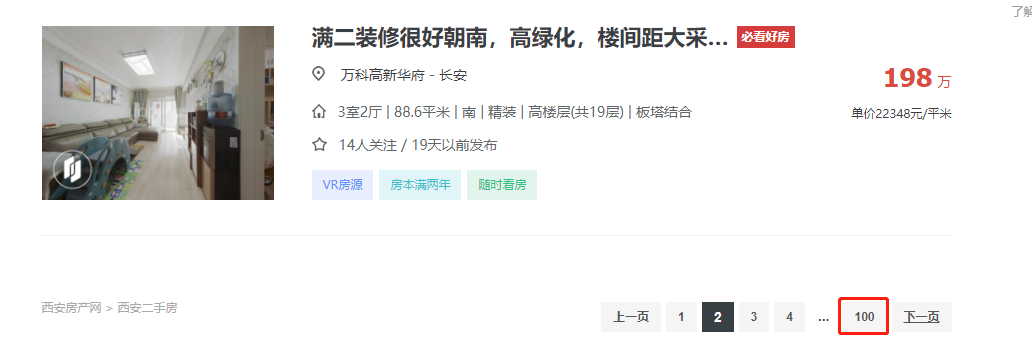
第一页:https://xa.lianjia.com/ershoufang/
第一页:https://xa.lianjia.com/ershoufang/pg2/
第一页:https://xa.lianjia.com/ershoufang/pg3/
第N页:https://xa.lianjia.com/ershoufang/pgN/ for page in range(1,101):
print('正在打印第{}页'.format(page))
#找到数据所对应的url(网址)
url = 'https://xa.lianjia.com/ershoufang/pg{}/'.format(page)
扫描二维码
获取更多精彩
印象python

回复下方 「关键词」,获取优质资源
回复关键词 「linux」,即可获取 185 页 Linux 工具快速教程手册和154页的Linux笔记。
回复关键词 「Python进阶」,即可获取 106 页 Python 进阶文档 PDF
回复关键词 「Python面试题」,即可获取最新 100道 面试题 PDF
回复关键词 「python数据分析」,即可获取47页python数据分析与自然语言处理的 PDF
回复关键词 「python爬虫」,满满五份PPT爬虫教程和70多个案例
回复关键词 「Python最强基础学习文档」,即可获取 168 页 Python 最强基础学习文档 PDF,让你快速入门Python 推荐我的微信号
来围观我的朋友圈,我的经验分享,技术更新,不定期送书,坑位有限,速速扫码添加!
备注:开发方向_昵称_城市,另送你10本Python电子书。




点个在看你最好看

