 公众号CVer
公众号CVer




点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
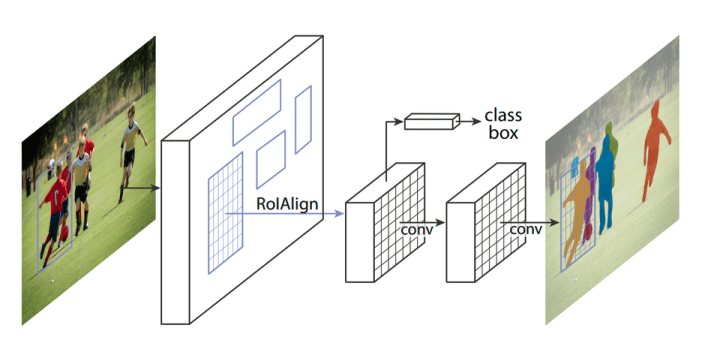
1 Why do we modify RoI Pooling?
RoI Pooling losses in quantization (dark and light blue), data gain (green)
每次ROI Pooling过程,关于对象的部分信息就会丢失,降低了整个模型的精度。
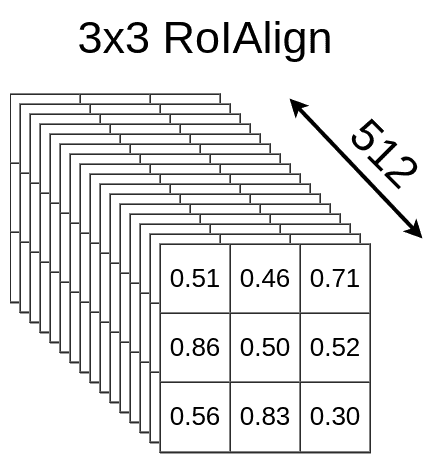
2 Setup
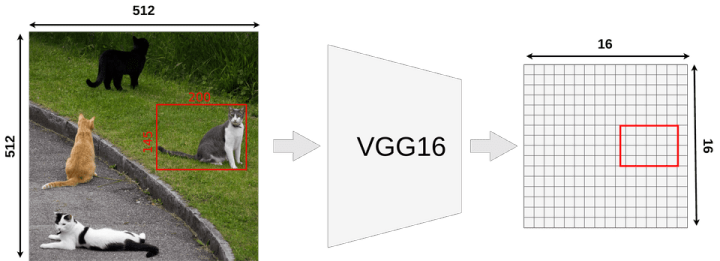
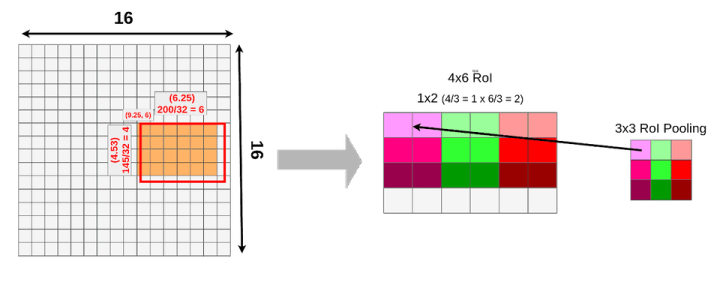
在开始之前,需要快速介绍一下。我们的模型采用512x512x3(宽x高x通道)的图像输入,VGG16将其映射到一个16x16x512特征映射。比例因子为32。如下图所示:
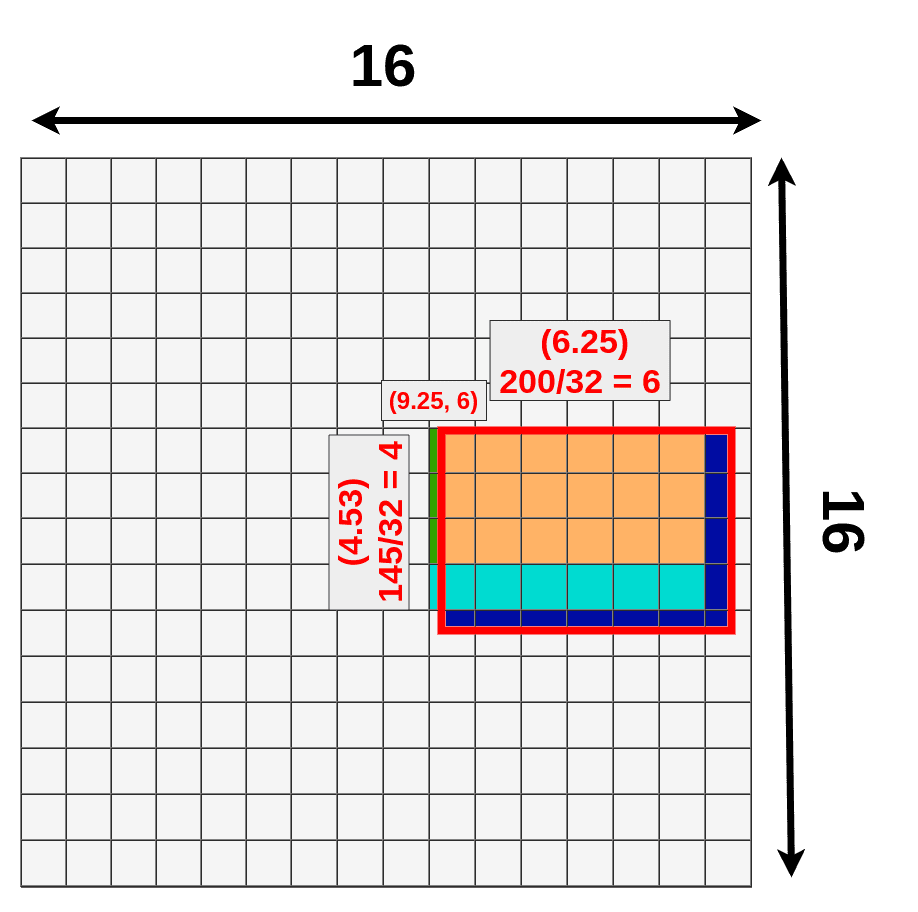
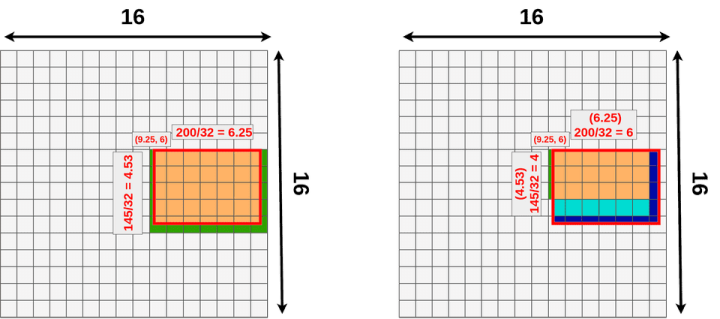
接下来,我们使用一个建议的RoI(145x200 box),并尝试将其映射到特征映射图上。因为并不是所有的对象维度都可以除以32,所以该 ROI 映射到特征图上效果如下:
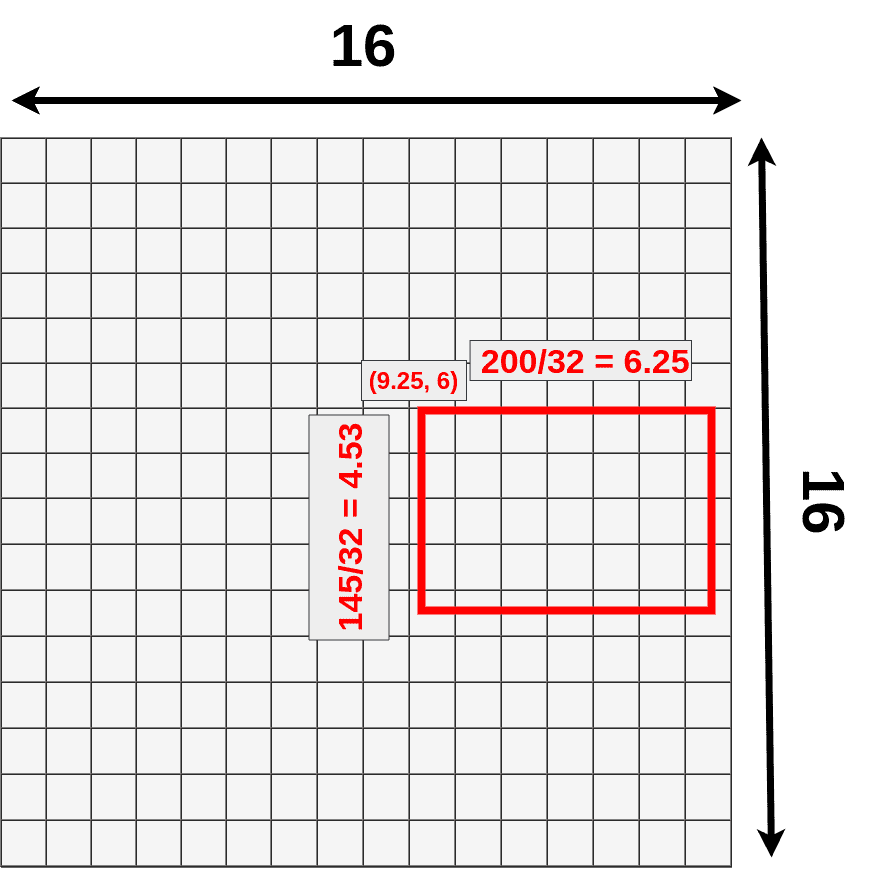
(9.25,6) — top left corner 6.25 — width
4.53 — height
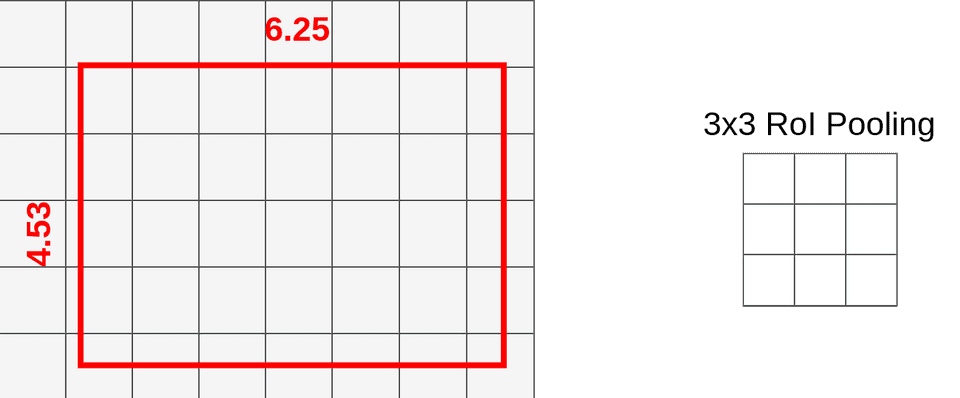
到目前为止,一切看起来都和RoI Pooling完全一样。
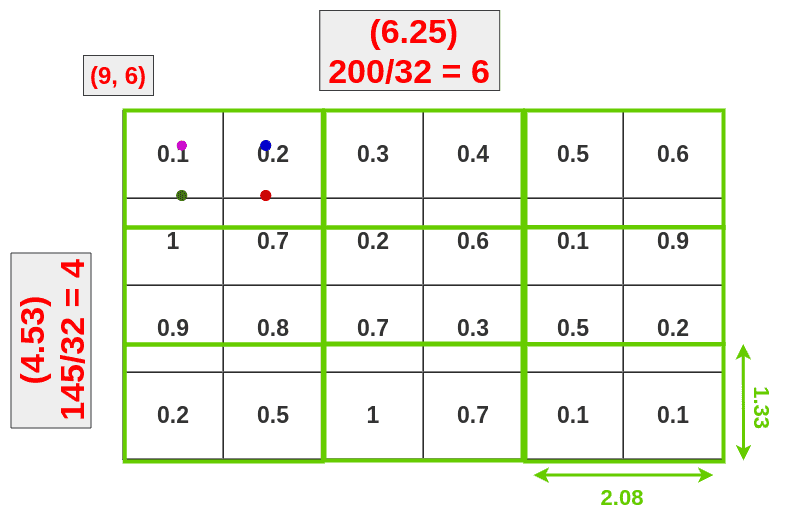
3 RoI Align
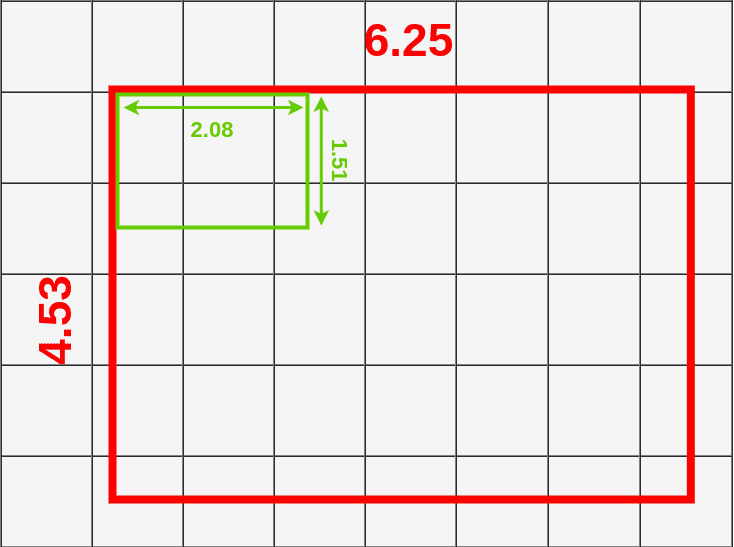
而RoI Align把原始的RoI分成9个大小相等的盒子,并在每个盒子里应用双线性插值。然后定义方框:每个框的大小由映射的RoI的大小和Pooling的大小决定。我们使用3x3的池层,所以必须将映射的RoI(6.25x4.53)除以3。这给了我们一个高度为1.51,宽度为2.08的长方体(我在这里对值进行舍入以使其更容易)。
现在,我们可以将方框放入映射的RoI中:
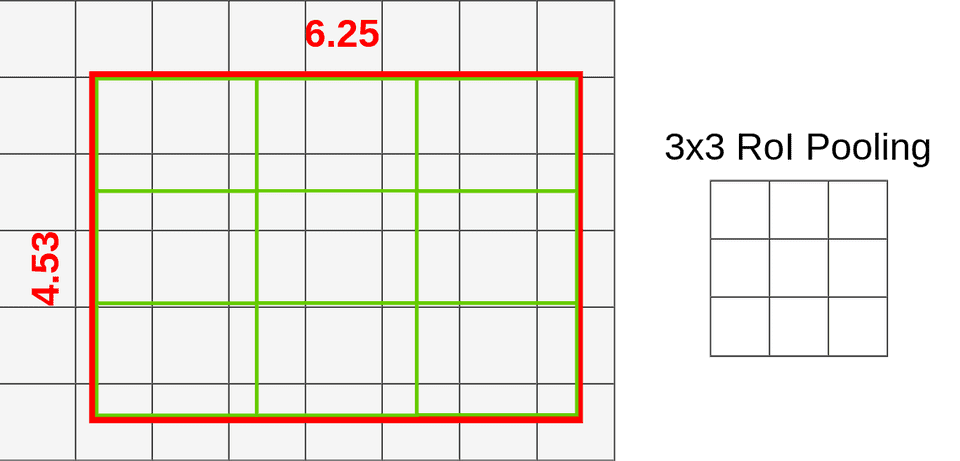
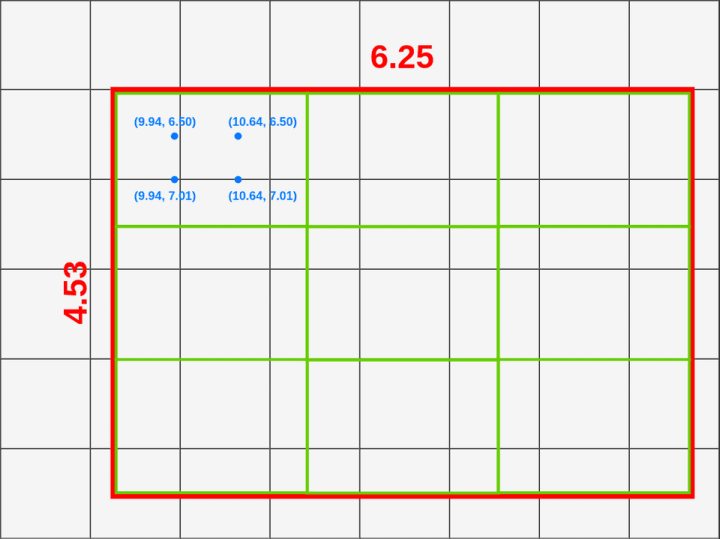
您可以通过将框的高度和宽度除以3来计算每个点的位置。
X = X_box + (width/3) * 1 = 9.94Y = Y_box + (height/3) * 1 = 6.50
X = X_box + (width/3) * 1 = 9.94Y = Y_box + (height/3) * 2 = 7.01
现在当我们有了所有的点,我们可以应用双线性插值来采样这个盒子的数据。双线性插值通常用于图像处理中对颜色进行采样,其方程如下所示:
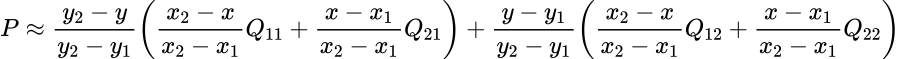
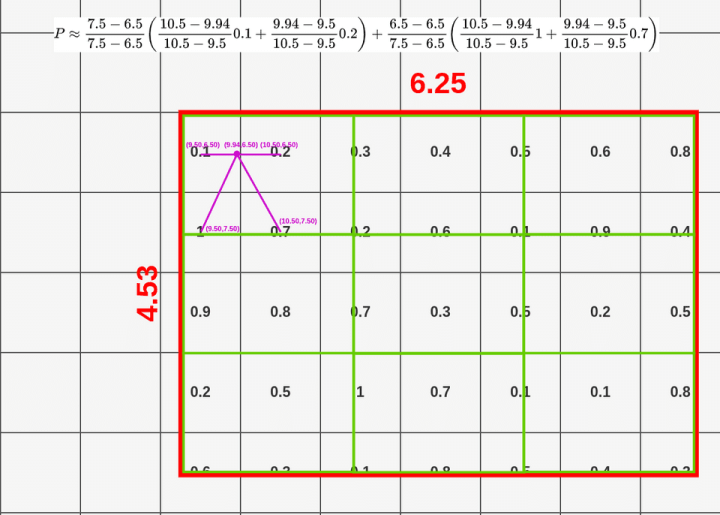
与其试着去理解这个等式,不如看看它是如何工作的:
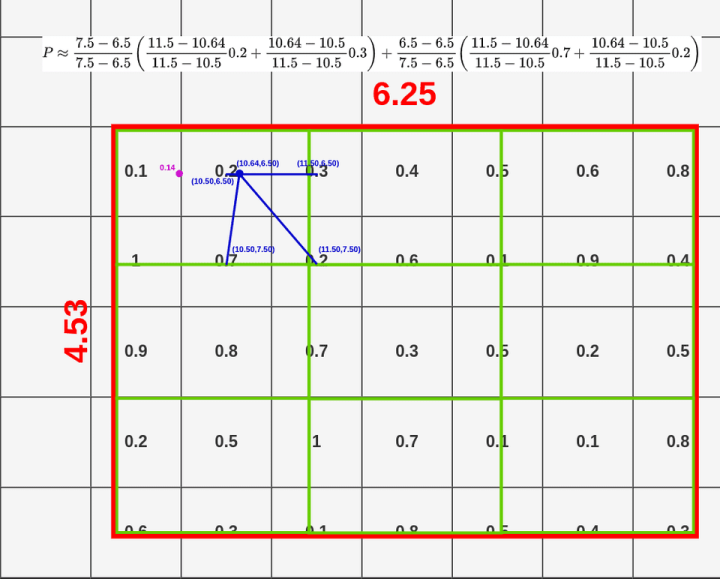
top-left: (10.50, 6.50)bottom-left: (10.50, 7.50)top-right: (11.50, 6.50)bottom-right: (11.50, 7.50)
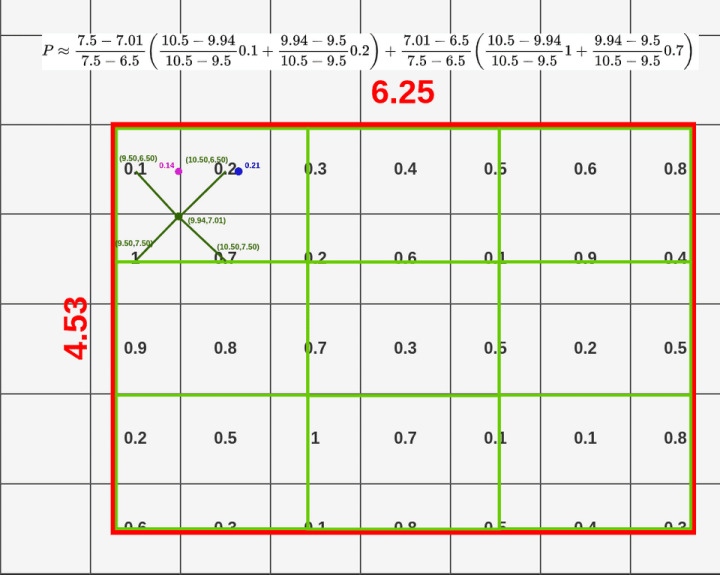
top-left: (9.50, 6.50)bottom-left: (9.50, 7.50)top-right: (10.50, 6.50)bottom-right: (10.50, 7.50)
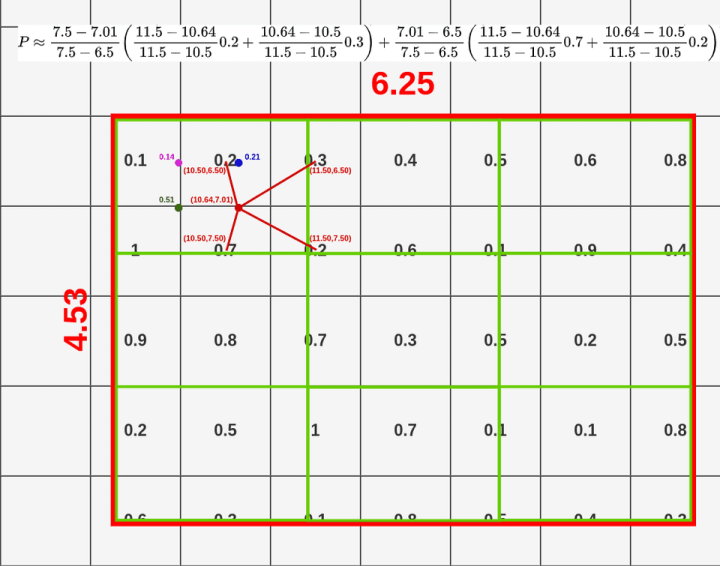
top-left: (10.50, 6.50)bottom-left: (10.50, 7.50)top-right: (11.50, 6.50)bottom-right: (11.50, 7.50)
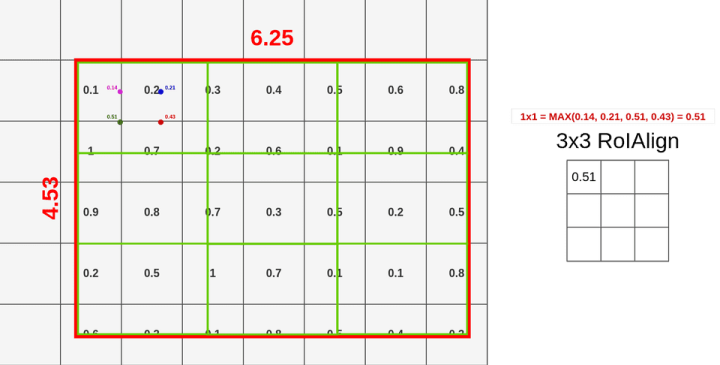
我不打算向你们展示所有的插值,因为这需要很长时间,而且你们可能已经知道怎么做了。因为,这个过程适用于每一层,因此最终结果包含512层(与要素图输入相同)
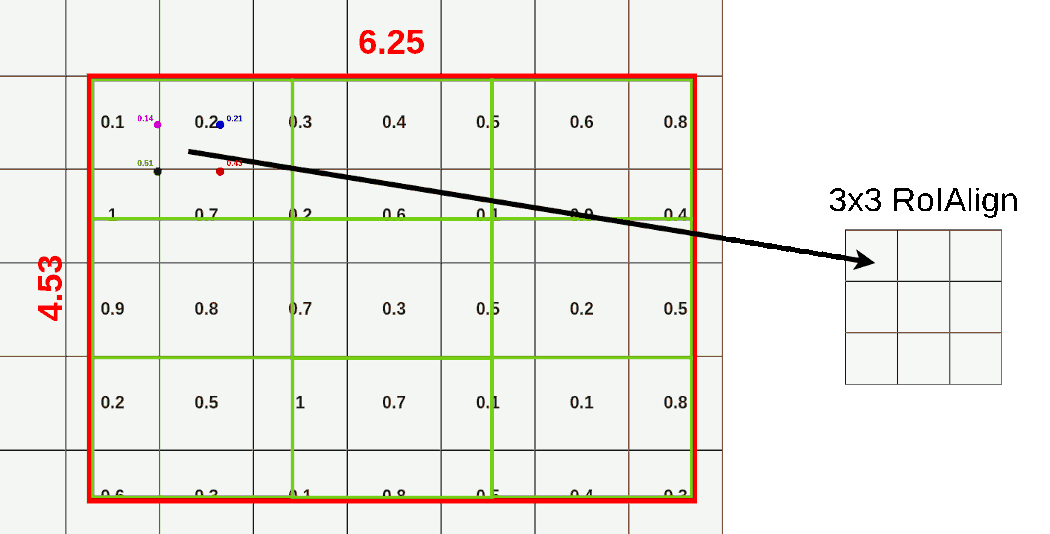
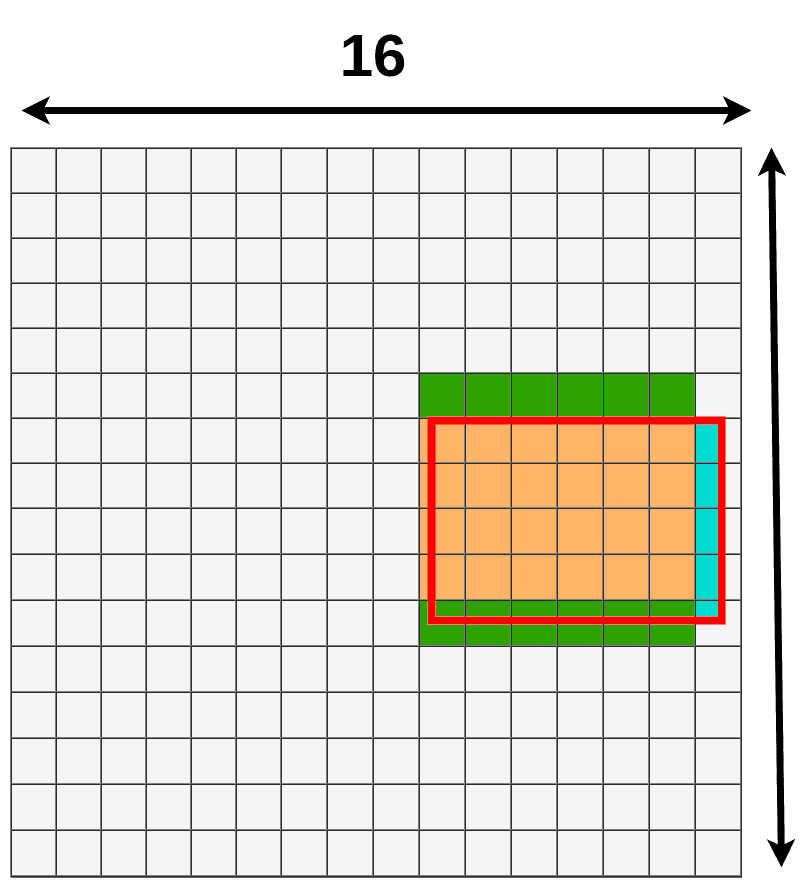
请注意,我们没有将采样点放在特征映射的所有单元格内,而是通过双线性插值从中提取数据。
Comparing RoIAlign(left) and RoIPooling(right) data sources.
绿色表示用于Pooling 的附加数据;蓝色表示合并时数据丢失。
4 RoIWarp
RoIWarp 方法是通过 Instance-aware semantic segmentation via multi-task network cascades 中引入的,称为RoIWarp。RoIWarp的思想或多或少与RoIAlign相同,唯一不同的是RoIWarp将RoI映射量化到特征映射上。
如果你看看数据丢失/数据增加:
由于双线性插值,RoIWarp只损失了一小部分。
5 How RoIAlign and RoIWarp affects the precision
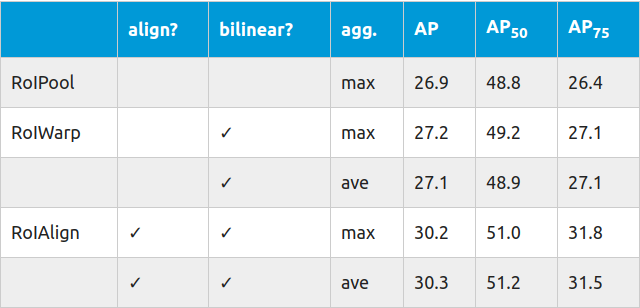
当应用RoIWarp时,只有一个小的改进,但是应用RoI Align可以显著提高精度。
而且这种提升随着步幅的增加而增加:
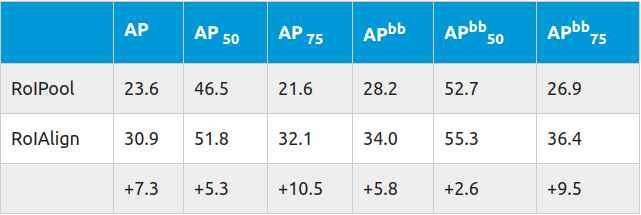
其中APbb是检测边界框的平均精度。测试在ResNet-50-C5上进行,步长为32。
6 Summary
当我们想提高R-CNN模型的准确性时,理解RoI Pooling是很重要的。2014年关于Fast R-CNN的论文中提出的标准方法与2018年关于Mask R-CNN的论文中提出的新方法之间存在显著差异,这并不意味着这些方法只适用于特定的网络,我们可以很容易地在快速R-CNN中使用RoI Align,在Mask R-CNN中使用RoI Pooling,但是RoIAlign可以使平均精度更高。
References:
R. Girshick. Fast R-CNN. In ICCV, 2014 https://arxiv.org/pdf/1504.08083.pdf
J. Dai, K. He, and J. Sun. Instance-aware semantic segmentation via multi-task network cascades. In CVPR, 2016 https://arxiv.org/pdf/1512.04412.pdf
K. He, G. Gkioxari, P. Dollar and R. Girshick. Mask R-CNN In ICCV, 2018 https://arxiv.org/pdf/1703.06870.pdf
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2400+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!![]()

