 ZhouFall
ZhouFall




很久之前曾经写过一篇听什么歌都像是在唱自己的推送,写的是网易云的歌,可以点一以下链接穿越。听什么歌,都像在唱自己今天我们不是来谈音乐情怀的,而是python爬虫技术分享。接上一篇下厨房的爬虫文章,这次给大家带来的是网易云爬虫。利用爬虫爬取我喜欢的音乐前1000个并做成词云图。
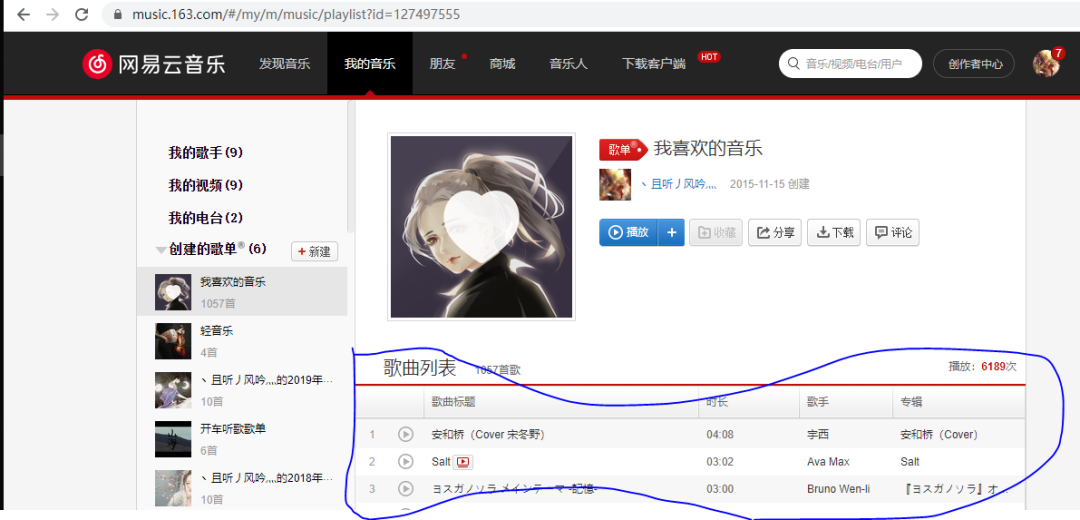
分解一下项目,首先需要找到对应的链接,然后把歌曲名字,演唱者,专辑图片下载下来。如下图所示,可以看到,网易云我喜欢的音乐里面有1000多个,这里我们取前1000个进行分析。
说干就干,request搞起来
import requestsurl = 'https://music.163.com/#/my/m/music/playlist?id=127497555'res = requests.get(url=url)print(res.text)
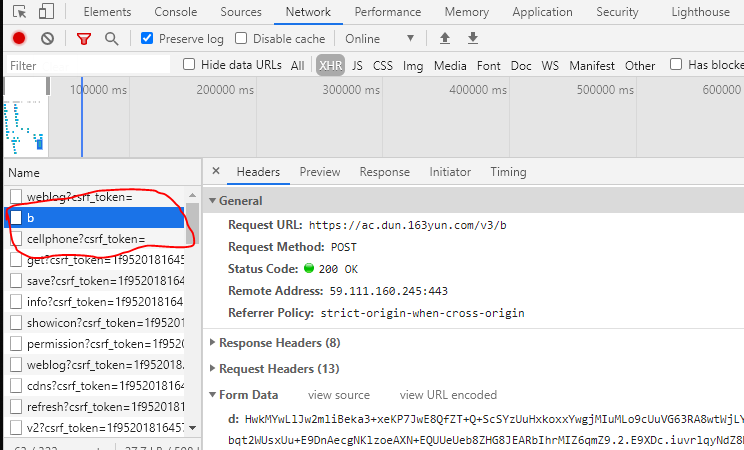
一顿操作之后,你会发现,虽然你get到了正确的响应码200,页获取了网页的内容,但是内容确是重定向到music.163.com,看返回的内容就知道是登录界面。这时候猜想,因为没有登录所以返回让你登录的页面。这时候就要想办法模拟登录。模拟登录需要找到登录网址。登录的时候按F12查看Network选项下的记录,刷新的网页比较多,可以加个过滤,只看XHR(可以简单理解为post请求)可以参考下图。b对应的网站是提交登录按钮的时候发送的请求,返回的只是一个状态,没有内容。下面一个cellphone像是手机登录的实际入口,返回的都是和个人账户相关的内容。#返回的内容里有手机号登录<div class="f-mgt10"><a href="javascript:;" data-action="login" data-type="mobile" class="u-btn2 u-btn2-2"><i>手机号登录</i></a></div>
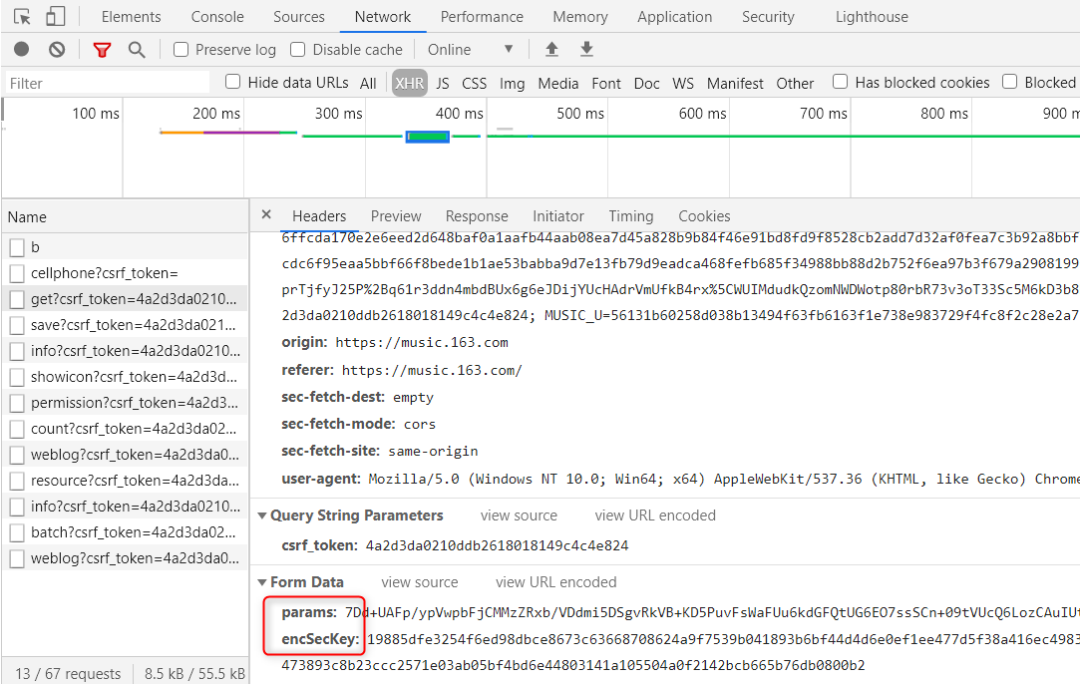
研究这两个请求,尝试向这两个网址提交账号密码 数据https://ac.dun.163yun.com/v3/b , https://music.163.com/weapi/user/grabed/status/get?csrf_token=4a2d3da0210ddb2618018149c4c4e824,使用post方法,带上需要提交的账户密码,结果得不到正确的响应。在data里加上'remember':'True'后,还是得不到200响应。
这时候百度搜了一下先驱们的做法和思路。原来网易云进行了js加密。你提交的数据需要经过算法加密了之后提交。而且同一个输入,每一次加密的结果是不同的。data = {'username':'','password':'','remember':''}res = requests.post(url=url,headers=headers,data=data)
这个加密过程是通过研究网易云刷新页面的时候调用的js文件,然后搜索关键字encSecKey得到,这几个abcde来回倒腾,捋清楚他们之间的关系,解密算法就可以写出来了。# 生成16个随机字符def generate_random_strs(length):string = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789"# 控制次数参数ii = 0# 初始化随机字符串random_strs = ""while i < length:e = random.random() * len(string)# 向下取整e = math.floor(e)random_strs = random_strs + list(string)[e]i = i + 1return random_strs# AES加密def AESencrypt(msg, key):# 如果不是16的倍数则进行填充(paddiing)padding = 16 - len(msg) % 16# 这里使用padding对应的单字符进行填充msg = msg + padding * chr(padding)# 用来加密或者解密的初始向量(必须是16位)= '0102030405060708'cipher = AES.new(bytearray(key,'utf-8'),AES.MODE_CBC, bytearray(iv,'utf-8'))# 加密后得到的是bytes类型的数据encryptedbytes = cipher.encrypt(bytearray(msg,'utf-8'))# 使用Base64进行编码,返回byte字符串encodestrs = base64.b64encode(encryptedbytes)# 对byte字符串按utf-8进行解码= encodestrs.decode('utf-8')return enctext# RSA加密def RSAencrypt(randomstrs, key, f):# 随机字符串逆序排列string = randomstrs[::-1]# 将随机字符串转换成byte类型数据text = bytes(string, 'utf-8')seckey = int(codecs.encode(text, encoding='hex'), 16)**int(key, 16) % int(f, 16)return format(seckey, 'x').zfill(256)# 获取参数:msg = textkey = '0CoJUm6Qyw8W8jud'f = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'e = '010001'enctext = AESencrypt(msg, key)# 生成长度为16的随机字符串i = generate_random_strs(16)# 两次AES加密之后得到params的值encText = AESencrypt(enctext, i)# RSA加密之后得到encSecKey的值encSecKey = RSAencrypt(i, e, f)return encText, encSecKey
理解这个加密解密过程并不难,重点是需要自己动手实践一遍。博主大神们想要爬取的网站跟我的并不相同,网上的参考资料也不全对,需要自己动手实践。动手实践步骤可参考参考链接 '糕糕python'的博文 https://www.jianshu.com/p/a45714d16294 网易云音乐爬虫(JS破解全过程)
知道了js解密之后,还需要知道对什么数据进行加密,就是你加密的数据格式是怎样的,这一步需要抓包工具。这里我们使用fiddler。梳理加密过程实践安装fiddler软件,fiddler所有权使用说明以fiddler官网为准
安装好之后熟悉界面操作,我们主要使用左边的界面来关注所有的收发消息和右边工具栏下的AutoResponder(fiddler需要安装一下认证证书,浏览器和网页的通信会出问题)
因为登录提交数据的时候,是经过js加密的,我们更改一下fiddler的默认配置,使得访问js的消息会黄色高亮
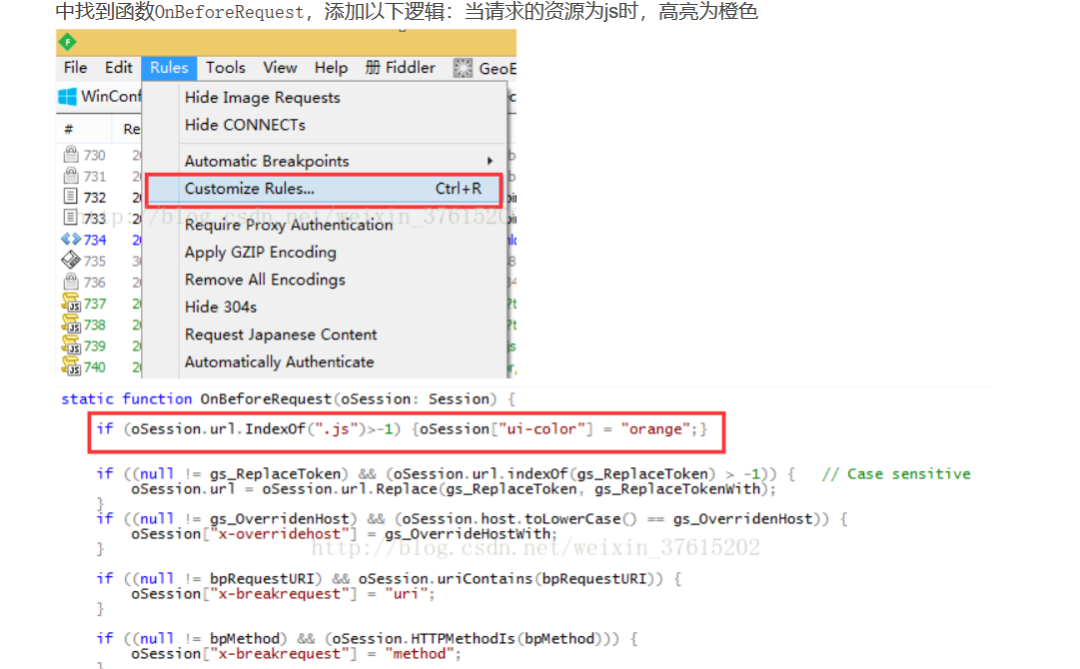
在network里面Initiator里面可以查看对应的js文件,在浏览器中可以将js保存到本地查看。我们需要关注的是core.js(网站上core后面会带一串数字)
有点代码基础的小伙伴可以把这个js的调用关系捋一下,捋完了就可以看懂博主们写的代码
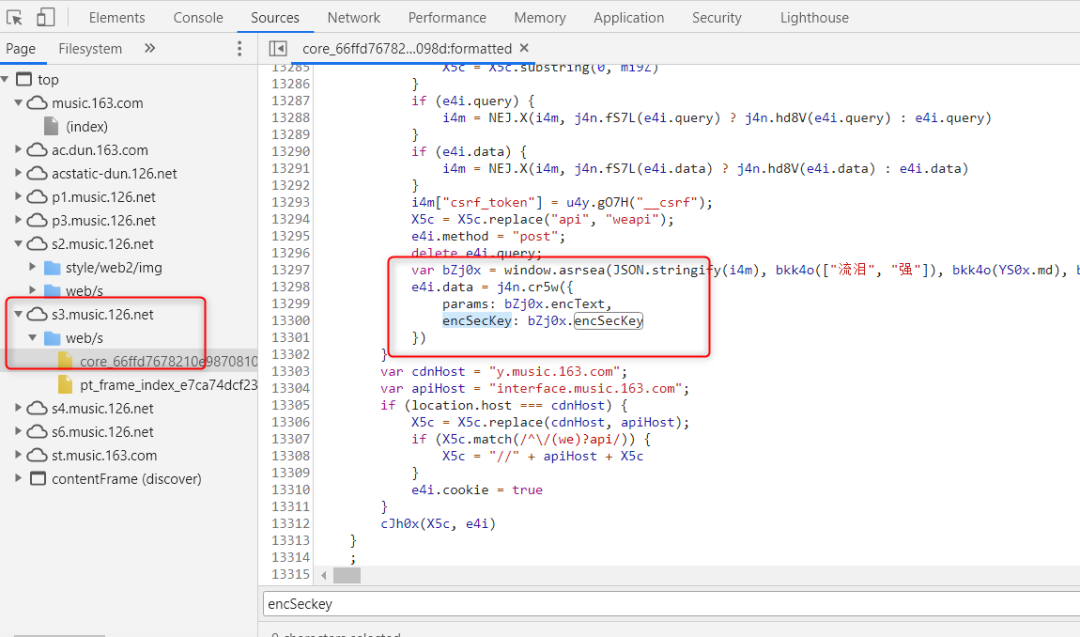
js文件里面是加密过程的破解,这个加密是有一个输入的,这个输入是需要通过打印的方式得到的,这个是我们提交数据的格式。在本地的js文件里加上这两句打印。
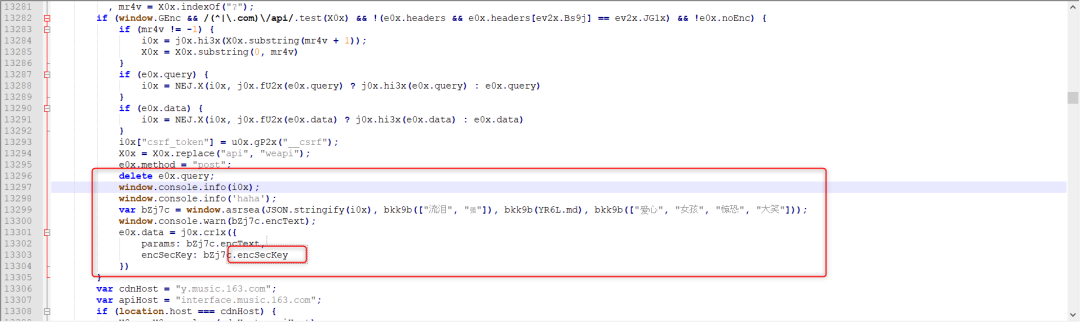
在fiddler中,设置,当访问数据请求core.js的时候,就使用本地的js来做响应。(相当于截胡)这样就可以顺利的看到请求的数据格式,见下图
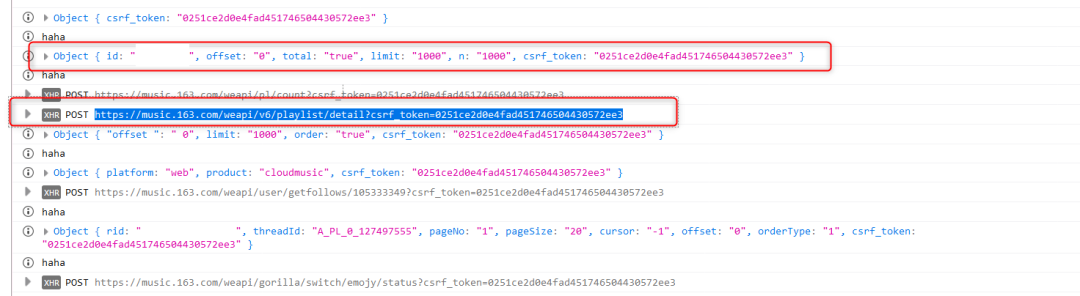
可以看到请求播放列表的时候提交的数据格式为'id': 'offset': "",'total': "",'limit': "",'n': "",'csrf_token': ""知道提交格式后,填进去个人信息,然后就可以欢快的使用request.post了
defcreate_form_data(self):text = json.dumps(self.text)params, encSecKey = get_params(text)form_data = {'params': params, 'encSecKey': encSecKey}return form_datadef get_song_list(self):data = self.create_form_data()res = requests.post(self.link, headers= self.header, data=data)with open(r'data/wyy.json', 'wb') as f:f.write(res.content)if(res.status_code == 200):print('歌曲列表网页下载成功')else:print('歌曲列表网页下载失败,响应码为{}'.format(res.status_code))
同样的方式可以得到登录界面的数据格式为'phone': '','password': '','rememberLogin': '','checkToken' : '','csrf_token' : '',其中password是hash之后的数据
爬取不同的界面,需要提交的数据格式不同,所以一定要学会使用fiddler截胡各个页面
接下来是完善request请求
完善请求时候的请求头,还有cookie信息,目前网易云对于csrf_token没有启用校验如果开启的话,还需要把cookie里面的信息放到请求头里使用
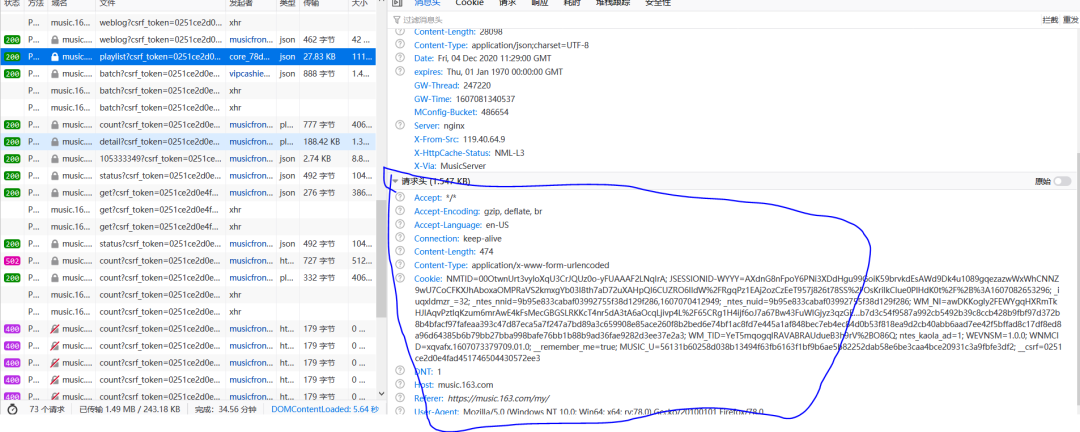
headers = {"Accept": "*/*","Accept-Encoding": "gzip,deflate,br","Accept-Language": "zh-CN,zh;q=0.9","Connection": "keep-alive","Content-Type": "application/x-www-form-urlencoded","Host": "music.163.com","Referer": "https://music.163.com/my/","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36",'Cookie' : 'NMTID=00OtwnUrt3vyloXqU3CrJQUz0o-yFUAAAF2LNqIrA; JSESSIONID-WYYY=AXdnG8nFpoY6PNi3XDdHgu99GoiK59brvkdEsAWd9Dk4u1089gqezazwWxWhCNNZ9wU7CoCFKXJhAboxaOMPRaVS2kmxgYb03I8th7aD72uXAHpQI6CUZRO6IldW%2FRgqPz1EAj2ozCzEeT957j826t78SS%2FOsKrilkCIue0PlHdK0t%2F%2B%3A1607082653296; _iuqxldmzr_=32; _ntes_nnid=9b95e833cabaf03992755f38d129f286,1607070412949; _ntes_nuid=9b95e833cabaf03992755f38d129f286; WM_NI=awDKKogly2FEWYgqHXRmTkHJIAqvPztlqKzum6mrAwE4kFsMecGBGSLRKKcT4nr5dA3tA6aOcqLjivp4L%2F65CRg1H4ijf6oJ7a67Bw43FuWIGjyz3qzGENdashEyPenNN2o%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6eea8c445edb388d1b770a68e8eb3c54f838f8eabaa6f96a6a5daf85fb391bd92c52af0fea7c3b92aa3a98cacca65a5b4b7d3c54f9587a992cb5492b39c8ccb428b9fbf97d372b8b4bfacf97fafeaa393c47d87eca5a7f247a7bd89a3c659908e85ace260f8b2bed6e74bf1ac8fd7e445a1af848bec7eb4ec84d0b53f818ea9d2cb40abb6aad7ee42f5bffad8c17df8ed8a96d64385b6b79bb27bba998bafe76bb1b88b9ad36fae9282d3ee37e2a3; WM_TID=YeT5mqogqlRAVABRAUdueB3h9rV%2BO86Q; ntes_kaola_ad=1; WEVNSM=1.0.0; WNMCID=xqvafx.1607073379709.01.0; __remember_me=true; MUSIC_U=56131b60258d038b13494f63fb6163f1bf9b6ae5b82252dab58e6be3caa4bce20931c3a9fbfe3df2; __csrf=0251ce2d0e4fad451746504430572ee3'}
请求头设置好之后,如果你的数据格式,加密算法都没有问题的话,使用post方法应该就可以收到200响应,同时带有你想要的数据
补充一下,get和post方法的区别,get就像是一个静态页面,东西已经加载好了在那里,你一调用get,就给你返回数据
post方法更像是动态页面,东西没准备好,你post的时候告诉服务器你需要什么东西,然后服务器验证一下你提交的格式对不对,对的话,再匆匆忙忙把你要的宝贝返回给你
处理返回的数据
歌名,演唱者信息可以在返回的数据里直接拿到
专辑图片的链接也在返回数据里,启用一个多进程将这些图片下载下来。进程数按照cpu的核数来设置。如果你不幸有一个12核的cpu的话,那你下载速度会非常快
def muti_process(self):# urls = urls[0:21] #拿前20个做实验pool = Pool(cpu_count())with open(r'data/pic_link.txt', 'rb') as f:urls = f.read()urls = urls.decode('utf-8').split()print('多线程启动')pool.map(self.downlaod_album, urls)pool.close()pool.join()def downlaod_album(self,url):try:with open(r'output/album/{}.png'.format(url[-15:-4]), 'wb') as f:f.write(requests.get(url).content)print('图片下载成功')# print(url[-10:-4])except ConnectionError:print('Error Occured ', url)finally:print('下载任务执行完毕')
调用wordcloud模块生成词云图
def draw_wordcloud(self,file,pic):self.pic = picmytext = self.cut_word(file)mask = imread(self.pic, pilmode="RGB")wc = WordCloud(# 设置字体,不指定就会出现乱码font_path=r"C:\Windows\Fonts\simhei.ttf",#避免词的重复collocations = False,# 设置背景色background_color='white',# 设置背景宽width=500,# 设置背景高height=350,# 最大字体max_font_size=50,# 最小字体min_font_size=10,font_step=4,mode='RGBA',# colormap='pink'mask=mask)# 产生词云wc.generate(mytext)wc.to_file(r"output/wordcloud.png") # 按照设置的像素宽高度保存绘制好的词云图,比下面程序显示更清晰print('词云图片保存成功')
调用cv2/pil模块处理专辑图片 ->这部分内容详见另一个github,https://github.com/ZhouFall/image_handle
最后的结果如下:可以看出,喜欢的歌手是陈奕迅和高梨康治(火影的作曲),说明一下,词云图只能反映出现的次数多少,可以用来看个趋势。喜欢的歌,cover和翻自出现的比较多,大概是因为喜欢听翻唱的吧(也有因为贫穷,听不到正版的原因)




参考网站:
https://www.jianshu.com/p/a45714d16294 网易云音乐爬虫(JS破解全过程)
https://www.cnblogs.com/bcaixl/p/13928629.html python3爬虫应用--爬取网易云音乐(两种办法)
https://blog.csdn.net/weixin_42555080/article/details/90105330 Python爬虫之网易云音乐数据爬取(十五)
https://www.zhihu.com/question/36081767 如何爬网易云音乐的评论数?
https://www.zhihu.com/question/36081767/answer/65820705 如何爬网易云音乐的评论数?
https://blog.csdn.net/qq_39138295/article/details/89226990 request保持会话,寻找set-cookie来获取数据

