 公众号CVer
公众号CVer




点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达
本文作者: 黄浴 | 编辑:Amusi
https://zhuanlan.zhihu.com/p/332164723
本文已由原作者授权,不得擅自二次转载
几家大学还有商汤一起合作的论文,arXiv2020年11月上载:“Temporal-Channel Transformer for 3D Lidar-Based Video Object Detection in Autonomous Driving“。

定义为Temporal-Channel Transformer,做激光雷达目标检测的时空域和通道域建模。比较特殊,这里编码器信息不同于解码器,编码器是多帧时域-通道域编码,解码器是以voxel-wise方式解码当前帧空域信息。Transformer的核心单元是Multihead scaled dot-product attention module。这里Transformer的时域-通道编码器对不同通道和帧的特征相关进行编码,而空域解码器对当前帧的每个位置信息解码。在transformer的gate机制,当前帧特征被重新标定,通过重复修正目标帧表示和上采样过程滤除目标不相干信息。
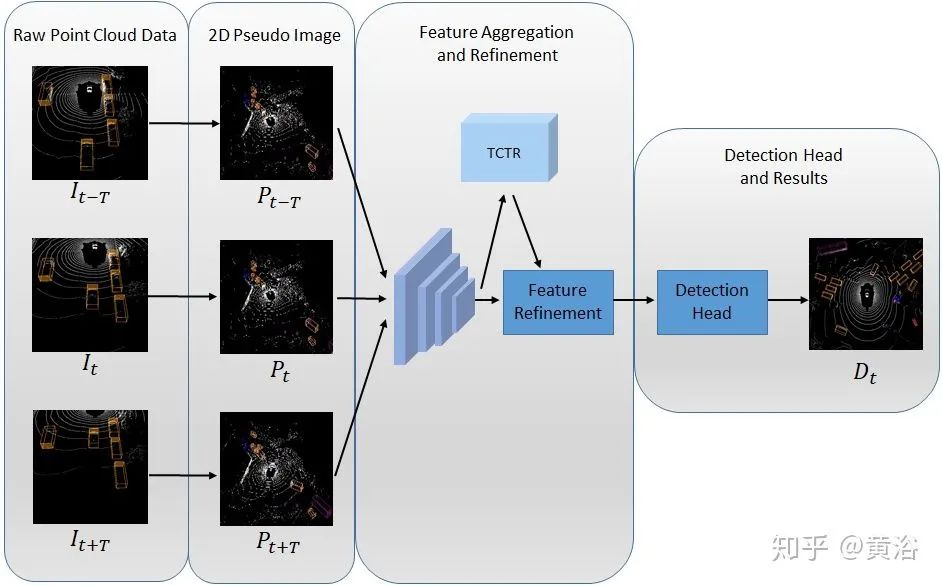
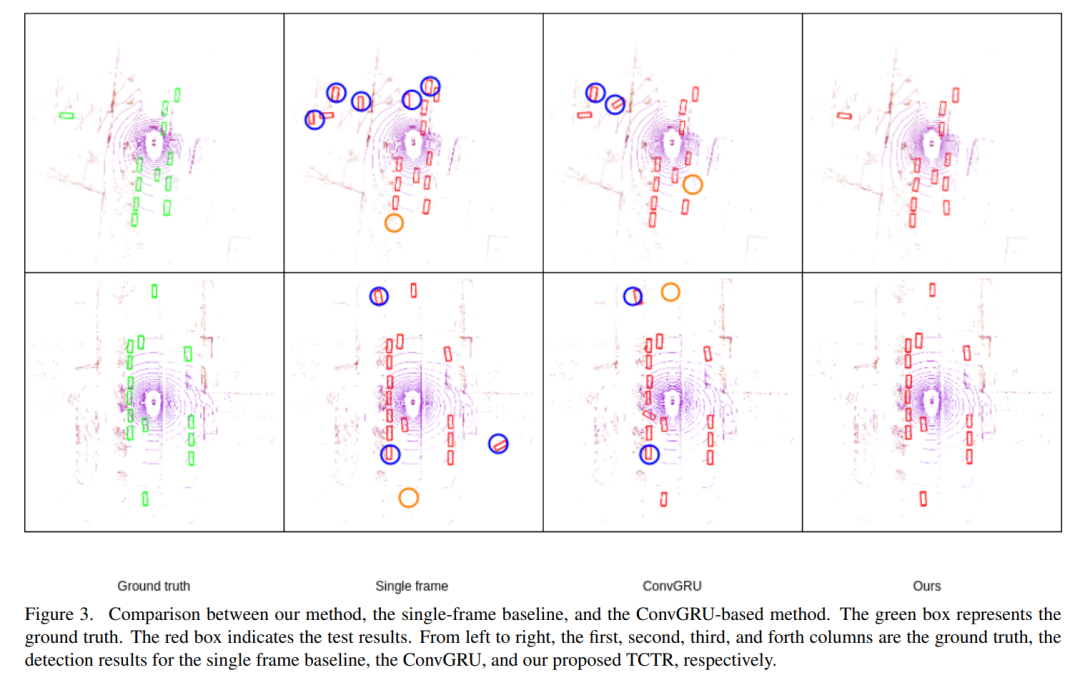
如图所示:连续多帧点云的原始数据I被转换为2D伪图像P。特征X提取后,TCTR模块生成时间-通道的信息表示Z,然后对detection-head进行特征优化。
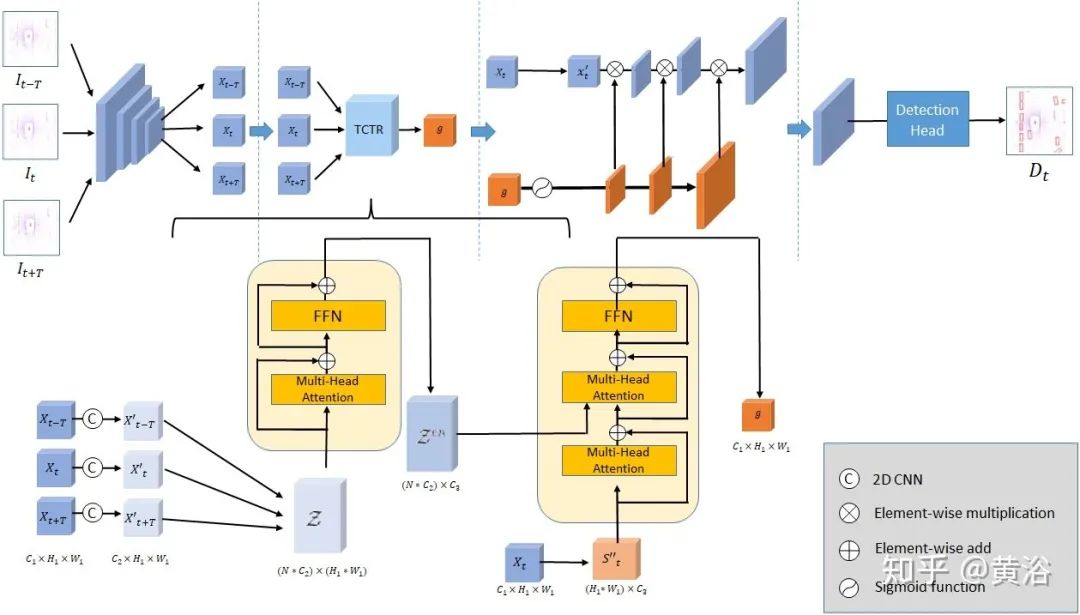
如图是网络的结构图:transformation设为query,并将激光雷达的投影设为multi-head attention模块的key和value。通过attention机制,输入序列的所有通道都与每个点云数据的每个voxel匹配,并根据相关性提供给voxel的新表示方式。考虑到空间相关性、时间相关性和通道相关性,利用帧间和帧内信息来增强空域解码器的输出。
这里multi-head的attention定义为:
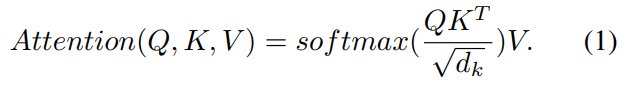
而multi-head的输出定义为:
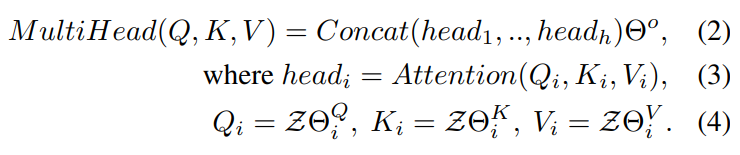
在解码器的self attention机制下,编码器中公式(4)被重实现为
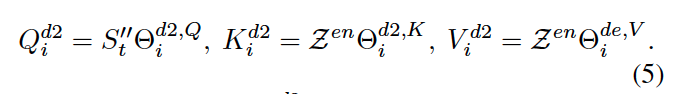
最后,基于gate机制的特征细化F定义为

上采样恢复特征到原分辨率,同时还有transformer的输出g,一个Xt的致密表示。
采用的detection head类似PointPillars模型,object classification的focal loss函数定义为:
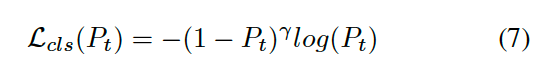
localization loss函数定义:
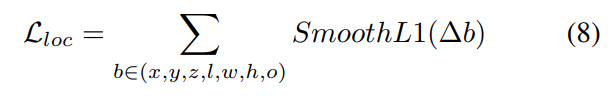
总loss函数:
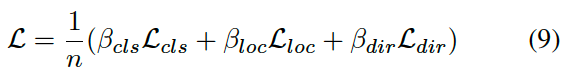
其中有第二项,object orientation direction的回归loss函数。
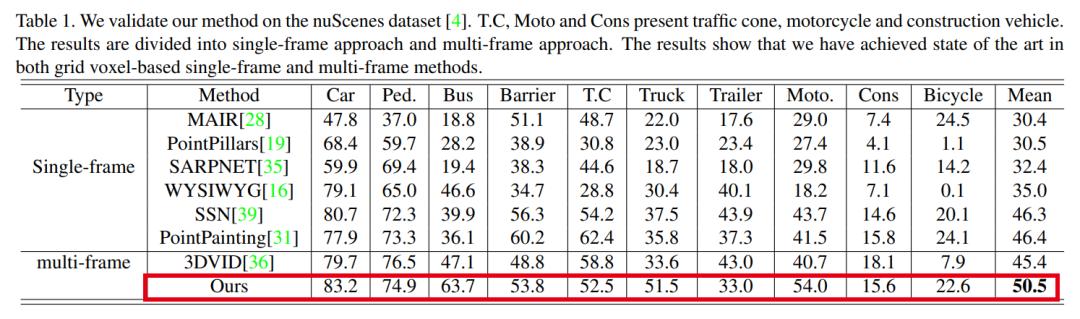
实验结果:
上述论文PDF打包下载
后台回复:1211,即可下载上述论文PDF,赶紧学起来!
目标检测综述下载
后台回复:目标检测二十年,即可下载39页的目标检测最全综述,共计411篇参考文献。
下载2
后台回复:CVPR2020,即可下载代码开源的论文合集
后台回复:ECCV2020,即可下载代码开源的论文合集
后台回复:YOLO,即可下载YOLOv4论文和代码
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4000人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!![]()

