 数据森麟
数据森麟





作者:zhenguo
来源:Python与算法社区
今天是 Pandas数据分析小技巧系列 第三集,涉及如何获取数据最多的3个分类,以及如何使用count统计词条出现次数。
小技巧 10:如何快速拿到数据最多的 3 个分类?
读入数据:
df = pd.read_csv("IMDB-Movie-Data.csv")
df
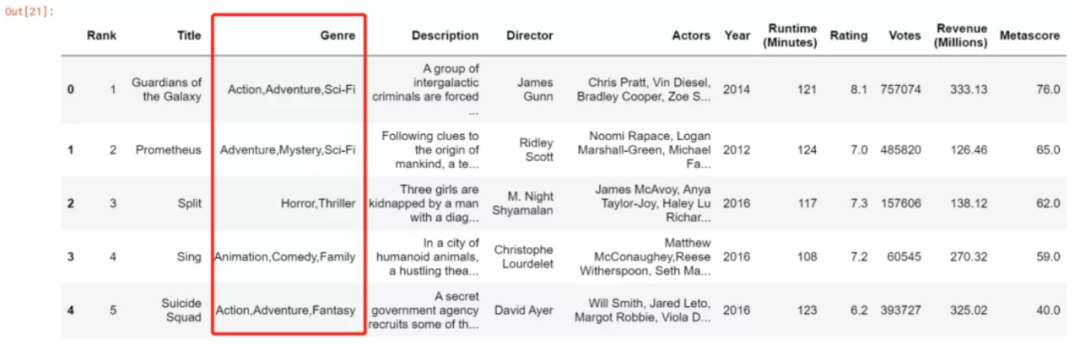
1000 行数据,genre 取值的频次统计如下:
vc = df["genre"].value_counts()
vc
打印结果:
Action,Adventure,Sci-Fi 50
Drama 48
Comedy,Drama,Romance 35
Comedy 32
Drama,Romance 31
..
Adventure,Comedy,Fantasy 1
Biography,History,Thriller 1
Action,Horror 1
Mystery,Thriller,Western 1
Animation,Fantasy 1
Name: genre, Length: 207, dtype: int64
筛选出 top3 的 index:
top_genre = vc[0:3].index
print(top_genre)
打印结果:
Index(['Action,Adventure,Sci-Fi', 'Drama', \
'Comedy,Drama,Romance'], dtype='object')
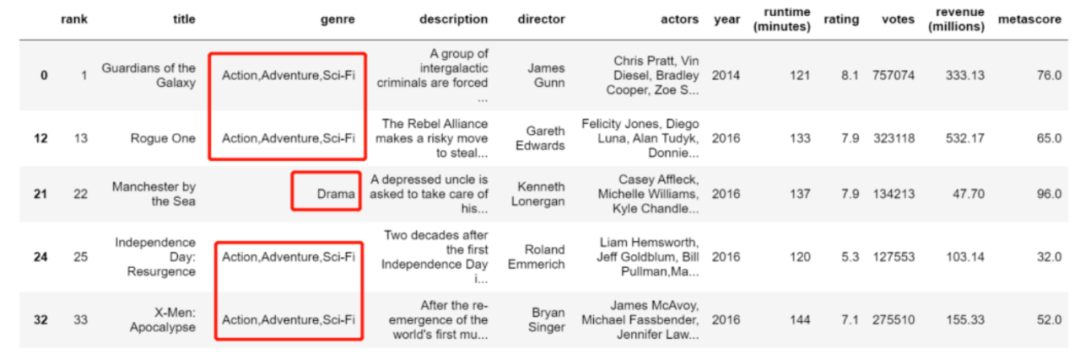
使用得到的 top3 的 index ,结合 isin,选择出相应的 df
df_top = df[df["genre"].isin(top_genre)]
df_top
结果:
小技巧11:如何使用 count 统计词条出现次数?
读入 IMDB-Movie-Data 数据集,1000行数据:
df = pd.read_csv("../input/imdb-data/IMDB-Movie-Data.csv")
df['Title']
打印 Title 列:
0 Guardians of the Galaxy
1 Prometheus
2 Split
3 Sing
4 Suicide Squad
...
995 Secret in Their Eyes
996 Hostel: Part II
997 Step Up 2: The Streets
998 Search Party
999 Nine Lives
Name: Title, Length: 1000, dtype: object
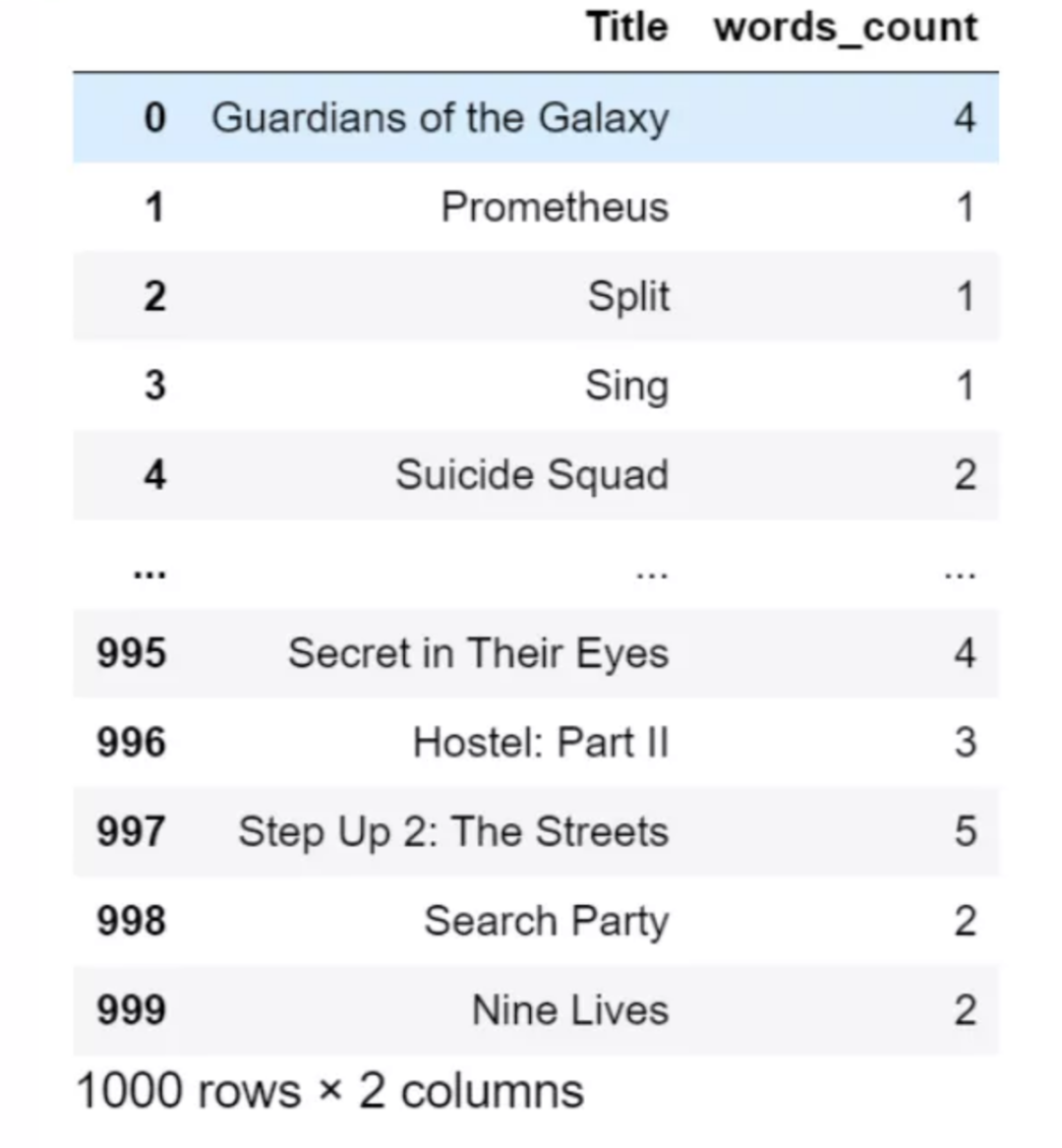
标题是由几个单词组成,用空格分隔。
df["words_count"] = df["Title"].str.count(" ") + 1
df[["Title","words_count"]]
◆ ◆ ◆ ◆ ◆
麟哥新书已经在当当上架了,我写了本书:《拿下Offer-数据分析师求职面试指南》,目前当当正在举行双12活动,大家可以用相原价5折的价格购买,还是非常划算的:
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:

● 你相信逛B站也能学编程吗

