
BERT是如何理解语言的?谷歌发布交互式平台LIT,解决模型可视化难题
共 1921字,需浏览 4分钟
· 2020-12-06

新智元报道
新智元报道
编辑:QJP
【新智元导读】随着 NLP 模型变得越来越强大,并被部署在真实的场景中,理解模型的预测结果变得越来越重要。近期,谷歌发布了一项新的语言可解释性工具(LIT),这是一种解释和分析NLP模型的新方法,让模型结果不再那么【黑盒】。
对于任何新的模型,研究人员可能想知道在哪些情况下模型表现不佳,为什么模型做出特定的预测,或者模型在不同的输入下是否表现一致,比如文本风格或代词性别的变化等。
尽管最近在模型理解和评估方面的工作大量涌现,但是并没有可视化或可解释性的工具可供分析。算法工程师必须试验许多技术,如查看文档的解释,聚类度量和反事实的输入变化等,以建立一个更好的可解释性模型,而这些技术往往需要自己的软件包或定制工具。

对于这些困扰了深度学习模型很多年的问题,谷歌在刚刚结束的2020年EMNLP上发布的语言可解释性工具(LIT)给出了答案。
谷歌之前发布的 What-If 工具就是为了应对这一挑战而构建的,它支持对分类和回归模型的黑盒探测,从而使研究人员能够更容易地调试性能,并通过交互和可视化分析机器学习模型的公平性,但是仍然需要一个工具包来解决 NLP 模型特有的挑战。
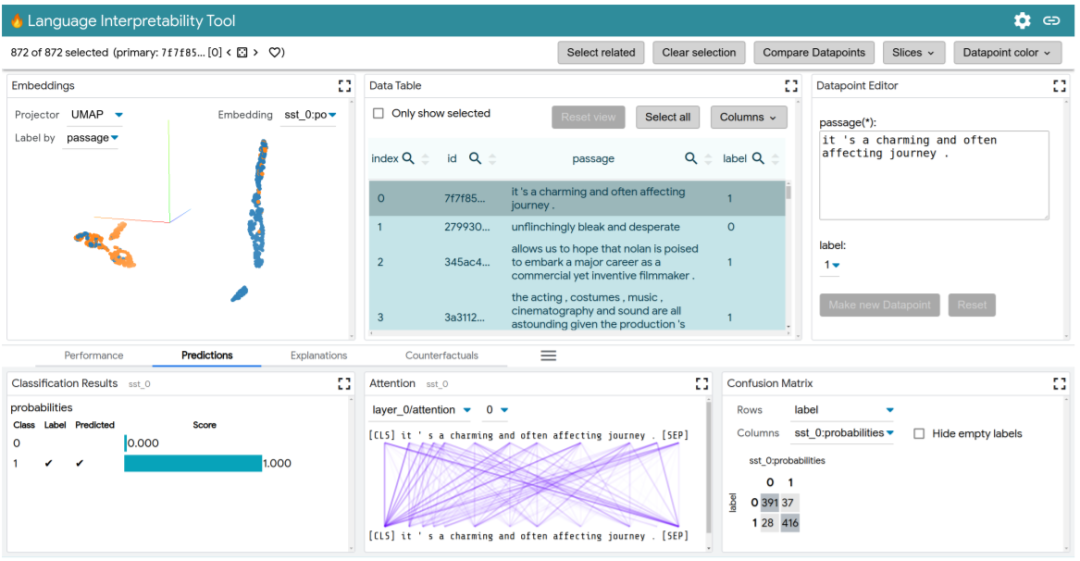
LIT 就是一个用于理解 NLP 模型的交互式平台,它基于 What-If 工具的缺点进行改进,功能大大扩展,涵盖了大范围的 NLP 任务,包括序列生成、跨度标记、分类和回归,以及可定制和可扩展的可视化和模型分析。
LIT 还支持局部解释,包括显著图、注意力机制、模型预测的丰富可视化,以及包括度量、嵌入空间和灵活切片在内的聚合分析。
它允许用户轻松地在可视化之间切换,以测试局部假设并在数据集上进行验证。LIT 提供了对反事实生成的支持,其中新的数据点可以动态地添加,并且将它们对模型的影响可视化,还可以并排同时可视化两个模型或两个单独的数据点。
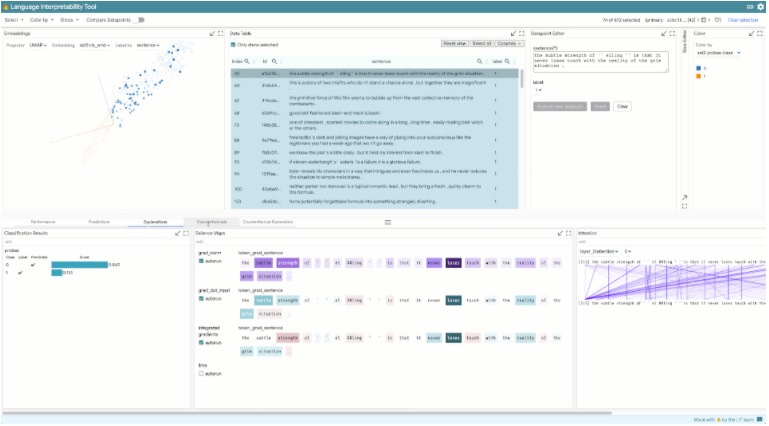
为了更好地满足使用 LIT 的不同兴趣和优先级的广大用户,研究人员从一开始就构建了这个工具,使之可以很容易地进行定制和扩展。
在特定的 NLP 模型和数据集上使用 LIT 只需要编写一小段 Python 代码即可。自定义组件,例如任务特定的度量计算或反事实生成器,可以用 Python 编写,并通过提供的API添加到 LIT 实例中。
此外,前端本身也可以定制,使用直接集成到用户界面的新模块。
为了说明 LIT 的一些功能,可以使用预先训练好的模型创建一些演示。这里举其中的两个例子:
首先是情感分析,通过一个二分类器,可以预测一个句子是正面还是负面情绪。通过LIT 提供的各种可视化,可以帮助确定模型在什么情况下会失败,以及这些失败是否可以泛化,然后可以用于告知如何最好地改进模型。

Masked 语言建模是一个“完型填空”任务,该模型预测可以完成一个句子中的不同单词。例如,给出提示,“ I took my _ _ for a walk” ,该模型可能预测“ dog”的得分很高。在 LIT 中,人们可以通过输入句子或者从预先加载的语料库中选择,然后点击特定的标记,看看像 BERT 这样的模型对语言或世界的理解是什么。
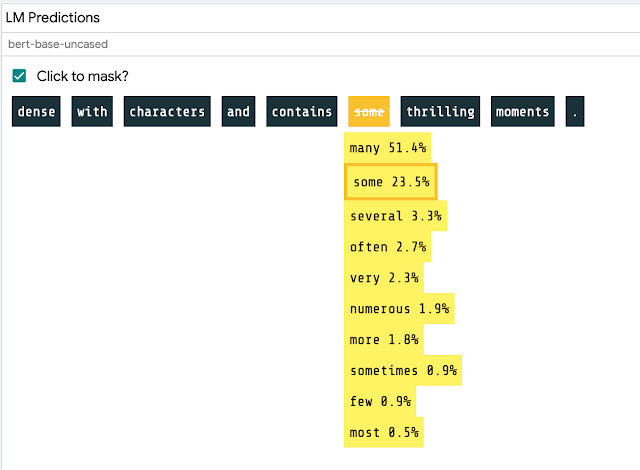
尽管 LIT 是一个新的工具,但我们已经看到它对于模型理解的价值。它的可视化效果可以用来发现模型行为中的模式,比如嵌入空间中的离散集群,或者对预测结果具有重要性的单词。
在 LIT 中的探索可以测试模型中的潜在偏差,正如我们在 LIT 的案例研究中证明的那样,在一个共同参照模型中探索性别偏差。这种类型的分析可以为改进模型性能的下一步提供信息,例如应用 MinDiff 来减轻系统偏差。它也可以作为一种简单、快速的方式为任何 NLP 模型创建交互式演示。

通过提供的演示或者自己的模型和数据集可以建立一个 LIT 服务器来检查这个工具。目前,对 LIT 的研究才刚刚开始,并且计划了一些新的功能和改进,包括从最前沿的机器学习和自然语言处理研究中增加新的解释技术,同时代码是开源的,感兴趣的小伙伴可以做出自己的改进和贡献。
参考链接:
https://ai.googleblog.com/2020/11/the-language-interpretability-tool-lit.html

