
2020年大厂面试题-数据仓库篇

以下面试题均为身边朋友面试大厂所提供;
且后期将不定期进行更新并会附上最终答案;
其中涉及到的题目没有标准答案
该答案均为笔者手动整理,如有错误
请及时指出改正~
最后强烈建议进行收藏阅读!!!

手写"连续活跃登陆"等类似场景的sql
# 该题目有不同的解法,可以使用row_number窗口函数或者使用lag函数# 第一种解决方案,使用lag(向前)或者lead(向后)select*from(selectuser_id,date_id,lead(date_id) over(partition by user_id order by date_id) as last_date_idfrom(selectuser_id,date_idfrom wedw_dw.tmp_logwhere date_id>='2020-08-10'and user_id is not nulland length(user_id)>0group by user_id,date_idorder by user_id,date_id)t)t1where datediff(last_date_id,date_id)=1
-- 第二种解决方案,使用row_numberselectuser_id,min(date_id),max(date_id),count(1)from(selectt1.user_id,t1.date_id,date_sub(t1.date_id,rn) as disfrom(selectuser_id,date_id,row_number() over(partition by user_id order by date_id asc) rnfrom(selectuser_id,date_idfrom wedw_dw.tmp_logwhere date_id>='2020-08-10'and user_id is not nulland length(user_id)>0group by user_id,date_idorder by user_id,date_id)t)t1)t2group by user_id,hishaving count(1)>2
left semi join和left join区别
-
left semi join 左半连接
in(keySet),相当于在右表中查询左表的key, left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过;当右表不存在的时候,左表数据不会显示; 相当于SQL的in语句.比如测试的语句相当于
select * from table1 where table1.student_no in (table2.student_no)注意,结果中是没有B表的字段的.LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现;Hive 当前没有实现 IN/EXISTS 子查询,所以你可以用 LEFT SEMI JOIN 重写你的子查询语句。LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行
-
left join
当右表不存在的时候,则会显示NULL
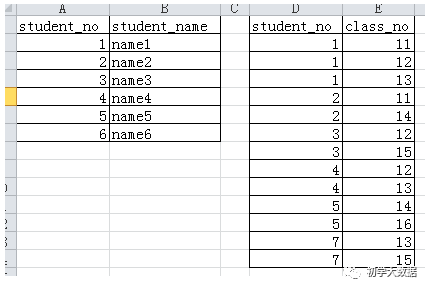
select * from table1 left semi join table2 on(table1.student_no=table2.student_no);结果:1 name12 name23 name34 name45 name5select * from table1 left outer join table2 on(table1.student_no=table2.student_no);结果:1 name1 1 111 name1 1 121 name1 1 132 name2 2 112 name2 2 143 name3 3 153 name3 3 124 name4 4 134 name4 4 125 name5 5 145 name5 5 166 name6 NULL NULL
维度建模和范式建模的区别
通常数据建模有以下几个流程:
-
概念建模:即通常先将业务划分多个主题
-
逻辑建模:即定义各种实体、属性和关系
-
物理建模:设计数据对象的物理实现,比如表字段类型、命名等。
那么范式建模,即3NF模型具有以下特点:
-
原子性,即数据不可分割
-
基于第一个条件,实体属性完全依赖于主键,不能存在仅依赖主关键字一部分属性。即不能存在部分依赖
-
基于第二个条件,任何非主属性不依赖于其他非主属性。即消除传递依赖.
基于以上三个特点,3NF的最终目的就是为了降低数据冗余,保障数据一致性;同时也有了数据关联逻辑复杂的缺点。
而维度建模是面向分析场景的,主要关注点在于快速、灵活,能够提供大规模的数据响应。
常用的维度模型类型主要有:
-
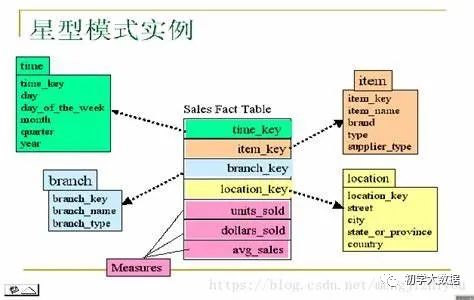
星型模型:即由一个事实表和一组维度表组成,每个维表都有一个维度作为主键。事实表居中,多个维表呈辐射状分布在四周,并与事实表关联,形成一个星型结构
-
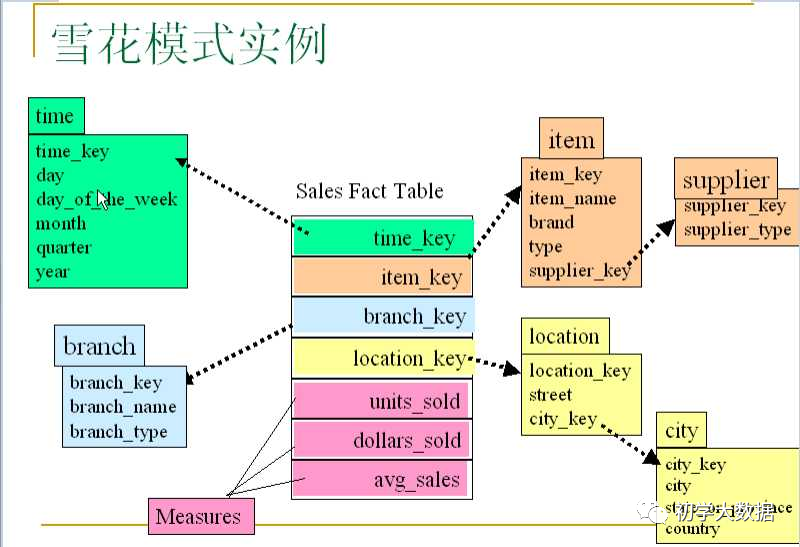
雪花模型:在星型模型的基础上,基于范式理论进一步层次化,将某些维表扩展成事实表,最终形成雪花状结构
-
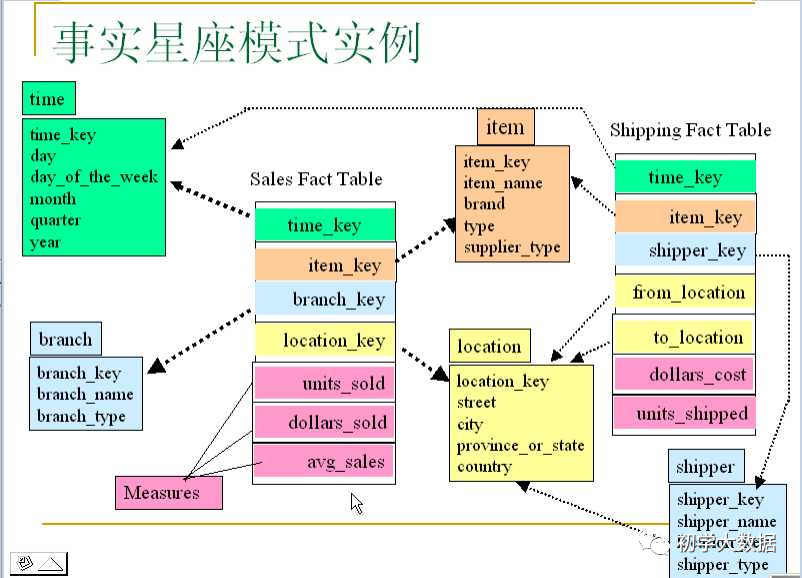
星系模型:基于多个事实表,共享一些维度表
数据漂移如何解决
什么是数据漂移?
通常是指ods表的同一个业务日期数据中包含了前一天或后一天凌晨附近的数据或者丢失当天变更的数据,这种现象就叫做漂移,且在大部分公司中都会遇到的场景。
如何解决数据漂移问题?
通常有两种解决方案:
-
多获取后一天的数据,保障数据只多不少
-
通过多个时间戳字段来限制时间获取相对准确的数据
第一种方案比较暴力,这里不做过多解释,主要来讲解一下第二种解决方案。(首先这种解决方案在大数据之路这本书有体现)
以下内容为该书的描述:
通常,时间戳字段分为四类:
数据库表中用来标识数据记录更新时间的时间戳字段(假设这类字段叫 modified time )
数据库日志中用来标识数据记录更新时间的时间戳字段·(假设这类宇段叫 log_time)
数据库表中用来记录具体业务过程发生时间的时间戳字段 (假设这类字段叫 proc_time)
标识数据记录被抽取到时间的时间戳字段(假设这类字段extract time)
理论上这几个时间应该是一致的,但往往会出现差异,造成的原因可能为:
数据抽取需要一定的时间,extract_time往往晚于前三个时间
业务系统手动改动数据并未更新modfied_time
网络或系统压力问题,log_time或modified_time晚于proc_time
通常都是根据以上的某几个字段来切分ODS表,这就产生了数据漂移。具体场景如下:
根据extract_time进行同步
根据modified_time进行限制同步, 在实际生产中这种情况最常见,但是往往会发生不更新 modified time 而导致的数据遗漏,或者凌晨时间产生的数据记录漂移到后天 。由于网络或者系统压力问题, log_time 会晚proc_time ,从而导致凌晨时间产生的数据记录漂移到后一天。
根据proc_time来限制,会违背ods和业务库保持一致的原则,因为仅仅根据proc_time来限制,会遗漏很多其他过程的变化
那么该书籍中提到的第二种解决方案:
-
首先通过log_time多同步前一天最后15分钟和后一天凌晨开始15分钟的数据,然后用modified_time过滤非当天的数据,这样确保数据不会因为系统问题被遗漏
-
然后根据log_time获取后一天15分钟的数据,基于这部分数据,按照主键根据log_time做升序排序,那么第一条数据也就是最接近当天记录变化的
-
最后将前两步的数据做全外连接,通过限制业务时间proc_time来获取想要的数据
拉链表如何设计,拉链表出现数据回滚的需求怎么解决
拉链表使用的场景:
数据量大,且表中部分字段会更新,比如用户地址、产品描述信息、订单状态等等
需要查看某一个时间段的历史快照信息
变化比例和频率不是很大
--拉链表实现--原始数据CREATE TABLE wedw_tmp.tmp_orders (orderid INT,createtime STRING,modifiedtime STRING,status STRING) stored AS textfile;--拉链表CREATE TABLE wedw_tmp.tmp_orders_dz(orderid int,createtime STRING,modifiedtime STRING,status STRING,link_start_date string,link_end_date string) stored AS textfile;--更新表CREATE TABLE wedw_tmp.tmp_orders_update(orderid INT,createtime STRING,modifiedtime STRING,status STRING) stored AS textfile;--插入原始数据insert overwrite table wedw_tmp.tmp_ordersselect 1,"2015-08-18","2015-08-18","创建"union allselect 2,"2015-08-18","2015-08-18","创建"union allselect 3,"2015-08-19","2015-08-21","支付"union allselect 4,"2015-08-19","2015-08-21","完成"union allselect 5,"2015-08-19","2015-08-20","支付"union allselect 6,"2015-08-20","2015-08-20","创建"union allselect 7,"2015-08-20","2015-08-21","支付"--拉链表初始化insert into wedw_tmp.tmp_orders_dzselect *,createtime,'9999-12-31'from wedw_tmp.tmp_orders--增量数据insert into wedw_tmp.tmp_orders_updateselect 3,"2015-08-19","2015-08-21","支付"union allselect 4,"2015-08-19","2015-08-21","完成"union allselect 7,"2015-08-20","2015-08-21","支付"union allselect 8,"2015-08-21","2015-08-21","创建"--更新拉链表insert overwrite table wedw_tmp.tmp_orders_dzselectt1.orderid,t1.createtime,t1.modifiedtime,t1.status,t1.link_start_date,case when t1.link_end_date='9999-12-31' and t2.orderid is not null then '2015-08-20'else t1.link_end_dateend as link_end_datefrom wedw_tmp.tmp_orders_dz t1left join wedw_tmp.tmp_orders_update t2on t1.orderid = t2.orderidunion allselectorderid,createtime,modifiedtime,status,'2015-08-21' as link_start_date,'9999-12-31' as link_end_datefrom wedw_tmp.tmp_orders_update--拉链表回滚,比如在插入2015-08-22的数据后,-- 回滚2015-08-21的数据,使拉链表与2015-08-20的一致-- 具体操作过程如下selectorderid,createtime,modifiedtime,status,link_start_date,link_end_datefrom wedw_tmp.tmp_orders_dzwhere link_end_date<'2015-08-20'union allselectorderid,createtime,modifiedtime,status,link_start_date,'9999-12-31'from wedw_tmp.tmp_orders_dzwhere link_end_date='2015-08-20'union allselectorderid,createtime,modifiedtime,status,link_start_date,'9999-12-31'from wedw_tmp.tmp_orders_dzwhere link_start_date<'2020-08-21' and link_end_date>='2015-08-21'
sql里面on和where有区别吗
数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表
以 LEFT JOIN 为例:在使用 LEFT JOIN 时,ON 和 WHERE 过滤条件的区别如下:
on 条件是在生成临时表时使用的条件,它不管 on 中的条件是否为真,都会返回左边表中的记录
where 条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有 left join 的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉。
公共层和数据集市层的区别和特点
公共维度模型层(CDM):
又细分为dwd层和dws层,主要存放明细事实数据、维表数据以及公共指标汇总数据,其中明细事实数据、维表数据一般是根据ods层数据加工生成的,公共指标汇总数据一般是基于维表和明细事实数据加工生成的。
采用维度模型方法作为理论基础,更多采用一些维度退化的手段,将维度退化到事实表中,减少事实表和维度表之间的关联。同时在汇总层,加强指标的维度退化,采用更多的宽表化手段构建公共指标数据层,提升公共指标的复用性,减少重复加工。
其主要功能:
-
组合相关和相似数据:采用明细宽表,复用关联计算,减少数据 扫描。
公共指标统一加工:基于 OneData 体系构建命名规范、口径一致 和算法统一的统计指标,为上层数据产品、应用和服务提供公共 指标 建立逻辑汇总宽表
建立一致性维度:建立一致的数据分析维表,降低数据计算口径、 算法不统一的风险。应用数据层( ADS):存放数据产品个性化的统计指标数据,根据 CDM 层与 ODS 层加工生成。
数据集市(Data Mart):
就是满足特定部门或者用户的需求,按照多维方式存储。面向决策分析的数据立方体
从原理上说一下mpp和mr的区别
MPP 为并行数据库 :
它的思路简单粗暴,把数据分块,交给不同节点储存, 查询的时候各块的节点有独立的计算资源分别处理,然后汇总到一个leader node(又叫control node),具体的优化和传统的关系型数据库很相似,涉及到了索引,统计信息等概念. MPP有shared everything /Disk / Nothing之别.
MapReduce其实就是二分查找的一个逆过程,不过因为计算节点有限,所以map和reduce前都预先有一个分区的步骤.二分查找要求数据是排序好的,所以Map Reduce之间会有一个shuffle的过程对Map的结果排序. Reduce的输入是排好序的 .
区别:
底层数据库:MPP跑的是SQL,而Hadoop底层处理是MapReduce程序
扩展程度:MPP虽然是宣称可以横向扩展Scale OUT,但是这种扩展一般是扩展到100左右,而Hadoop一般可以扩展1000+ ;因为MPP始终还是DB,一定要考虑到C(Consistency),其次考虑A(Availability),最后才在可能的情况下尽量做好P(Partition-tolerance)。而Hadoop就是为了并行处理和存储设计的,所以数据都是以文件存储,所以有限考虑的是P,然后是A,最后再考虑C.所以后者的可靠型当然好于前者
本质mpp还是数据库,需要优先考虑C(数据一致性),而mr首先考虑的是P(分区容错性);关于CAP理论可见十分钟搞定分布式一致性算法
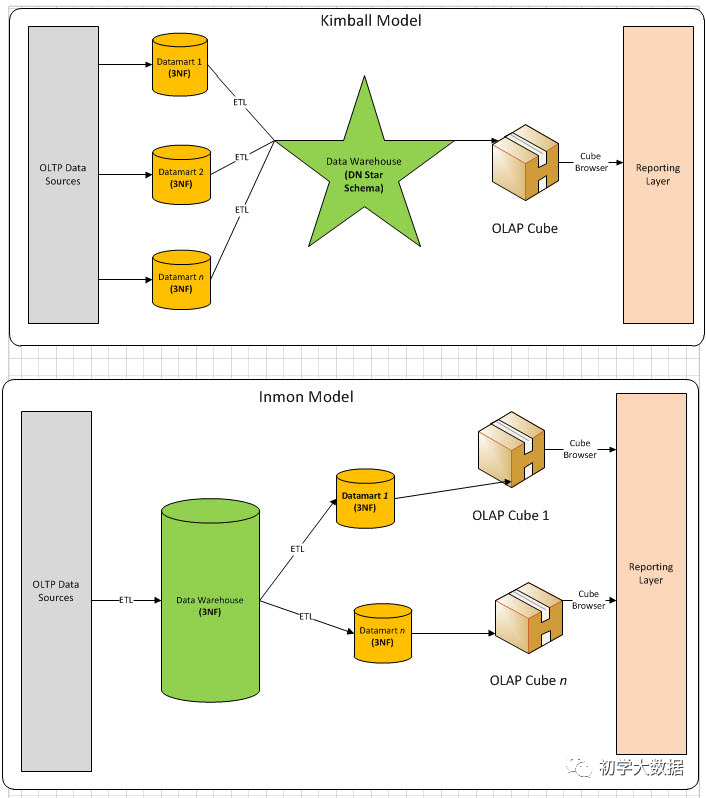
Kimball和Inmon的相同和不同
Inmon模型:
流程:自顶向下,即从分散异构的数据源-->数据仓库---->数据集市。是一种瀑布流开发方法。模型偏向于3NF
数据源往往是异构的,比如爬虫;数据源是根据最终目标自行定制的。
这里主要的处理工作集中在对异构数据进行清洗,否则无法从stage层直接输出到dm层,必须先通过etl将数据进行清洗后放入dw层。
Inmon模式下,不强调事实表和维度表的概念,因为数据源变化可能性较大,更加强调的是数据的清洗工作,从中抽取实体-关系
Inmon是以数据源头为导向,具体流程如下:
首先探索获取尽量符合预期的数据,尝试将数据按照预期划分不同的表需求
明确数据清洗规则后将各个任务通过etl由stage层转化到dm层,这里dm层通常涉及到较多的UDF开发,将数据抽象为实体-关系模型
完成dm数据治理后,可以将数据输出到数据集市中做基本数据组合,最后输出到BI系统辅助具体业务
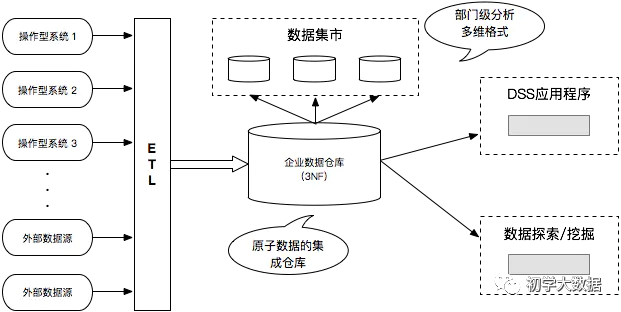
一般这种模型构建属于细水长流型的,而且技能/数据要求比较高,有可能有一天公司倒闭了,数仓还没有建设好
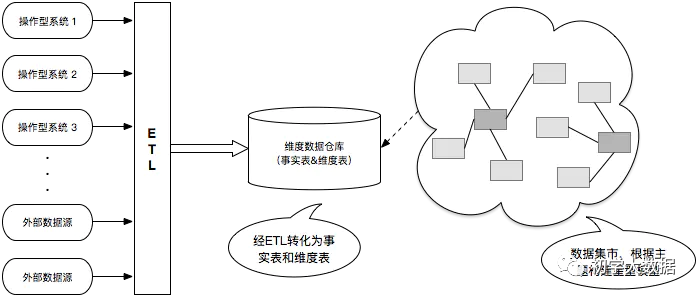
Kimball模型是以需求为导向
流程:自下向上, 即从数据集市-> 数据仓库 -> 分散异构的数据源 ,相当于是以最终任务为导向的;模型使用星型、雪花
-
首先得到数据后需要先做数据的探索,尝试将数据按照目标拆分出不同的表需求
明确数据依赖后将各个任务再通过etl由stage层转化到DM层。DM层由若干事实表和维度表组成
完成DM层的事实表和维度表拆分后,数据集市一侧可以直接向BI环节输出数据
Kimball往往意味着快速交付,敏捷交付,不会对数仓架构做过多复杂的设计
特征对比:
MOLAP ROLAP HOLAP的区别和联系
MOLAP:多维联机分析处理,预计算
ROLAP:关系型联机分析处理, 依赖于操作存储在关系型数据库中的数据.本质上,每个slicing或dicing功能和SQL语句中"WHERE"子句的功能是一样的。
HOLAP:混合型联机分析处理(指的是MOLAP和ROLAP的结合)
埋点的码表如何设计
数据倾斜
group by为什么要排序
缓慢变化维的处理方式
hive常见的优化思路
数据质量/元数据管理/指标体系建设/数据驱动
如何保证数据质量
如何保证指标一致性
--end--
扫描下方二维码
添加好友,备注【交流】 可私聊交流,也可进资源丰富学习群