
Python分析《演员请就位2》豆瓣评论,我找到了它频频上热搜的原因
共 4391字,需浏览 9分钟
· 2020-11-25
回复“书籍”即可获赠Python从入门到进阶共10本电子书
前言
最近有部综艺——《演员请就位》第二季,三天两头一个热搜,真是无比热闹,因为那句“郭敬明导演你看我的演技能值一个S卡”的调侃,我也入了这档综艺的坑,你别说这综艺槽点还挺多,特别是五位导师,他们的戏比演员的精彩多了。 《演员请就位》目前为止已经播出了两季,第一季在豆瓣为6.8分,共有4万余人评分,第二季目前评分低于第一季,评分仅6.2分。
《演员请就位》目前为止已经播出了两季,第一季在豆瓣为6.8分,共有4万余人评分,第二季目前评分低于第一季,评分仅6.2分。
 本文通过爬取《演员请就位》第二季豆瓣短评(好评、中评和差评皆有抽样),进行可视化分析和情感分析,完整代码后台回复「演员请就位」即可免费获取。
本文通过爬取《演员请就位》第二季豆瓣短评(好评、中评和差评皆有抽样),进行可视化分析和情感分析,完整代码后台回复「演员请就位」即可免费获取。
可视化分析
导演比演员讨论的更多
通过对所有评论进行词云图绘制,我们发现导演提及次数超过演员,这不是演员养成类综艺吗?导演的料居然比演员还多。另外,我们还可以看出大家对这部综艺褒贬不一,「演技」、「喜欢」等好评词占据一定比例,同时给出「恶心」、「垃圾」等差评词的观众也不乏少数。
差评占比超半数
从评论分类来看,差评占比55%,中评占比21%,好评占比24%。更多的观众对《演员2》不敏感,主要源自看过《演员1》所带来的高期待与现实的落差较大,另外,郭敬明对何昶希发S卡的行为也招致了不少骂名。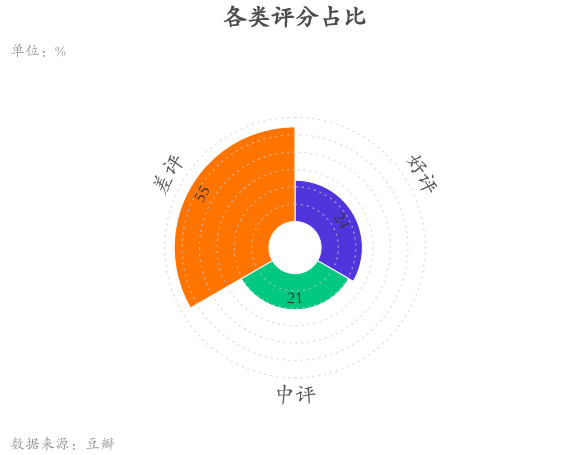
大多数观众在半夜发评论
从评论时间分布来看,晚上10点至12点评论人数占比高达27.89%。
好评难以获赞
5星好评仅获得观众828个赞,反而1星差评获得了3776个点赞。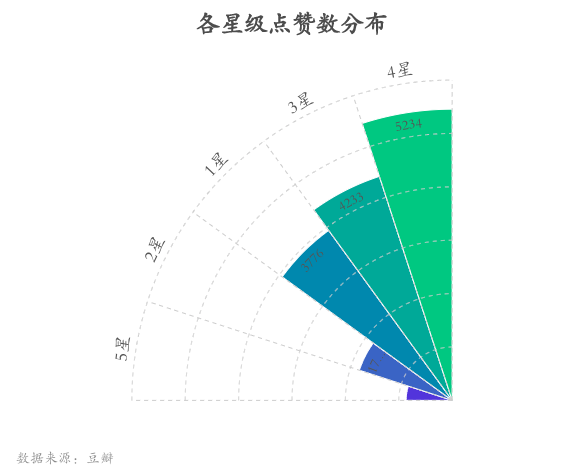
郭敬明被提及次数最多
从观众词云中提取《演员请就位2》的主要人物,我们发现郭敬明被观众提及次数最多,达319次。另外,李诚儒由于其犀利的点评广受观众的热议,金句「味同嚼蜡,味如鸡肋,如此乏味」一度刷爆网络,提及次数甚至高于赵薇导演。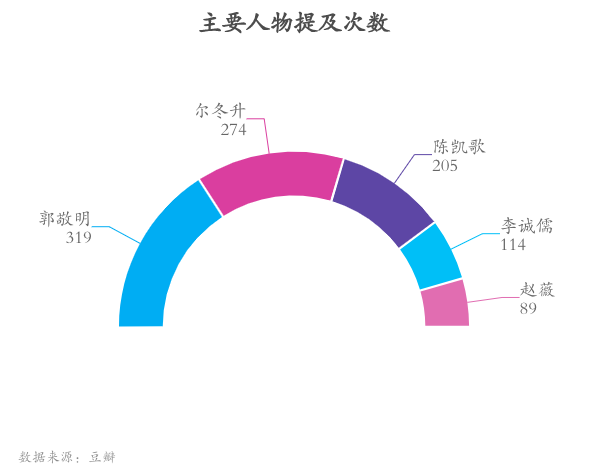
情感分值0.4左右,且凌晨达到峰值
不久之前,百度正式发布情感预训练模型 SKEP (Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis)。通过利用情感知识增强预训练模型,SKEP 在 14 项中英情感分析典型任务上全面超越 SOTA。本次运用该模型对所有《演员请就位2》评论进行打分,我们发现一天内观众情感分值在0.4分上下波动,仅在凌晨5点左右达到一个较高的积极倾向。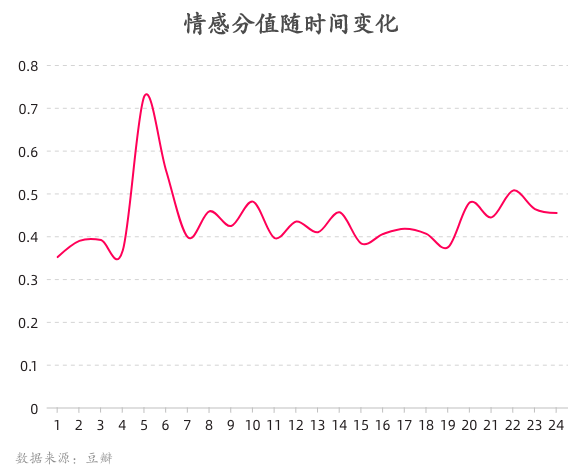
技术实现
数据获取
以下给出核心代码:
def get_page_info(start_num,type):
url="https://movie.douban.com/subject/"+ movie_id +"/comments?percent_type="+type+"&start="+str(start_num)+"&limit=20&status=P&sort=new_score&comments_only=1&ck=myI8"
print(url)
header = {
"Accept":"application/json, text/plain, */*",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"Host":"movie.douban.com",
"User-Agent":'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
"Cookie":'ll="118217"; bid=RljS46FQccw; __yadk_uid=GlresR4DtEXMJYz7UEJiEiW1jZGdHxV1; __gads=ID=4369b0a5596d1a14:T=1582470136:S=ALNI_MYu_5GhYfBddurehU-ZyUkLIHkXmw; viewed="34838905"; _vwo_uuid_v2=D57B8780A6D0B07688BCF1679FC9CC7CE|f58c953da6640ed67cf0c62ed4f1a076; douban-fav-remind=1; __utmv=30149280.21954; dbcl2="219542653:qAjjgVFgfE0"; ck=phh8; ap_v=0,6.0; push_noty_num=0; push_doumail_num=0; __utma=30149280.949109129.1582468791.1602402156.1605346877.20; __utmc=30149280; __utmz=30149280.1605346877.20.14.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/setting; __utmb=30149280.2.10.1605346877; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1605346877%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.777887215.1582468791.1602402156.1605346877.16; __utmb=223695111.0.10.1605346877; __utmc=223695111; __utmz=223695111.1605346877.16.11.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; _pk_id.100001.4cf6=fff8ec9a5e905564.1582468791.16.1605347953.1602402156.'
}
response=requests.get(url,headers=header)
req_parser = BeautifulSoup(response.content.decode('unicode_escape'),features="html.parser")
comments = req_parser.find_all('div',class_="comment-item")
if __name__ =="__main__":
movie_id = input("请输入电影id:")
comments_list=[]
times=25
n=1
types=['h','m','l']
for i in range(times):
print(i)
start_num=i*20
for j in range(3):
comments = get_page_info(start_num,type=types[j])
数据清洗
导入数据
import pandas as pd
df = pd.read_csv("/菜J学Python/豆瓣/35163988.csv")
df = df[['user_name','comment_voted','comment_voted','movie_star','comment_time','comment']]
df.head(10)
字段类型转换
df['comment_time'] = pd.to_datetime(df['comment_time'])
df["comment"] = df["comment"].astype('str')
机械压缩去重
#定义机械压缩函数
def yasuo(st):
for i in range(1,int(len(st)/2)+1):
for j in range(len(st)):
if st[j:j+i] == st[j+i:j+2*i]:
k = j + i
while st[k:k+i] == st[k+i:k+2*i] and k k = k + i
st = st[:j] + st[k:]
return st
yasuo(st="菜J学Python真的真的真的很菜很菜")
#应用压缩函数
df["comment"] = df["comment"].apply(yasuo)
情感分析
#pip3 install paddlepaddle -i https://mirror.baidu.com/pypi/simple
import paddlehub as hub
#这里使用了百度开源的成熟NLP模型来预测情感倾向
senta = hub.Module(name="senta_bilstm")
texts = df['comment'].tolist()
input_data = {'text':texts}
res = senta.sentiment_classify(data=input_data)
df['pos_p'] = [x['positive_probs'] for x in res]
数据可视化
df['comment'] = df['comment'].astype('str')
# 定义分词函数
def get_cut_words(content_series):
# 读入停用词表
stop_words = []
with open("./stop_words.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# 添加关键词
my_words = ['', '']
for i in my_words:
jieba.add_word(i)
# 自定义停用词
my_stop_words = ['节目', '中国','一部']
stop_words.extend(my_stop_words)
# 分词
word_num = jieba.lcut(content_series.str.cat(sep='。'), cut_all=False)
# 条件筛选
word_num_selected = [i for i in word_num if i not in stop_words and len(i)>=2]
return word_num_selected
# 绘制词云图
text1 = get_cut_words(content_series=df['comment'])
stylecloud.gen_stylecloud(text=' '.join(text1), max_words=200,
collocations=False,
font_path='字酷堂清楷体.ttf',
icon_name='fas fa-video',
size=653,
#palette='matplotlib.Inferno_9',
output_name='./演员2词云图.png')
Image(filename='./演员2词云图.png')声明
本数据分析只做学习研究之用途,提供的结论仅供参考;
作者对影视行业了解有限,相关描述可能存在不当之处,请勿上纲上线。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~