
盘点GAN在目标检测中的应用
看那个码农
共 3413字,需浏览 7分钟
· 2020-11-24
点击上方“机器学习与生成对抗网络”,关注"星标"
获取有趣、好玩的前沿干货!
1,2017-CVPR: A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection
摘要
如何学习对遮挡和变形不敏感的物体检测器?当前解决方案主要使用的是基于数据驱动的策略:收集具有不同条件下的对象物体的大规模数据集去训练模型,并期望希望最终可学习到不变性。 但数据集真的有可能穷尽所有遮挡吗?作者认为,像类别一样,遮挡和变形也有长尾分布问题:一些遮挡和变形在训练集是罕见的,甚至不存在。 提出了一种解决方案:学习一个对抗网络去生成具有遮挡和变形的样本。对抗的目标是生成难以被目标检测器分类的样本检测网络和对抗网络通过联合训练得到。实验结果表明,与Fast-RCNN方法相比,VOC07的mAP提升了2.3%,VOC2012的mAP提升了2.6%。

引言
一种可能的解决方法是通过采样来生成逼真的图像。然而,这实际上不太可行,因为图像生成将需要训练这些罕见样本。 另一个解决方案是生成所有可能的遮挡和变形,并从中训练物体检测器。但由于变形和遮挡的搜索空间很大,因此这实际上也不可行和灵活。 事实上,使用所有样本通常不是最佳解决方案,而选择“困难”的正样本更好。有没有办法可以生成具有不同遮挡和变形的困难正样本且无需生成像素级别的图像本身呢? 本文训练另一个网络:通过在空间上遮挡某些特征图区域或通过操纵特征图来创建空间变形以形成难样本的对抗网络。这里的关键思想是在卷积特征空间中创建对抗性样本,而不是直接生成像素级别的数据,因为后者是一个困难得多的问题。
方法
1,用于遮挡的Adversarial Spatial Dropout。作者提出使用一种Adversarial Spatial Dropout Network(ASDN)在前景目标的深层特征级别上生成遮挡。在标准的Fast-RCNN中,RoI池层之后获得每个前景对象的卷积特征;使用这些特征作为对抗网络的输入,ASDN以此生成一个掩码,指示要删除的特征部分(分配0),以使检测网络无法识别该对象。
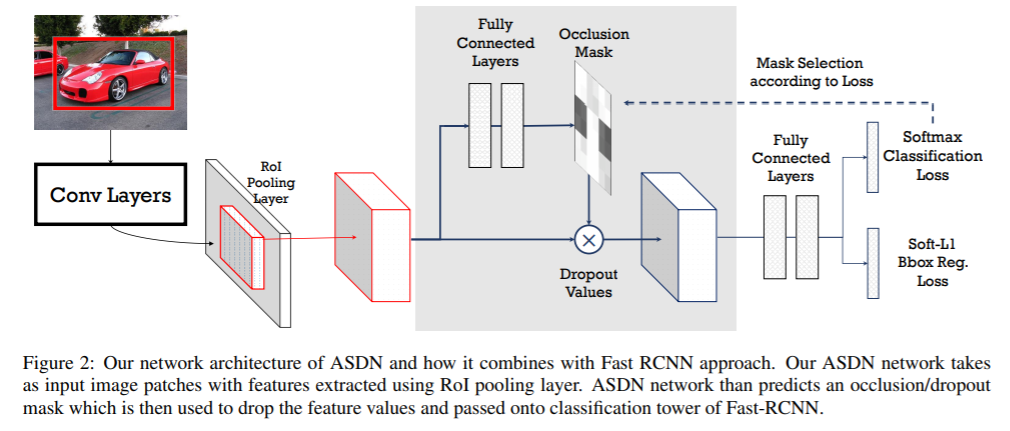
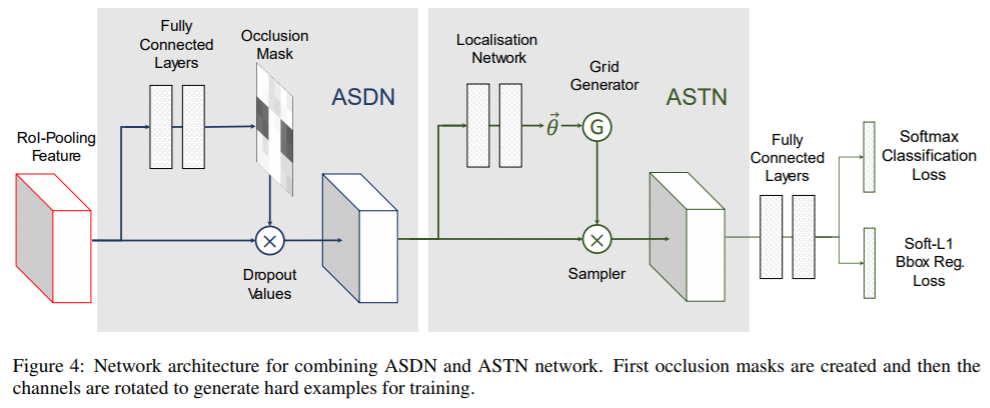
2,Adversarial Spatial Transformer Network(ASTN),关键思想是基于STN在特征上产生变形并使检测网络难以识别。通过与ASTN对抗,可以训练出更好的检测网络。 注:STN(Spatial Transformer Network )具有三个组成部分:localisation network, grid generator和sampler。给定特征图作为输入,localisation network将估计变形量(例如,旋转度、平移距离和比例因子)。这些变量将用作grid generator和sampler生成目标特征图的输入,输出是变形后的特征图。
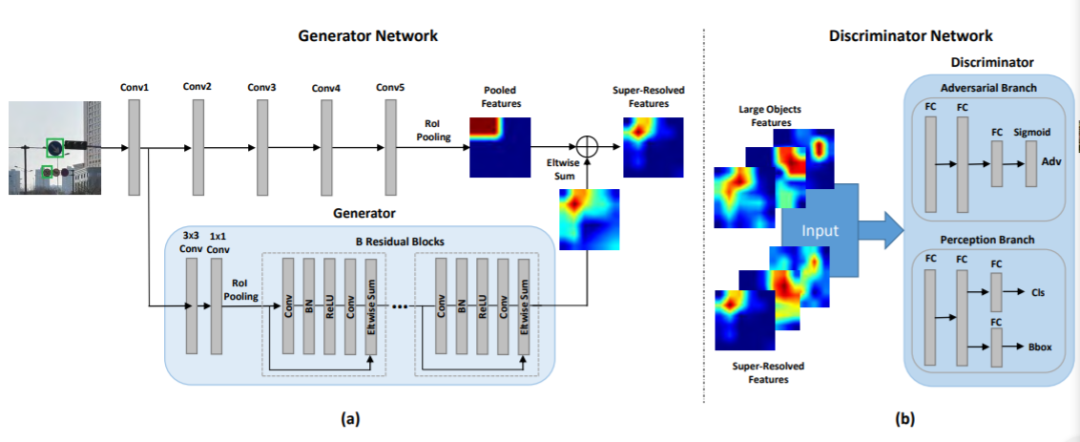
2,2017-CVPR: Perceptual Generative Adversarial Networks for Small Object Detection
小物体分辨率低、易受噪声影响,检测任务非常困难。现有检测方法通常学习多个尺度上所有目标的表征来检测小对象。但这种架构的性能增益通常限于计算成本。 这项工作将小物体的表征提升为“超分辨”表征,实现了与大物体相似的特性,因此更具判别性。通过结合生成对抗网络(Perceptual GAN)模型,缩小小对象与大对象之间的表征差异来改善小对象检测性能。具体来说,生成器学习将小对象表征转换为与真实大对象足够相似以欺骗对抗判别器的超分辨表征。同时,判别器与生成器对抗以识别生成的表征,并对生成器施加条件要求——生成的小对象表征必须有利于检测目标。
3,2018 Adversarial Occlusion-aware Face Detection
有遮挡人脸检测是一项具有挑战性的任务。通过同时检测被遮挡的人脸和分割被遮挡区域,本文引进一种对抗性遮挡人脸检测器Adversarial Occlusion-aware Face Detector (AOFD)。 为了检测重度遮挡的脸部,设计AOFD的出发点是:(1)有效地利用未被遮挡的面部区域,以及(2)将遮挡的干扰转化为有益的信息。 对于问题(1),未检测到的脸通常被遮住了关键特征部分,例如眼睛和嘴巴。一种可行的方法是在训练集中遮盖脸部的这些独特部分,迫使检测器了解即使暴露区域较少的人脸是什么样。为此,以对抗的方式设计了掩模生成器,以为每个正样本产生掩模。 对于问题(2),找到常见的遮挡有助于检测其背后的不完整面孔。因此,引入了“遮挡分割”分支去分割遮挡部分包括头发、眼镜、围巾、手和其他物体等。由于训练样本很少,这并非易事。因此,作者标记了从互联网下载的374个训练样本进行遮挡分割(该数据集记为SFS:small dataset for segmentation)。 如图2所示,在RoI之后添加了一个遮挡区域生成器,然后是一个分类分支和一个边界框回归分支。最后,分割分支负责对每个边界框内的遮挡区域进行分割。最终将结合分类,边界框回归和遮挡分割的最终结果输出。 实验表明,AOFD不仅明显优于MAFA遮挡的人脸检测数据集的最新技术,而且在用于普通人脸检测的基准数据集(如FDDB)上也达到了竞争性的检测精度。

4,2018-ECCV:SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network
目标检测是计算机视觉中的一个基本而重要的问题。尽管在大规模检测基准(例如COCO数据集)上对大/中型对象已经取得了令人印象深刻的结果,但对小对象的性能却远远不能令人满意。原因是小物体缺少足够的外观细节信息,这些信息可以将它们与背景或类似物体区分开。 为了解决小目标检测问题,提出了一种端到端的多任务生成对抗网络(MTGAN)。其中生成器是一个超分辨率网络,可以将小的模糊图像上采样到精细图像,并恢复详细信息以进行更精确的检测。判别器是一个多任务网络,该网络用真实/虚假分数,对象类别分数和边界框回归量来描述每个超分辨图像块。 此外,为了使生成器恢复更多细节以便于检测,在训练过程中,将判别器中的分类和回归损失反向传播到生成器中。 在具有挑战性的COCO数据集上进行的大量实验证明了该方法从模糊的小图像中恢复清晰的超分辨图像的有效性,并表明检测性能(特别是对于小型物体)比最新技术有所提高。
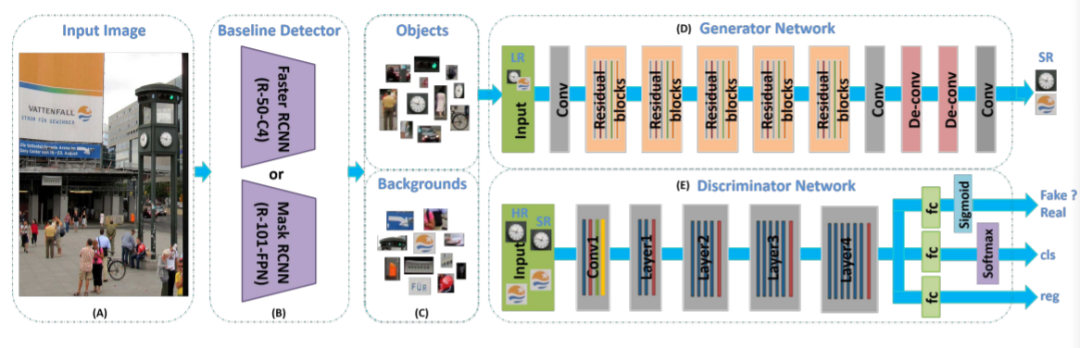
小物体检测系统(SOD-MTGAN):
(A)将图像输入网络。 (B)基线检测器可以是任何类型的检测器(例如Faster RCNN 、FPN或SSD),用于从输入图像中裁剪正(即目标对象)和负(即背景)例,以训练生成器和判别器网络,或生成ROIs进行测试。 (C)正例和负例(或ROI)是由现成的检测器生成的。 (D)生成器子网重建得到低分辨率输入图像的超分辨率版本(4倍放大);判别器网络将GT与生成的高分辨率图像区分开,同时预测对象类别并回归对象位置(判别器网络可以使用任何典型的体系结构,例如AlexNet、VGGNet、ResNet作为骨干网,在实验中使用ResNet-50或ResNet-101。
猜您喜欢:
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 | 超100篇!CVPR 2020最全GAN论文梳理汇总!
评论
堪称最优秀的Docker可视化管理工具——Portainer你真的会用吗?
来源:blog.csdn.net/shark_chili3007/article/details/123366179👉 欢迎加入小哈的星球 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利全栈前后端分离博客项目
小哈学Java
0
盘点Lombok的几个骚操作,你绝对没用过!
👉 欢迎加入小哈的星球 ,你将获得: 专属的项目实战 / Java 学习路线 / 一对一提问 / 学习打卡 / 赠书福利全栈前后端分离博客项目 2.0 版本完结啦, 演示链接:http://116.62.199.48/ ,新项目正在酝酿中
小哈学Java
0
Apache Paimon毕业,湖仓架构的未来发展趋势!
北京时间 2024 年 4 月 16日,开源软件基金会 Apache Software Foundation(以下简称 ASF)正式宣布 Apache Paimon 毕业成为 Apache 顶级项目(TLP, Top Level Project)。经过社区的共同努力和持续创新,Apache Paim
程序源代码
0
JS的这些新特性,你都用过么?
大厂技术 高级前端 Node进阶点击上方 程序员成长指北,关注公众号回复1,加入高级Node交流群作为一门不断演进的语言,JavaScript每年都会引入新特性。这些特性的加入,能够帮助我们编写更加简洁、高效、易于维护的代码。然而,并非所有新特性
程序员成长指北
1
【深度学习】人人都能看懂的LSTM
熟悉深度学习的朋友知道,LSTM是一种RNN模型,可以方便地处理时间序列数据,在NLP等领域有广泛应用。在看了台大李宏毅教授的深度学习视频后,特别是介绍的第一部分RNN以及LSTM,整个人醍醐灌顶。本文就是对视频的记录加上了一些个人的思考。0. 从RNN说起循环神经网络(Recurrent Neur
机器学习初学者
0
老爸嘲讽我了,写破代码一年就挣十几万,他在工地带50个工人,一个月光人头费就3万,让我滚回去跟他干!
点击上方 "大数据肌肉猿"关注, 星标一起成长点击下方链接,进入高质量学习交流群今日更新| 1052个转型案例分享-大数据交流群来自:网络,侵删有个网友的父亲是做工程的,天天就嘲笑他,说他天天写着破代码有啥用,一年就拿个十多万的死工资,然后告诉他自己在工地里面带了50个工人,一个月能抽三万
程序源代码
0
我发现 Lombok的几个骚操作,哈哈好用
大家好,我是小富~前言本文不讨论对错,只讲骚操作。有的方法看看就好,知道可以这么用,但是否应用到实际开发中,那就仁者见仁,智者见智了。一万个读者就会有一万个哈姆雷特,希望这篇文章能够给您带来一些思考。耐心看完,你一定会有所收获。@onX例如 onConstructor, oMet
程序员内点事
0
测试新人,如何快速上手一个陌生的系统!
大家好,我是狂师!作为刚入行不久的测试新人,面对一个陌生的系统时,可能会感到有些手足无措。面对一个全新的系统系统,如何快速上手并展开有效的测试工作是一个重要的挑战。本文将探讨测试新人如何通过一系列步骤和策略,快速熟悉并掌握新系统的测试要点,从而提高测试效率和质量。本文旨在为测试新手提供一份指导,帮助
测试开发技术
0