这一步都没做,还想搞自动化运维?
共 3161字,需浏览 7分钟
· 2020-11-24
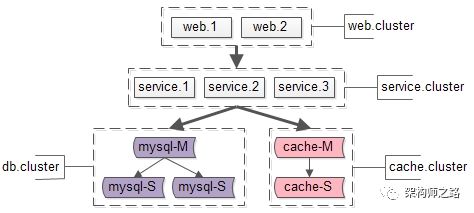
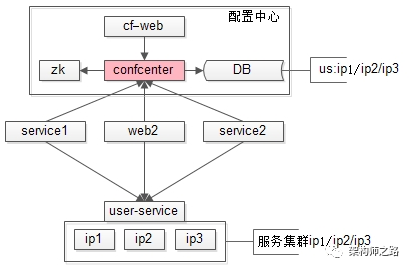
name : user.service
ip.list : ip1, ip2, ip3
bin.path : /user.service/bin/
ftp.path : ftp://192.168.0.1/USER_2_0_1_3/user.exe
自动化上线的过程,则是:
service.name : user.service
service.ip.list : ip1, ip2, ip3
service.port : 8080
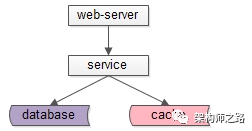
web-X调用user服务的过程,则是:
[user.service]
ip.list : ip1, ip2, ip3
port : 8080
bin.path : /user.service/bin/
log.path : /user.service/log/
conf.path : /user.service/conf/
owner.list : shenjian, ku
[passport.web]
ip.list : ip11, ip22, ip33
port : 80
bin.path : /passport.web/bin/
log.path : /passport.web/log/
conf.path : /passport.web/conf/
owner.list : shenjian, shuai
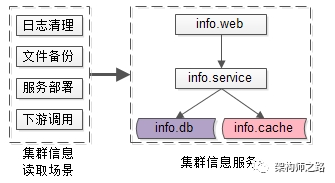
Info InfoService::getInfo(String ClusterName);
Bool InfoService::setInfo(String ClusterName, String key, String value);