
Linux文件系统之 — 通用块处理层
共 5816字,需浏览 12分钟
· 2020-11-19
概述
由于不同块设备(如磁盘,机械硬盘等)有着不同的设备驱动程序,为了让文件系统有统一的读写块设备接口,Linux实现了一个 通用块层。如下图中的红色部分:
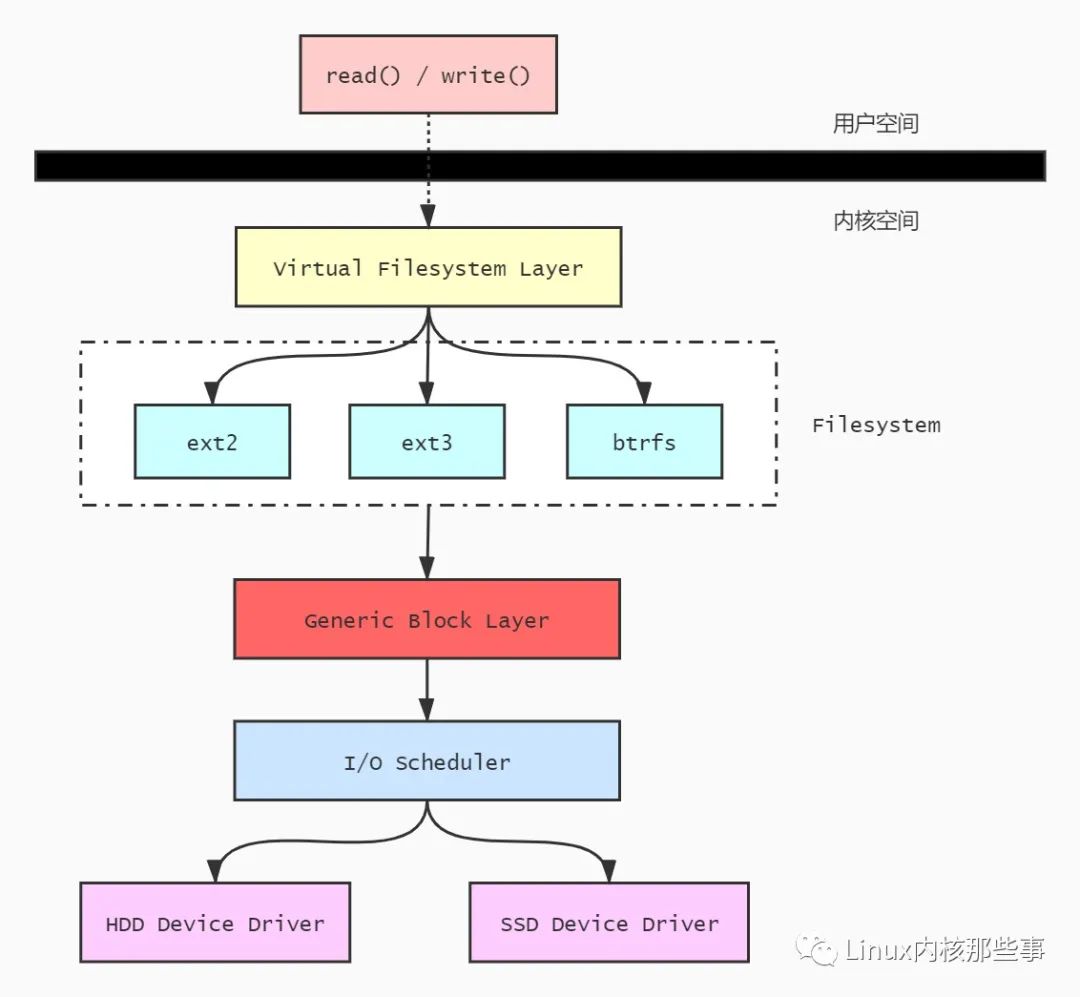
通用块层 的引入为了提供一个统一的接口让文件系统实现者使用,而不用关心不同设备驱动程序的差异,这样实现出来的文件系统就能用于任何的块设备。
通用块层 将对不同块设备的操作转换成对逻辑数据块的操作,也就是将不同的块设备都抽象成是一个数据块数组,而文件系统就是对这些数据块进行管理。如下图:
注意:不同的文件系统可能对逻辑数据块定义的大小不一样,比如 ext2文件系统 的逻辑数据块大小为 4KB。

通过对设备进行抽象后,不管是磁盘还是机械硬盘,对于文件系统都可以使用相同的接口对逻辑数据块进行读写操作。
通用块读写接口
通用块层 提供了 ll_rw_block() 函数对逻辑块进行读写操作,ll_rw_block() 函数的原型如下:
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[]);
在分析 ll_rw_block() 函数前,我们先来介绍一下 buffer_head 这个结构,因为要理解 ll_rw_block() 函数必须先了解 buffer_head 结构。
struct buffer_head 结构代表一个要进行读或者写的数据块,其定义如下:
struct buffer_head {
struct buffer_head *b_next; /* 用于快速查找数据块缓存 */
unsigned long b_blocknr; /* 数据块号 */
unsigned short b_size; /* 数据块大小 */
unsigned short b_list; /* List that this buffer appears */
kdev_t b_dev; /* 数据块所属设备 */
atomic_t b_count; /* 引用计数器 */
kdev_t b_rdev; /* 数据块所属真正设备 */
...
};
为了让读者更加清晰,上面忽略了 buffer_head 结构的某些字段,上面比较重要的是 b_blocknr 字段和 b_size 字段, b_blocknr 字段指定了要读写的数据块号,而 b_size 字段指定了数据块的大小。还有就是 b_rdev 字段,其指定了数据块所属的设备。
有了 buffer_head 结构,就可以对数据块进行读写操作。接下来,我们看看 ll_rw_block() 函数的实现:
void ll_rw_block(int rw, int nr, struct buffer_head *bhs[])
{
...
for (i = 0; i < nr; i++) {
struct buffer_head *bh = bhs[i];
/* 上锁 */
if (test_and_set_bit(BH_Lock, &bh->b_state))
continue;
/* 增加buffer_head的计数器 */
atomic_inc(&bh->b_count);
bh->b_end_io = end_buffer_io_sync;
...
submit_bh(rw, bh);
}
return;
...
}
下面介绍一下 ll_rw_block() 函数各个参数的作用:
rw:要进行的读或者写操作,一般可选的值为READ、WRITE或者READA等。nr:bhs数组的大小。bhs:要进行读写操作的数据块数组。
ll_rw_block() 函数的实现比较简单,遍历 bhs 数组,并且对所有的 buffer_head 进行上锁和增加其计数器,然后调用 submit_bh() 函数把其提交到 IO调度层 进行I/O操作。
我们接着看看 submit_bh() 函数的实现:
void submit_bh(int rw, struct buffer_head *bh)
{
int count = bh->b_size >> 9; // 一个数据块需要的扇区数
...
set_bit(BH_Req, &bh->b_state);
bh->b_rdev = bh->b_dev;
bh->b_rsector = bh->b_blocknr * count; // 转换成真实的扇区号
generic_make_request(rw, bh);
switch (rw) {
case WRITE:
kstat.pgpgout += count;
break;
default:
kstat.pgpgin += count;
break;
}
}
数据块是 通用块层 的概念,而真实的块设备是以扇区作为读写单元的。所以在进行IO操作前,必须将数据块号转换成真正的扇区号,而代码 bh->b_blocknr * count 就是用于将数据块号转换成扇区号。转换成扇区号后,submit_bh() 函数接着调用 generic_make_request() 进行下一步的操作。
我们接着分析 generic_make_request() 函数的实现:
void generic_make_request(int rw, struct buffer_head * bh)
{
request_queue_t *q;
...
do {
q = blk_get_queue(bh->b_rdev); // 获取块设备对应的I/O请求队列
if (!q) {
...
break;
}
} while (q->make_request_fn(q, rw, bh)); // 把I/O请求发送到块设备的I/O请求队列中
}
每一个块设备都有一个类型为 request_queue_t 的I/O请求队列,而 blk_get_queue() 函数用于获取块设备对应的I/O请求队列,然后调用I/O请求队列的 mark_request_fn() 方法把I/O请求添加到队列中。
那么I/O请求队列的 mark_request_fn() 方法到底是什么呢?这个方法由块设备驱动提供,也可以通过调用 blk_init_queue() 函数设置为默认的 __make_request() 方法。我们主要分析默认的 __make_request() 方法:
static int __make_request(request_queue_t *q, int rw, struct buffer_head *bh)
{
...
elevator_t *elevator = &q->elevator;
count = bh->b_size >> 9; // 要读写的扇区数
sector = bh->b_rsector; // 进行读写操作的开始扇区号
...
again:
req = NULL;
head = &q->queue_head; // I/O请求队列头部
spin_lock_irq(&io_request_lock); // 关闭中断并且上自旋锁
insert_here = head->prev; // 插入到IO请求队列的最后
...
// 尝试合并I/O请求
el_ret = elevator->elevator_merge_fn(q, &req, head, bh, rw, max_sectors);
switch (el_ret) {
case ELEVATOR_BACK_MERGE: // 与其他I/O请求合并成功
...
goto out;
case ELEVATOR_FRONT_MERGE: // 与其他I/O请求合并成功
...
goto out;
case ELEVATOR_NO_MERGE: // 如果不能合并I/O请求
if (req)
insert_here = &req->queue;
break;
...
}
req = get_request(q, rw); // 获取一个空闲的I/O请求对象
...
req->cmd = rw;
req->errors = 0;
req->hard_sector = req->sector = sector; // 读写操作的开始扇区号
req->hard_nr_sectors = req->nr_sectors = count; // 要读写多少个扇区
req->current_nr_sectors = count;
req->nr_segments = 1;
req->nr_hw_segments = 1;
req->buffer = bh->b_data; // 读写数据存放的缓冲区
req->waiting = NULL;
req->bh = bh;
req->bhtail = bh;
req->rq_dev = bh->b_rdev;
add_request(q, req, insert_here); // 把I/O请求对象添加到I/O请求队列中
out:
...
return 0;
}
__make_request() 函数首先通过调用 elevator->elevator_merge_fn() 方法尝试将当前I/O请求与其他正在排队的I/O请求进行合并,因为如果当前I/O请求与正在排队的I/O请求相邻,那么就可以合并为一个I/O请求,从而减少对设备I/O请求的次数。
如果不能与排队的I/O请求进行合并,那么就调用 get_request() 函数申请一个I/O请求对象,然后初始化此对象各个字段,再通过调用 add_request() 函数把I/O请求对象添加到I/O请求队列中。add_request() 函数实现如下:
static inline void
add_request(request_queue_t *q, struct request *req, struct list_head *insert_here)
{
drive_stat_acct(req->rq_dev, req->cmd, req->nr_sectors, 1);
...
list_add(&req->queue, insert_here);
}
add_request() 函数的实现非常简单,首先调用 drive_stat_acct() 函数更新统计信息,然后调用 list_add() 函数把I/O请求添加到I/O请求队列中。
执行I/O请求
ll_rw_block() 函数只是把I/O请求添加到设备的I/O请求队列中,那么I/O请求队列中的I/O请求什么时候会执行呢?答案就是当调用 run_task_queue(&tq_disk) 函数时。
run_task_queue() 函数是 Linux 用于运行任务队列的入口,而 tq_disk 队列就是块设备I/O的任务队列。当执行 run_task_queue(&tq_disk) 函数时,便会处理 tq_disk 任务队列中的例程。
当调用 ll_rw_block() 函数添加I/O请求时,会触发调用 generic_plug_device() 函数,而 generic_plug_device() 函数会把设备的I/O请求队列添加到 tq_disk 任务队列中, generic_plug_device() 函数实现如下:
static void generic_plug_device(request_queue_t *q, kdev_t dev)
{
if (!list_empty(&q->queue_head) || q->plugged)
return;
q->plugged = 1;
queue_task(&q->plug_tq, &tq_disk); // 把I/O请求队列添加到 tq_disk 任务队列中
}
通过 Linux 的任务队列机制,设备的I/O请求队列将会被执行。执行I/O请求主要是由块设备驱动完成,在块设备驱动程序初始化时可以通过调用 blk_init_queue() 函数指定处理I/O请求队列的方法。blk_init_queue() 函数原型如下:
void blk_init_queue(request_queue_t *q, request_fn_proc *rfn);
参数 rfn 就是处理I/O请求队列的例程函数。