 极市平台
极市平台





极市导读
本文介绍了基础的Attention模型的应用,并通过论文讨论了Attention机制的各种变体。文章讲述详细,能够帮助大家对注意力机制有更全面的了解。>>加入极市CV技术交流群,走在计算机视觉的最前沿
目前深度学习中热点之一就是注意力机制(Attention Mechanisms)。Attention源于人类视觉系统,当人类观察外界事物的时候,一般不会把事物当成一个整体去看,往往倾向于根据需要选择性的去获取被观察事物的某些重要部分,比如我们看到一个人时,往往先Attend到这个人的脸,然后再把不同区域的信息组合起来,形成一个对被观察事物的整体印象。
「同理,Attention Mechanisms可以帮助模型对输入的每个部分赋予不同的权重,抽取出更加关键及重要的信息,使模型做出更加准确的判断,同时不会对模型的计算和存储带来更大的开销,这也是Attention Mechanism应用如此广泛的原因」,尤其在Seq2Seq模型中应用广泛,如机器翻译、语音识别、图像释义(Image Caption)等领域。Attention既简单,又可以赋予模型更强的辨别能力,还可以用于解释神经网络模型(例如机器翻译中输入和输出文字对齐、图像释义中文字和图像不同区域的关联程度)等。
本文主要围绕核心的Attention机制以及Attention的变体展开。
Seq2Seq Model
Attention主要应用于Seq2Seq模型,故首先简介一下Seq2Seq模型。Seq2Seq模型目标是学习一个输入序列到输出序列的映射函数。应用场景包括:机器翻译(Machine translation)、自动语音识别(Automatic speech recognition)、语音合成(Speech synthesis)和手写体生成(Handwriting generation)。
Seq2Seq模型奠基性的两个工作如下:
NIPS2014:Sequence to Sequence Learning with Neural Networks[1]
该论文介绍了一种基于RNN(LSTM)的Seq2Seq模型,基于一个Encoder和一个Decoder来构建基于神经网络的End-to-End的机器翻译模型,其中,Encoder把输入编码成一个固定长度的上下文向量,Decoder基于「上下文向量」和「目前已解码的输出」,逐步得到完整的目标输出。这是一个经典的Seq2Seq的模型,但是却存在「两个明显的问题」:
把输入的所有信息有压缩到一个固定长度的隐向量,忽略了输入的长度,当输入句子长度很长,特别是比训练集中所有的句子长度还长时,模型的性能急剧下降(Decoder必须捕捉很多时间步之前的信息,虽然本文使用LSTM在一定程度上能够缓解这个问题)。
把输入编码成一个固定的长度过程中,对于句子中每个词都赋予相同的权重,这样做是不合理的。比如,在机器翻译里,输入的句子与输出句子之间,往往是输入一个或几个词对应于输出的一个或几个词。因此,对输入的每个词赋予相同权重,这样做没有区分度,往往使模型性能下降。
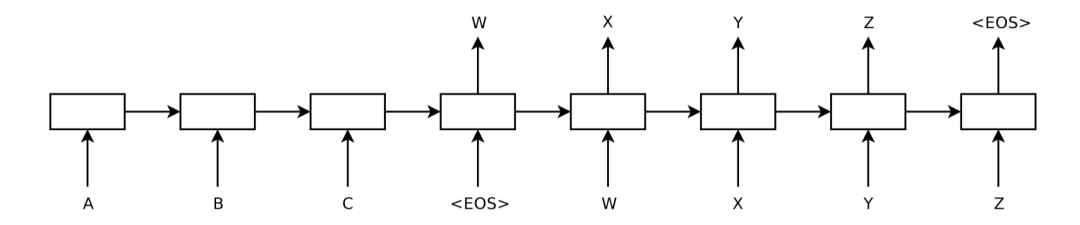
注意上图中Encoder得到的上下文向量「仅用于作为Decoder的第一个时间步的输入」。
EMNLP2014:Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation[2]
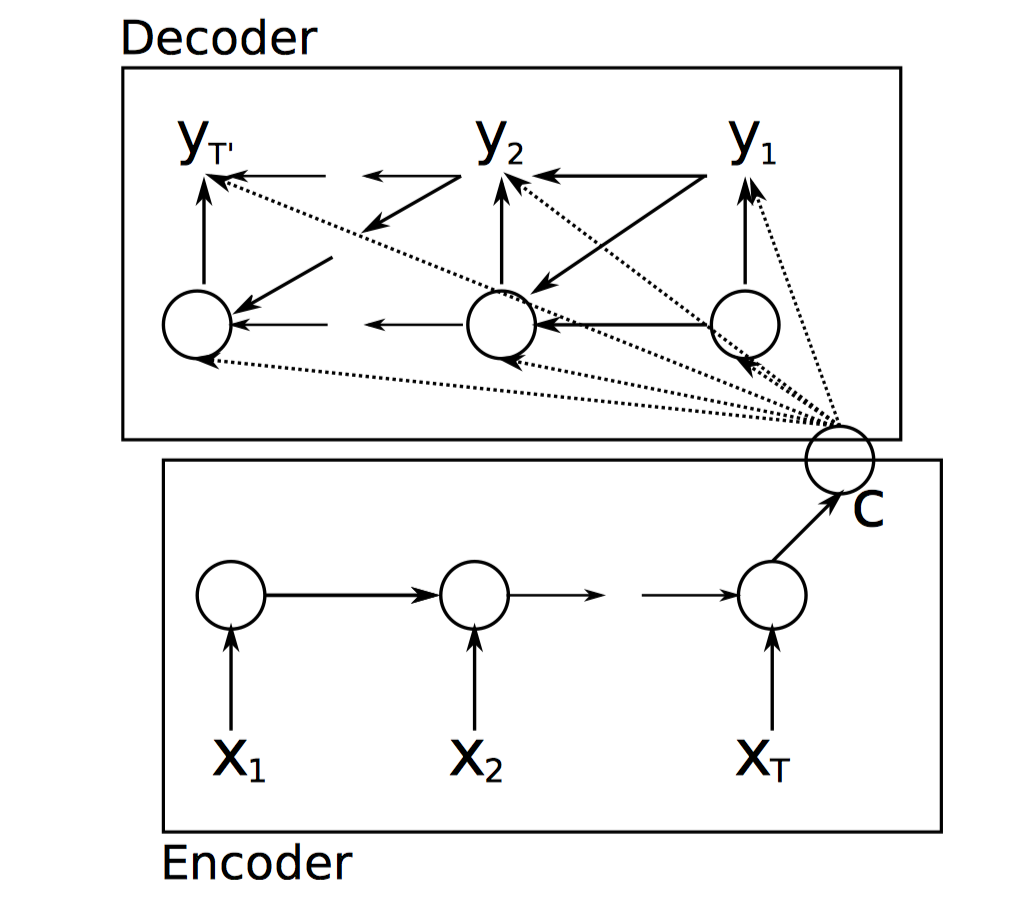
「Encoder」
「Decoder」
Attention
Basic Attention
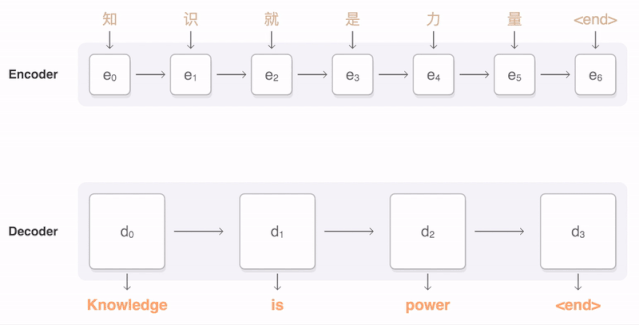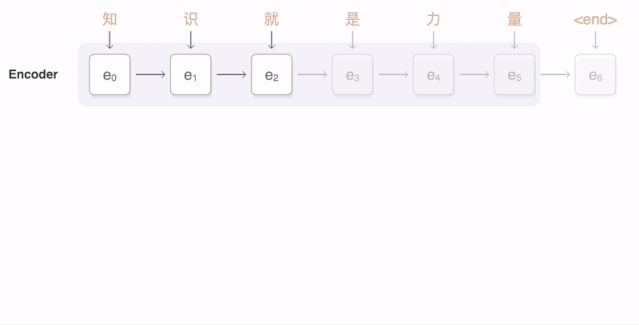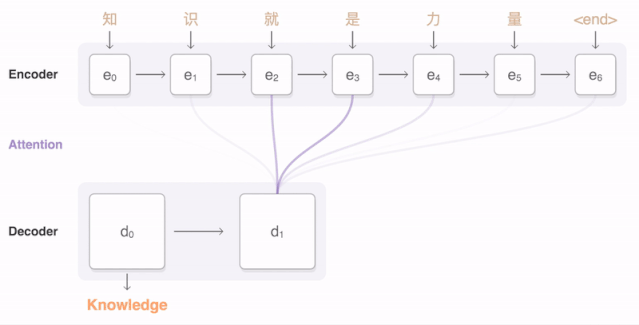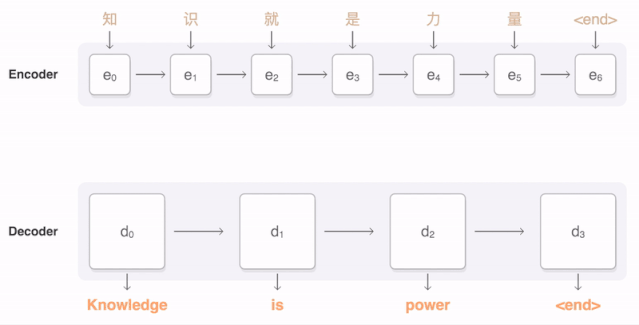
Machine Translation
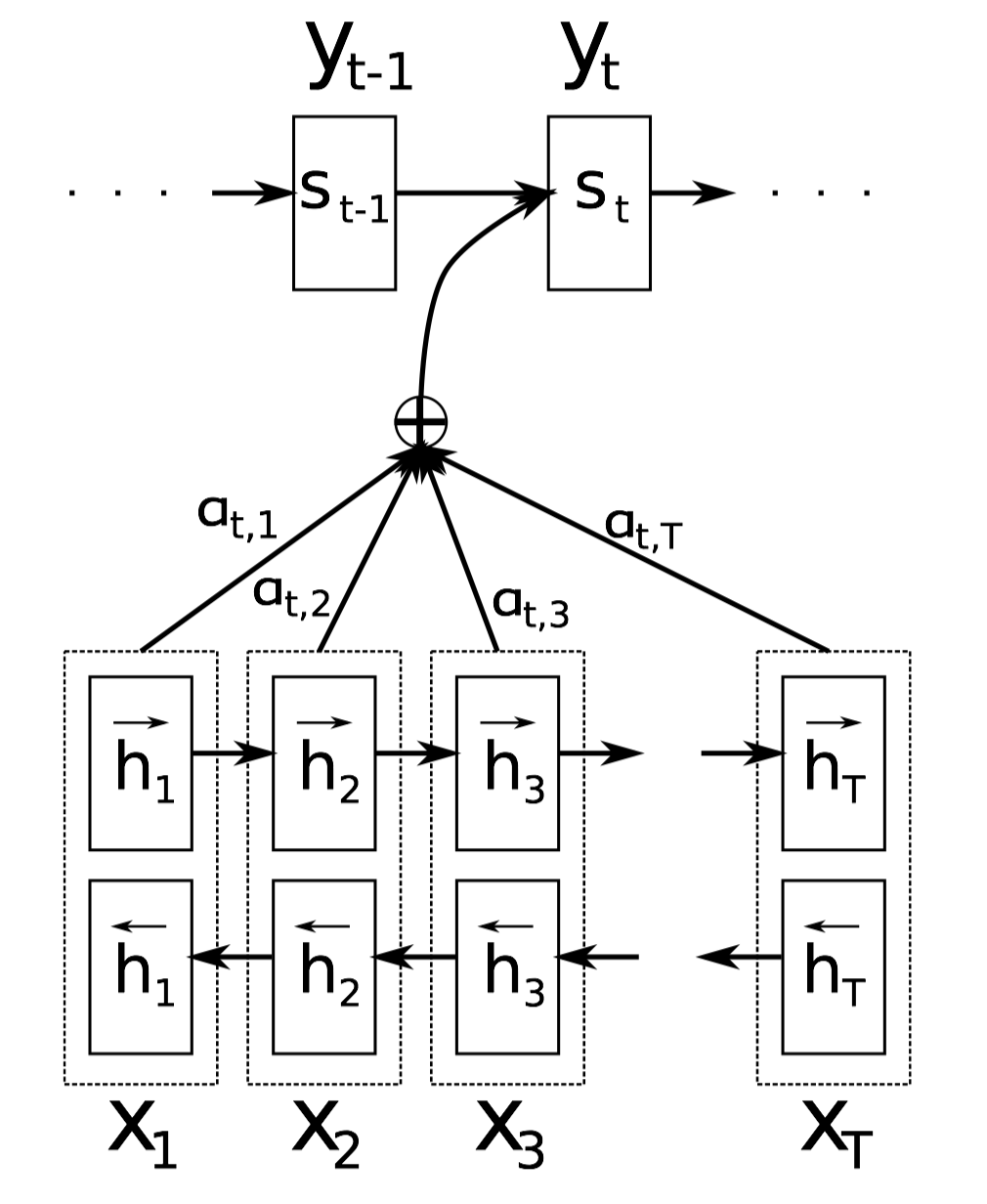
Image Caption
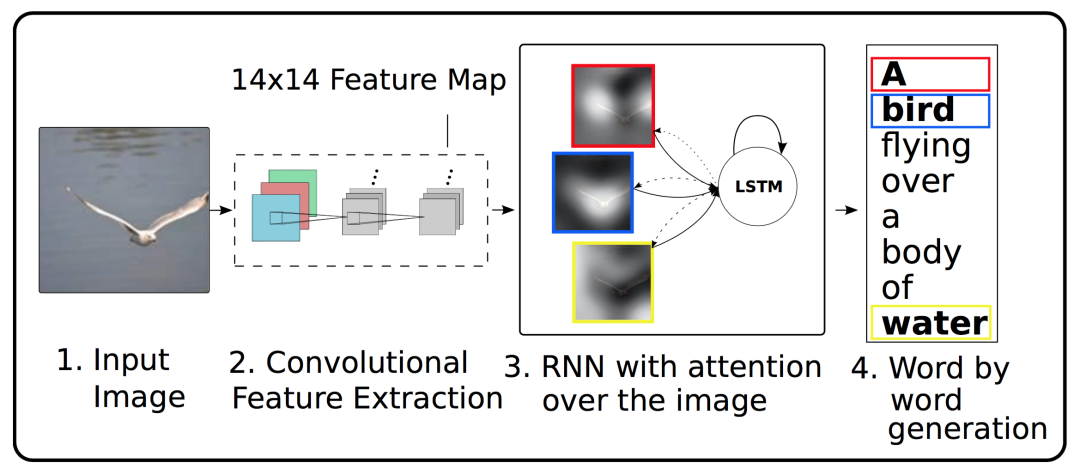
「Encoder」
「Decoder」
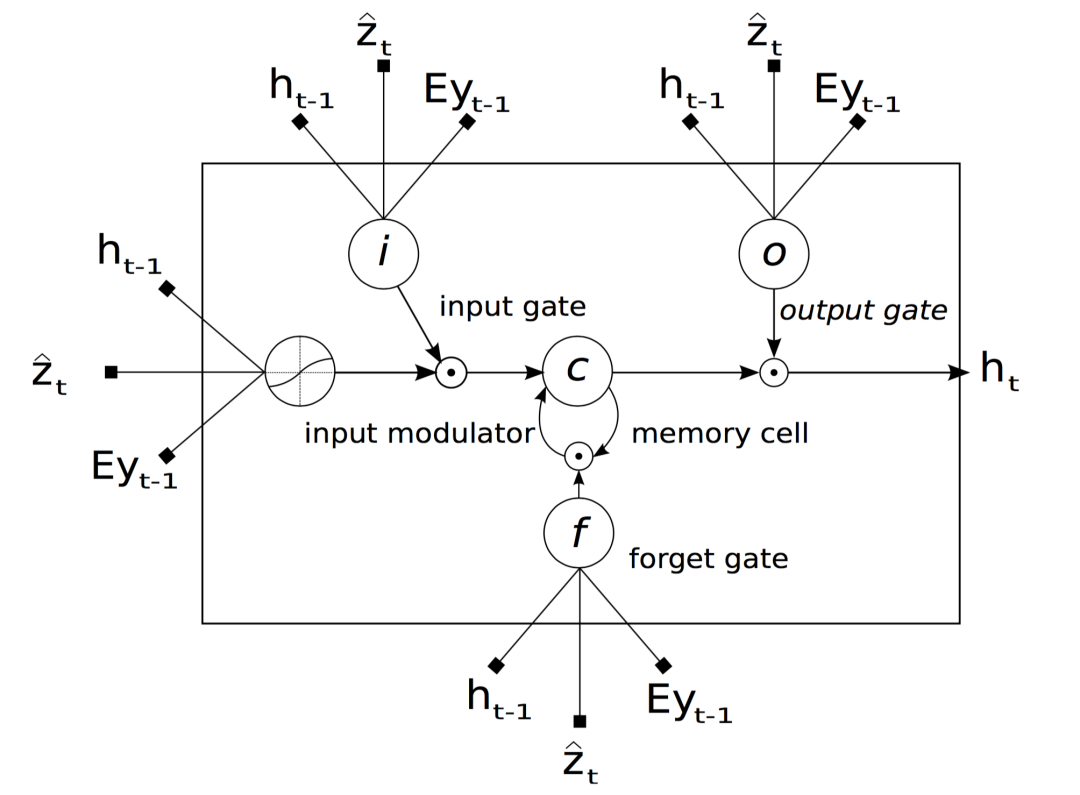
解码的输出:模型生成的一句caption被表示为各个词的one-hot编码所构成的集合,输出的caption y表示为:
LSTM初始输入:
LSTM中的记忆单元与隐藏单元的初始值,是两个不同的多层感知机,采用所有特征区域的平均值来进行预测的:
Speech Recognition
Entailment
Text Summarization
Attention Variants
「基于强化学习的注意力机制」:选择性的Attend输入的某个部分 「全局&局部注意力机制」:其中,局部注意力机制可以选择性的Attend输入的某些部分 「多维度注意力机制」:捕获不同特征空间中的Attention特征。 「多源注意力机制」:Attend到多种源语言语句 「层次化注意力机制」:word->sentence->document 「注意力之上嵌一个注意力」:和层次化Attention有点像。 「多跳注意力机制」:和前面两种有点像,但是做法不太一样。且借助残差连接等机制,可以使用更深的网络构造多跳Attention。使得模型在得到下一个注意力时,能够考虑到之前的已经注意过的词。 「使用拷贝机制的注意力机制」:在生成式Attention基础上,添加具备拷贝输入源语句某部分子序列的能力。 「基于记忆的注意力机制」:把Attention抽象成Query,Key,Value三者之间的交互;引入先验构造记忆库。 「自注意力机制」:自己和自己做attention,使得每个位置的词都有全局的语义信息,有利于建立长依赖关系。
Reinforcement-learning based Attention
NIPS2014: Recurrent Models of Visual Attention[1] ICLR2015: Multiple Object Recognition with Visual Attention [2]
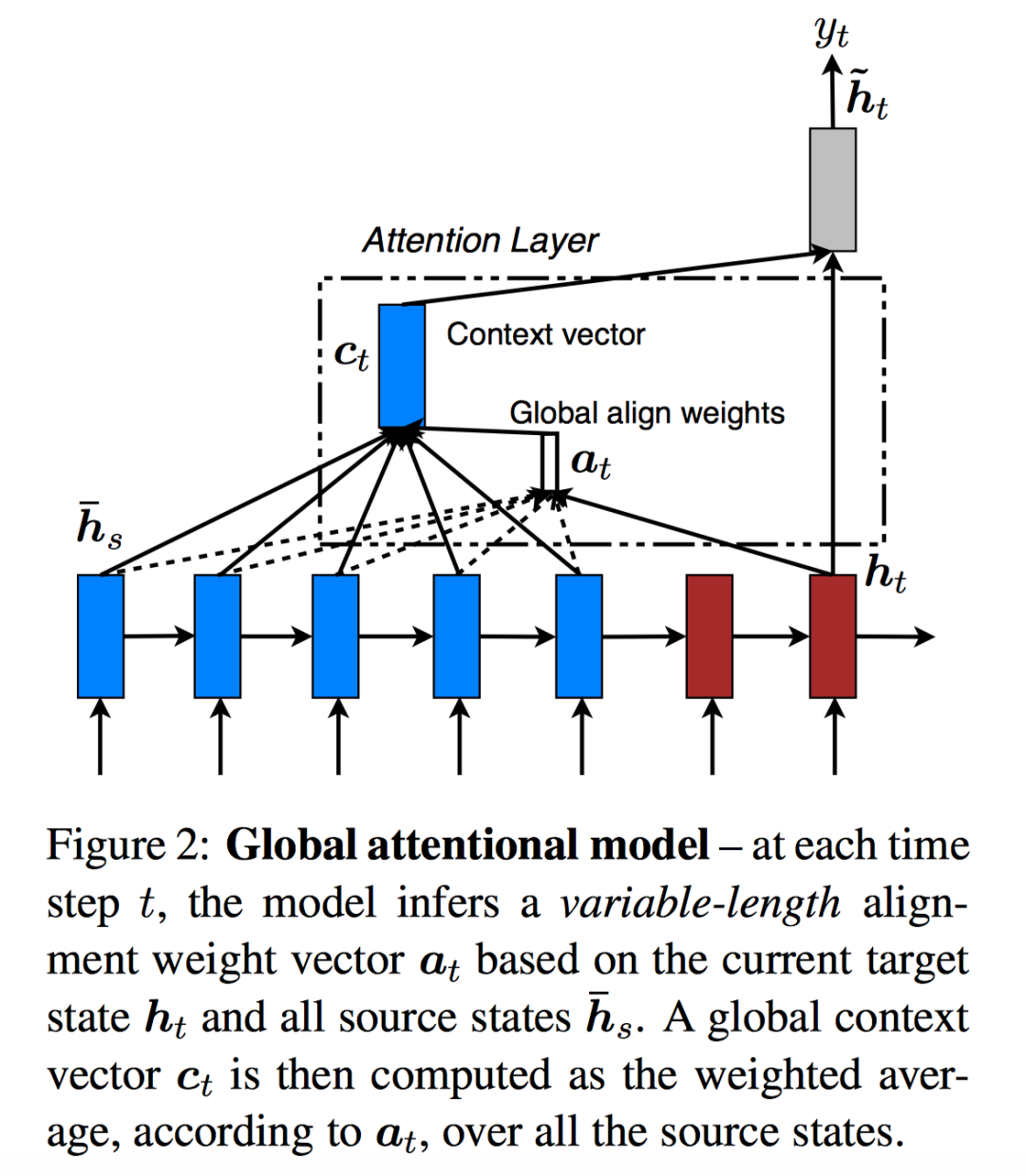
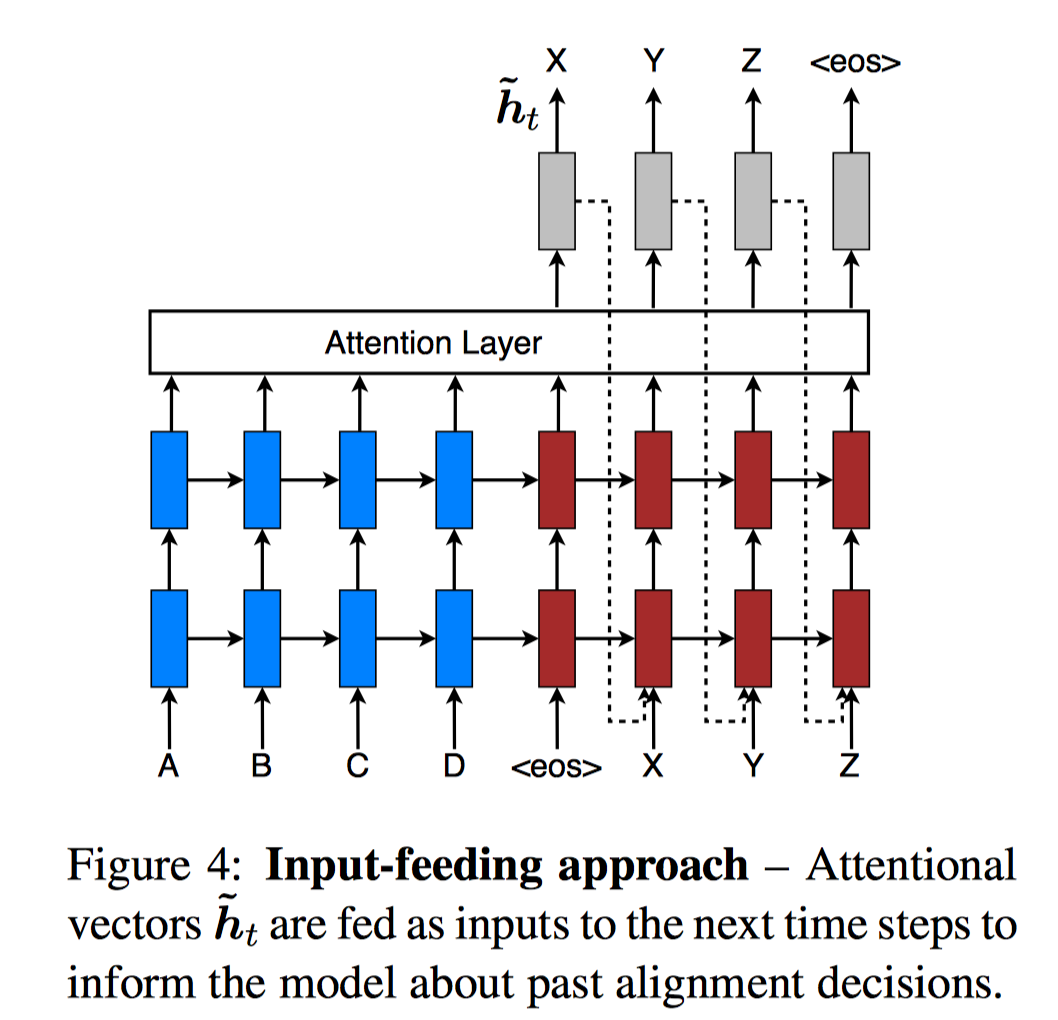
Global & Local Attention
EMNLP2015: Effective Approaches to Attention-based Neural Machine Translation[3]
Encoder得到的源语句单词 的隐状态为:; Decoder中目标语句单词 的隐状态为:; 对每一个目标单词 ,使用Attention机制计算的上下文向量为 ; Attention机制中的对齐模型为 (前面文章中都是使用 , 即「前一个时间步」的Decoder隐状态和Encoder隐状态来计算对齐权重)。
对齐模型计算:
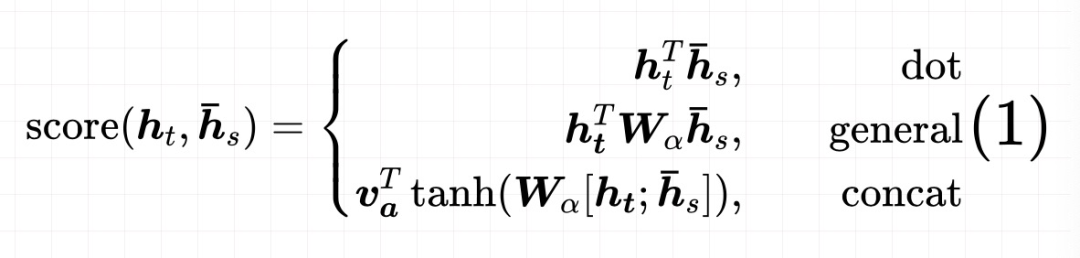
上下文向量计算:
注意图中,框起来的部分作者称为Attention Layer。
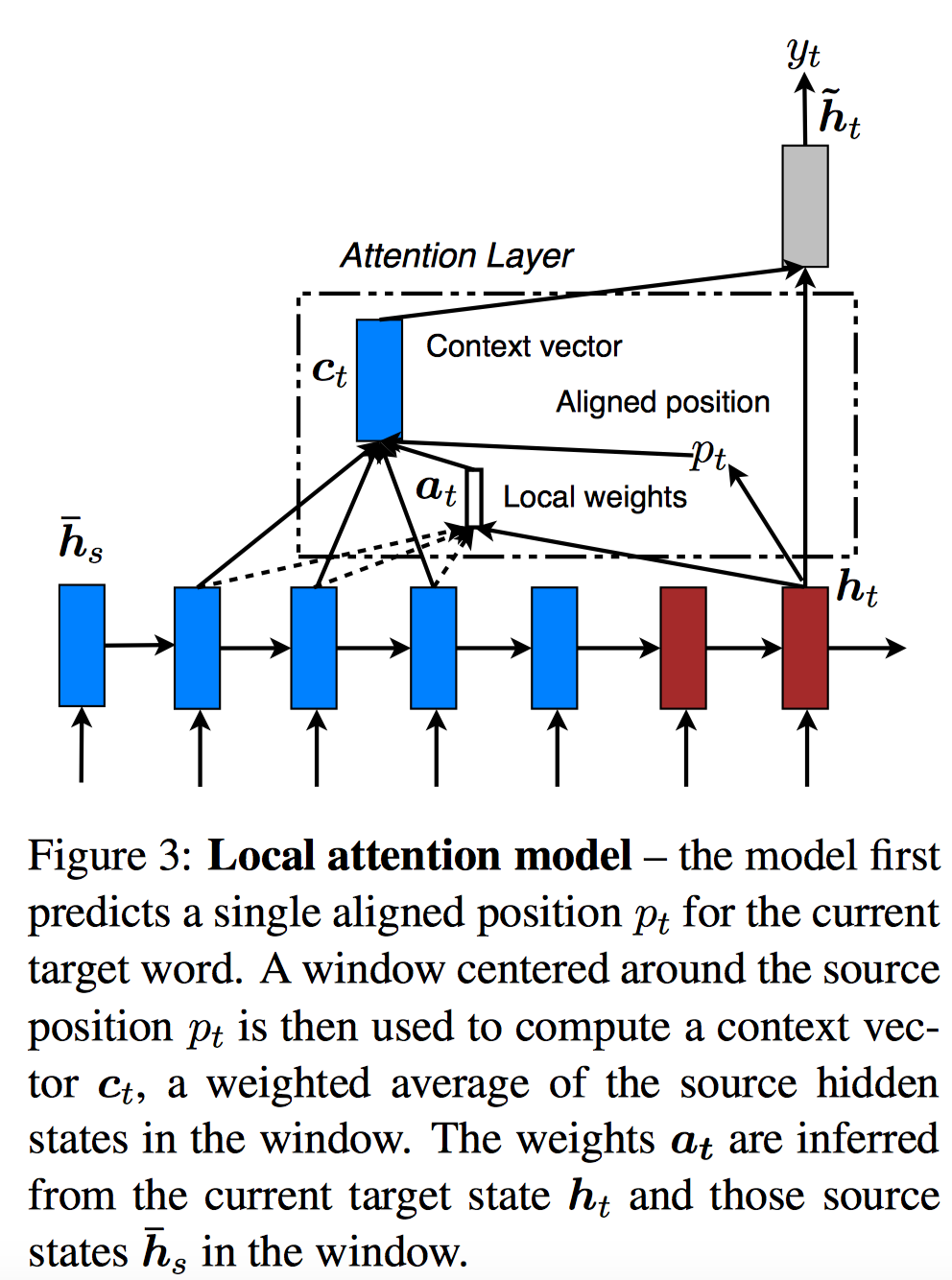
对齐位置模型」: 是源语句长度。只与 时刻Decoder状态 有关。
对齐权重模型: 也就是在global Attention对齐模型基 础上加了高斯函数指数衰减。 。
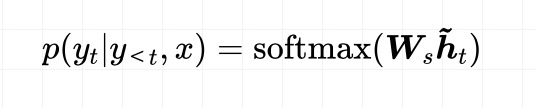
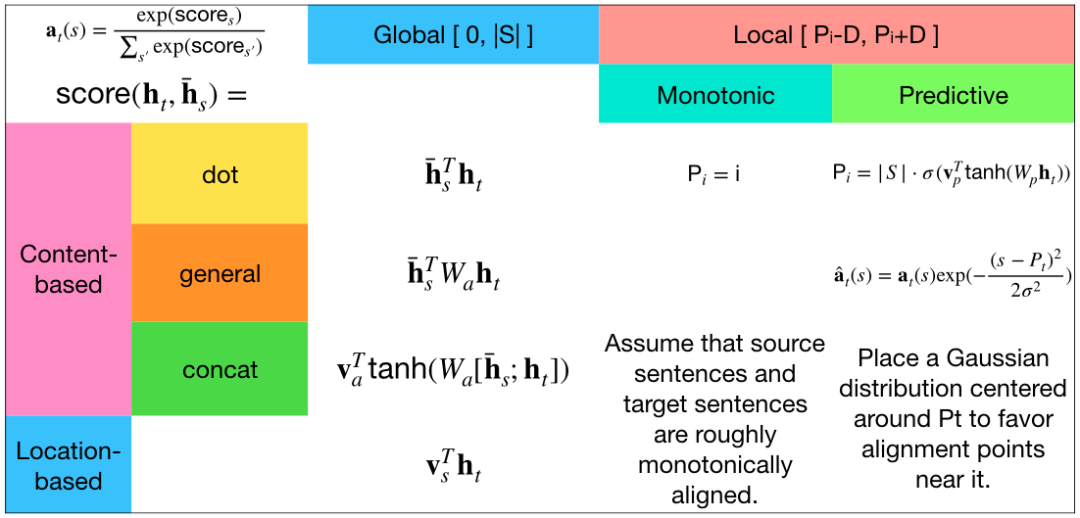
Multi-dimensional Attention
AAAI2018:DiSAN: Directional Self-Attention Network for RNN/CNN-Free Language Understanding[4]
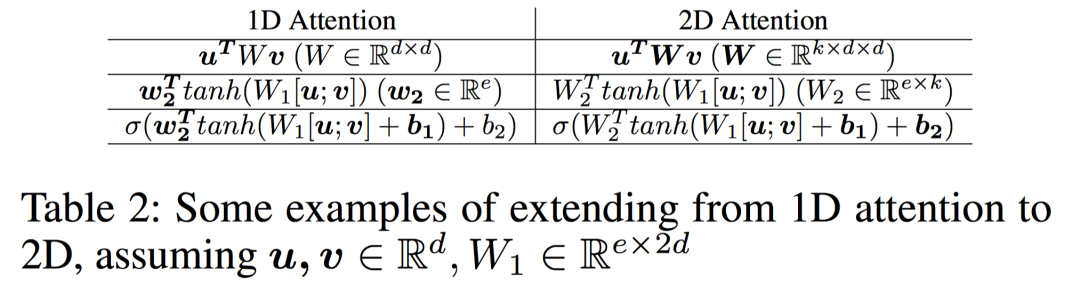
Multi-Source Attention
NAACL-HLT2016:Multi-Source Neural Translation[5]
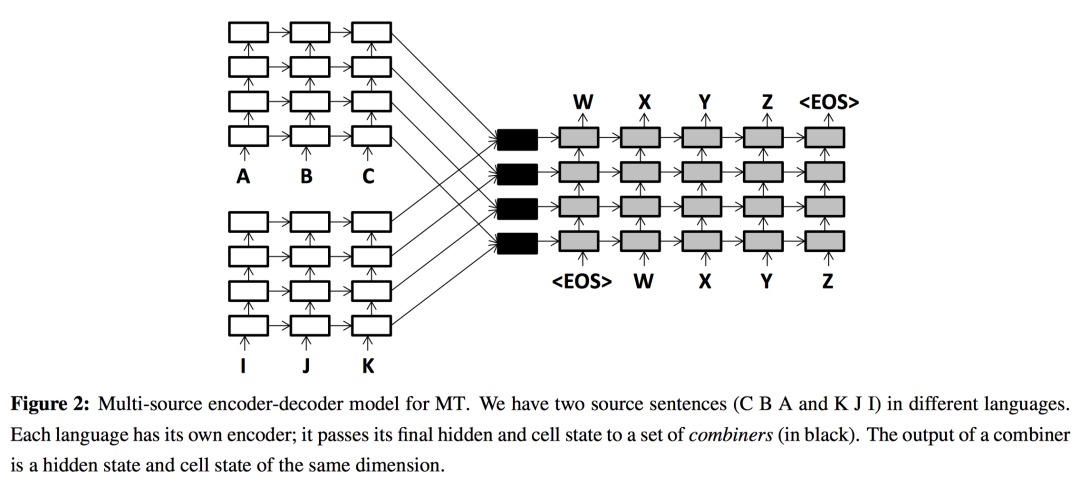
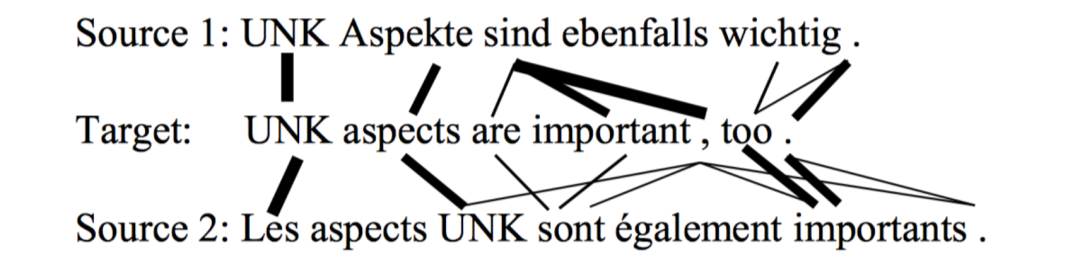
最基本的combiner:对于hideen state,就是把两个encoder的隐状态concat起来,再做一个线性变换+tanh激活:
。对于cell state,直接相加:
LSTM variant combiner:
Hierarchical Attention
NAACL-HLT2016:Hierarchical Attention Networks for Document Classification[7]
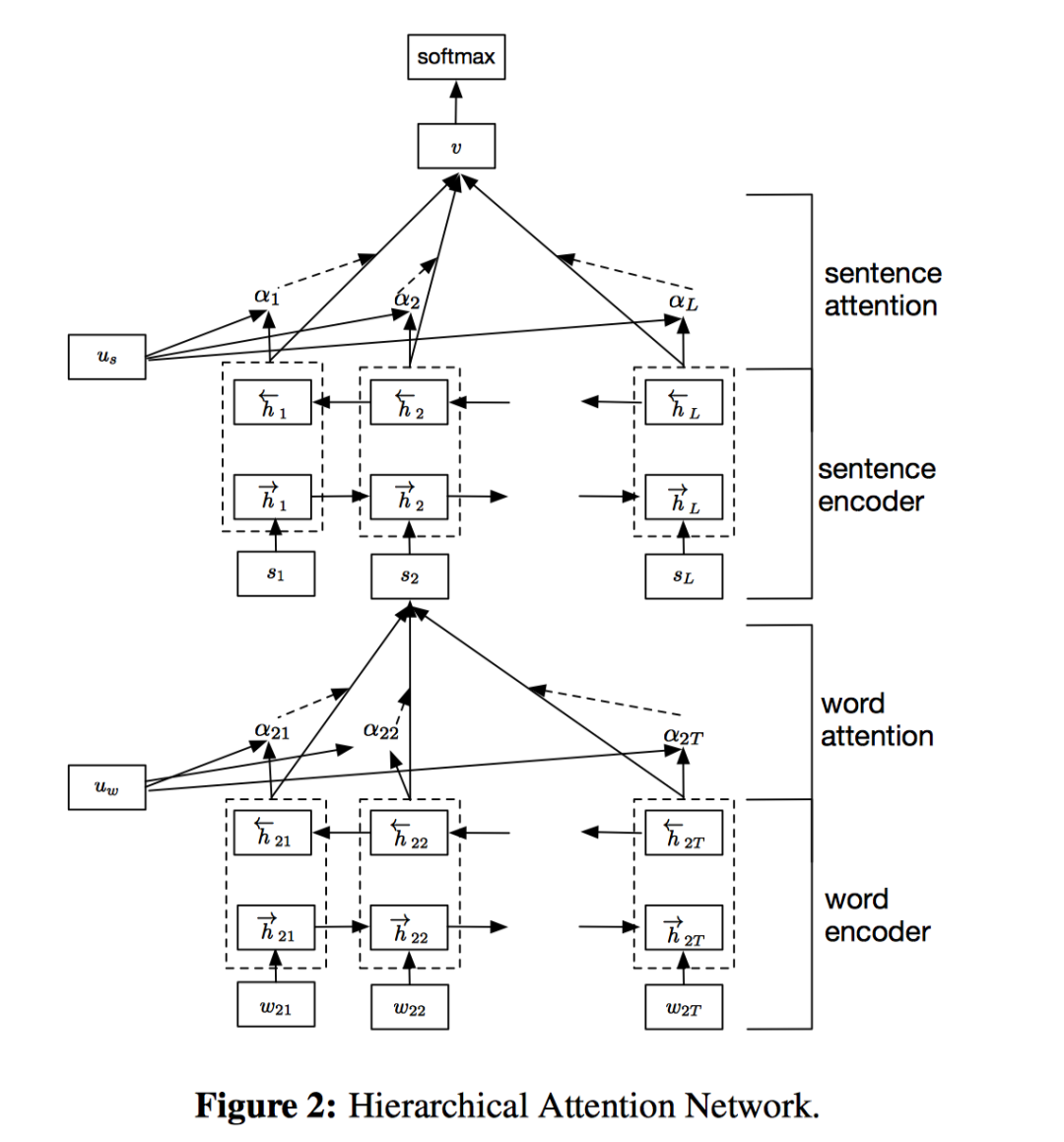
词先经过Bidirectional RNN(GRU)提取到word annotation,然后经过1个MLP得到word annotation对应的隐表示(这一步在Basic Attention中没有), 然后使用该隐表示和全局的「word-level上下文隐向量」 进行对齐,计算相似性,得到softmax后的attention权重, 最后对句子内的词的word annotation根据attention权重加权,得到每个句子的向量表示。 接着,将得到的句子表示同样经过Bidirectional RNN(GRU)提取sentence annotation,再经过MLP得到对应的隐表示,接着将其和全局的「sentence-level上下文隐向量」 进行对齐计算,得到句子的attention权重,最后加权sentence annotation得到文档级别的向量表示。得到文档表示后再接一个softmax全连接层用于分类。
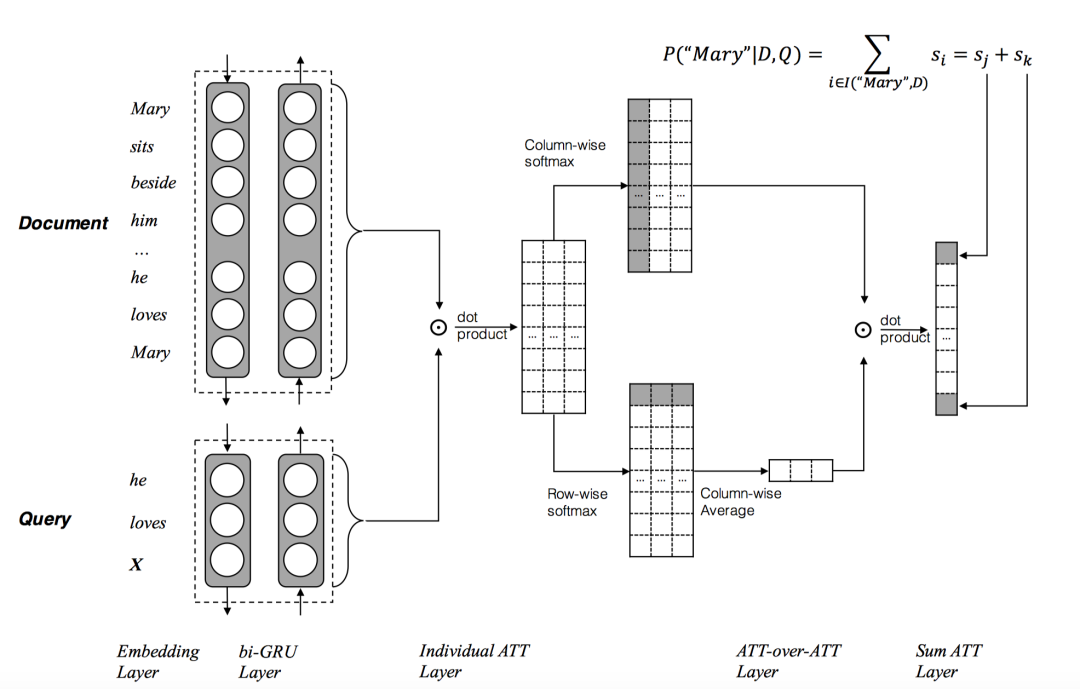
Attention over Attention
ACL2017:Attention-over-Attention Neural Networks for Reading Comprehension[8]
推荐阅读
即插即用,Triplet Attention机制让Channel和Spatial交互更加丰富(附开源代码)
线性Attention的探索:Attention必须有个Softmax吗?
那些轻轻拍了拍Attention的后浪们





