




前言
你还在为一个一个下载壁纸而烦恼吗。那有没有更加简单的方法呢?跟着我,一起来看看我是如何批量下载美女图片呢,我们以美桌壁纸为例,下载全部美女图片。
01
首先,你要安装pycharm软件,具体操作可以参考这篇文章:Pycharm安装及创建项目教程,爬虫主要工具可以参考这篇文章:Python主要爬虫工具
今天介绍如何在Pycharm安装lxml模块和requests模块
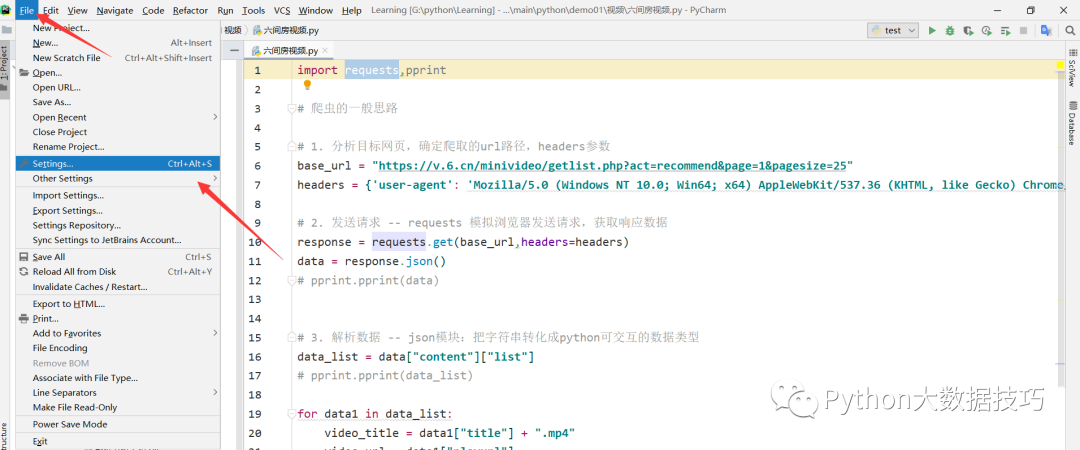
依次点击Project: (这里是你创建的名字),在点下面的Project Interpreter,点击 + 号进行添加模块
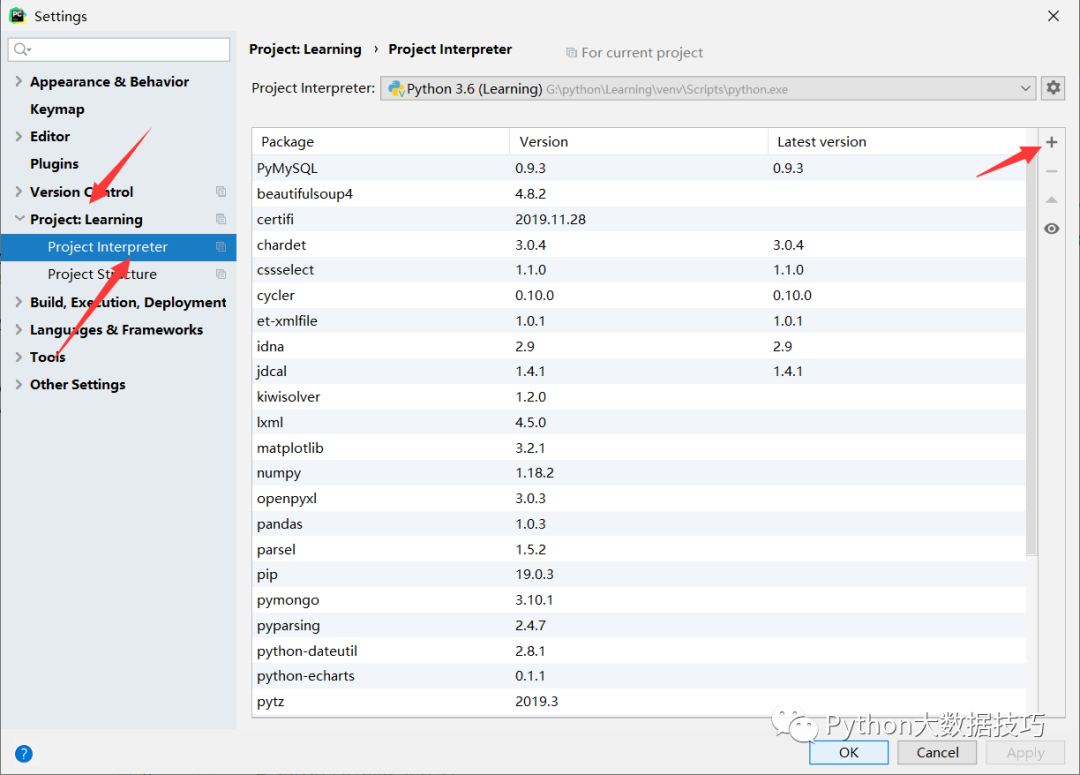
打开后,在空格里添加你要下载的模块,点击Install Package 进行下载,下载过程会很慢,这时候我们添加国内镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple
02
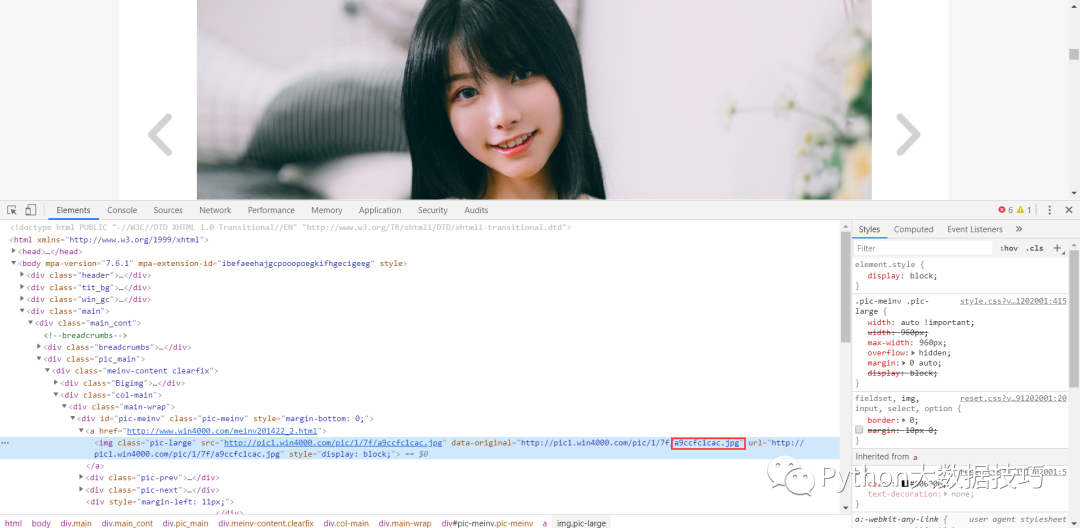
爬虫思路分析,进入我们要分析的网页,第一张图片。右键检查,到下面页面。点击连接,到下一个网页
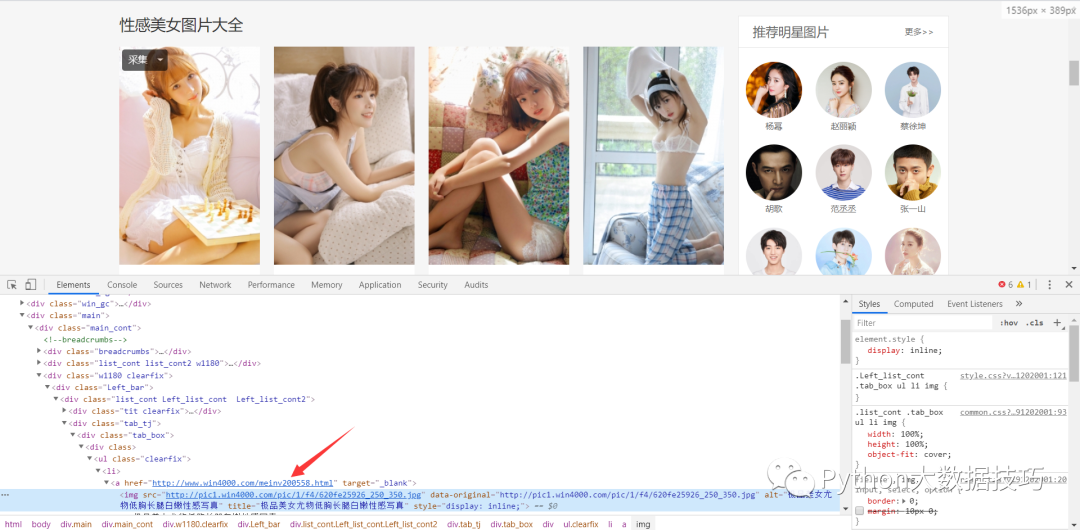
这是链接下的高清图片
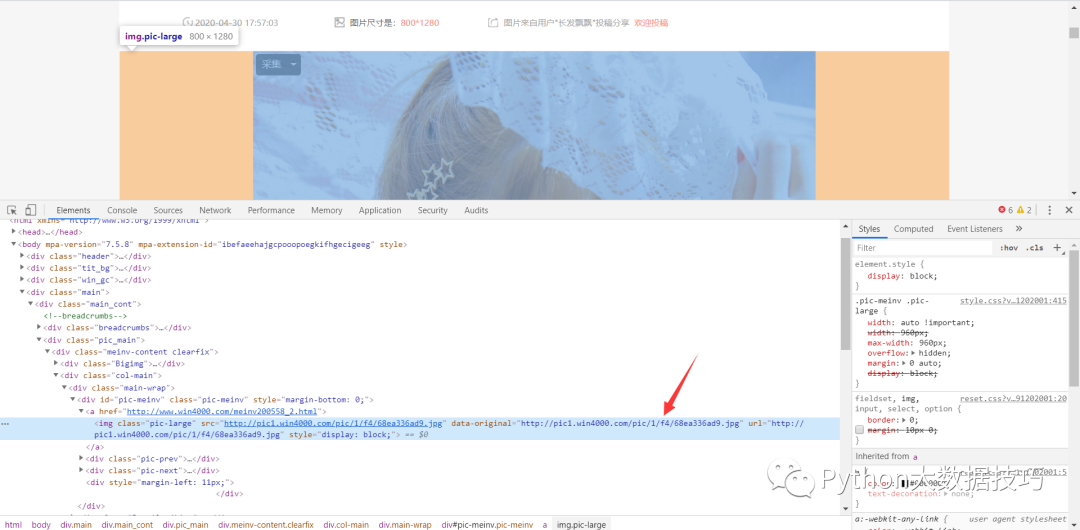
该地址就是我们想要的数据,我们发现data-original就是高清图片地址
03
找到需要下载的链接地址,我们要把所有的高清图片全部下载下来,接下来就是最重要的时刻了,编写代码过程
链接地址:
http://www.win4000.com/meinvtag4_1.html1. 导入requests,lxml模块包
import requestsfrom lxml import etree
2. 确定url地址和请求头
url = "http://www.win4000.com/meinvtag4_1.html"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
什么是请求头
简单来说就是模拟浏览器
User-Agent:浏览器类型,如果Servlet返回的内容与浏览器类型有关则该值非常有用。

3. 请求数据并解析数据
def get_data(imgs):# 解析数据html = etree.HTML(imgs)href_list = html.xpath('//div[@class="Left_bar"]//ul/li/a/@href')for href in href_list:response01 = requests.get(href, headers=headers).texthtml01 = etree.HTML(response01)img_list = html01.xpath('//div[@class="pic-meinv"]/a/img/@data-original')[0]# 请求图片数据img_url = requests.get(img_list, headers=headers).content
这里使用了嵌套循环,因为你访问的是原网页,网页下还有,一个图片专辑那里才是,我们的想要的高清图片,所以要使用嵌套循环
4. 保存数据
def save_data():file_name = img_list.split('/')[-1]with open(r'Q:\xing\img\\' + file_name , mode="wb") as f:print("正在下载图片:" + file_name)f.write(img_url)
img_list.split('/')[-1]就是以下图,图片链接地址后半部分进行分割,来定义为文件名称。
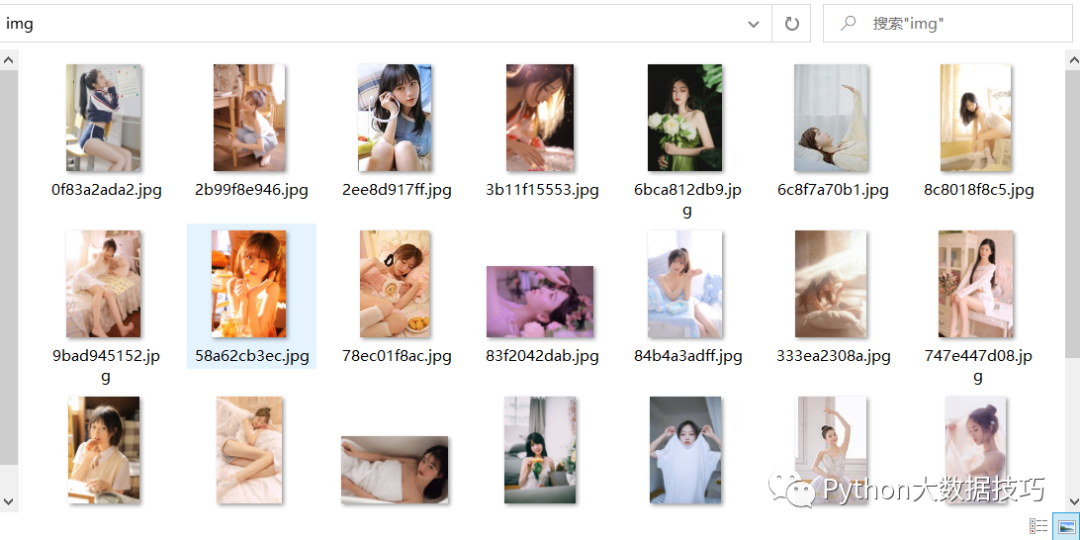
查看我们保存的图片
总结
本文介绍了,在pycharm中安装模块及使用,为什么要用请求头,并分析网页,得到我们想要的图片,提前部署请求头,模拟浏览器,针对反爬虫提前做了准备。
创作不易,欢迎关注
往期精彩,欢迎浏览





