
每日面试之Java集合
共 4445字,需浏览 9分钟
· 2020-11-06
01
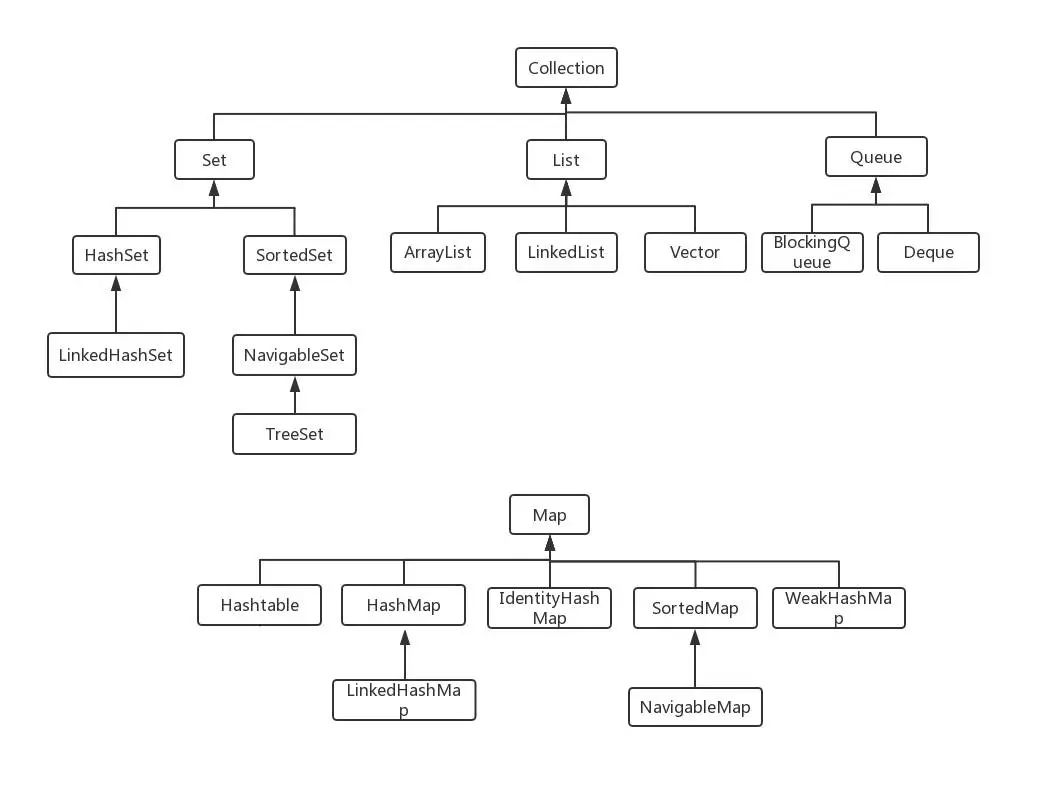
Java 有哪些常用容器(集合) ?
参考答案 Java 容器分为 Collection 和 Map 两大类,各自都有很多子类。
可以比较的点:
有序、无序
可重复、不可重复
键、值是否可为null
底层实现的数据结构(数组、链表、哈希...)
线程安全性
------------------------------------------------------------------------
List:有序集合,元素可重复
Set:不重复集合,LinkedHashSet按照插入排序,SortedSet可排序,HashSet无序
Map:键值对集合,存储键、值和之间的映射;Key无序,唯一;value 不要求有序,允许重复
02
Java 有哪些常用容器(集合) ?
参考答案 相同点:
底层都使用数组实现
功能相同,实现增删改查等操作的方法相似
长度可变的数组结构
不同点:
Vector是早期JDK版本提供,ArrayList是新版本替代Vector的
Vector 的方法都是同步的,线程安全;ArrayList 非线程安全,但性能比Vector好
默认初始化容量都是10,Vector 扩容默认会翻倍,可指定扩容的大小;ArrayList只增加 50%
03
HashMap和Hashtable 有什么区别 ?
参考答案 JDK 1.8 中 HashMap 和 Hashtable 主要区别如下:
线程安全性不同。HashMap线程不安全;Hashtable 中的方法是Synchronize的,线程安全。 key、value是否允许null。HashMap的key和value都是可以是null,key只允许一个null;Hashtable的key和value都不可为null。 迭代器不同。HashMap的Iterator是fail-fast迭代器;Hashtable还使用了enumerator迭代器。 hash的计算方式不同。HashMap计算了hash值;Hashtable使用了key的hashCode方法。 默认初始大小和扩容方式不同。HashMap默认初始大小16,容量必须是2的整数次幂,扩容时将容量变为原来的2倍;Hashtable默认初始大小11,扩容时将容量变为原来的2倍加1。 是否有contains方法。HashMap没有contains方法;Hashtable包含contains方法,类似于containsValue。 父类不同。HashMap继承自AbstractMap;Hashtable继承自Dictionary。 深入的细节,可以参考:
https://www.cnblogs.com/williamjie/p/9099141.html
04
Queue的add()和offer()方法有什么区别 ?
参考答案
队列中的add()和offer()都是向尾部添加一个元素的。
在容量已满的情况下,add()方法会引发IllegalStateException异常,offer()方法只会返回false。
同样地:
队列中remove()和poll()都是从串行头部删除一个元素。
在某种元素为空的情况下,remove()方法会引发NoSuchElementException异常,poll()方法只会返回null。
队列中element()和peek()都是用来返回初始化的头元素,不删除。
在某种元素为空的情况下,element()方法会引发NoSuchElementException异常,peek()方法只会返回null。
05
哪些集合类是线程安全的 ?
参考答案
Vector
Stack
Hashtable
java.util.concurrent 包下所有的集合类 ArrayBlockingQueue、ConcurrentHashMap、ConcurrentLinkedQueue、ConcurrentLinkedDeque...
06
为什么基本类型不能做为HashMap的键值 ?
参考答案
Java中是使用泛型来约束 HashMap 中的key和value的类型的,HashMap
泛型在Java的规定中必须是对象Object类型的,基本数据类型不是Object类型,不能作为键值
map.put(0, "kun")中编译器已将 key 值 0 进行了自动装箱,变为了 Integer 类型
07
Java中已经数组类型,为什么还要提供集合 ?
参考答案 数组的优点:
数组的效率高于集合类
数组能存放基本数据类型和对象;集合中只能放对象
数组的缺点:
不是面向对象的,存在明显的缺陷
数组长度固定且无法动态改变;集合类容量动态改变
数组无法判断其中实际存了多少元素,只能通过length属性获取数组的申明的长度
数组存储的特点是顺序的连续内存;集合的数据结构更丰富
JDK 提供集合的意义:
集合以类的形式存在,符合面向对象,通过简单的方法和属性调用可实现各种复杂操作
集合有多种数据结构,不同类型的集合可适用于不同场合
弥补了数组的一些缺点,比数组更灵活、实用,可提高开发效率
08
说一下HashMap的实现原理 ?
参考答案
HashMap 基于 Hash 算法实现,通过 put(key,value) 存储,get(key) 来获取 value
当传入 key 时,HashMap 会根据 key,调用 hash(Object key) 方法,计算出 hash 值,根据 hash 值将 value 保存在 Node 对象里,Node 对象保存在数组里
当计算出的 hash 值相同时,称之为 hash 冲突,HashMap 的做法是用链表和红黑树存储相同 hash 值的 value
当 hash 冲突的个数:小于等于 8 使用链表;大于 8 时,使用红黑树解决链表查询慢的问题,当红黑树的节点数超过6的时候会变成链表。
ps:
上述是 JDK 1.8 HashMap 的实现原理,并不是每个版本都相同,比如 JDK 1.7 的 HashMap 是基于数组 + 链表实现,所以 hash 冲突时链表的查询效率低
hash(Object key) 方法的具体算法是 (h = key.hashCode()) ^ (h >>> 16),经过这样的运算,让计算的 hash 值分布更均匀
09
ConcurrentHashMap了解吗 ?说说实现原理 ?
参考答案 HashMap 是线程不安全的,效率高;HashTable 是线程安全的,效率低。
ConcurrentHashMap 可以做到既是线程安全的,同时也可以有很高的效率,得益于使用了分段锁
实现原理
JDK 1.7:
ConcurrentHashMap 是通过数组 + 链表实现,由 Segment 数组和 Segment 元素里对应多个 HashEntry 组成
value 和链表都是 volatile 修饰,保证可见性
ConcurrentHashMap 采用了分段锁技术,分段指的就是 Segment 数组,其中 Segment 继承于 ReentrantLock(可重入锁)
理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发,每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment
put 方法的逻辑较复杂:
尝试加锁,加锁失败 scanAndLockForPut 方法自旋,超过 MAX_SCAN_RETRIES 次数,改为阻塞锁获取
将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value
不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容
最后释放所获取当前 Segment 的锁
get 方法较简单:
将 key 通过 hash 之后定位到具体的 Segment,再通过一次 hash 定位到具体的元素上
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了其内存可见性
JDK 1.8:
抛弃了原有的 Segment 分段锁,采用了 CAS + synchronized 来保证并发安全性
HashEntry 改为 Node,作用相同
val next 都用了 volatile 修饰
put 方法逻辑:
根据 key 计算出 hash 值
判断是否需要进行初始化
根据 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋
如果当前位置的 hashcode == MOVED == -1,则需要扩容
如果都不满足,则利用 synchronized 锁写入数据
如果数量大于 TREEIFY_THRESHOLD 则转换为红黑树
get 方法逻辑:
根据计算出来的 hash 值寻址,如果在桶上直接返回值
如果是红黑树,按照树的方式获取值
如果是链表,按链表的方式遍历获取值
JDK 1.7 到 JDK 1.8 中的 ConcurrentHashMap 最大的改动:
链表上的 Node 超过 8 个改为红黑树,查询复杂度 O(logn)
ReentrantLock 显示锁改为 synchronized,说明 JDK 1.8 中 synchronized 锁性能赶上或超过 ReentrantLock
10
List里如何剔除相同的对象 ?
参考答案
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* 测试剔除List的相同元素
* @date 2019-11-06 16:33:17
*/
public class TestRemoveListSameElement {
public static void main(String[] args) {
Listl = Arrays.asList("1", "2", "3", "1");
Sets = new HashSet (l);
System.out.println(s);
}
}
1.微服务实战系列
4.中间件等
更多信息请关注公众号:「软件老王」,关注不迷路,软件老王和他的IT朋友们,分享一些他们的技术见解和生活故事。