 大邓和他的Python
大邓和他的Python




来源:towardsdatascience
作者:Baijayanta Roy
编译&内容补充:早起Python
在用Python进行机器学习或者日常的数据处理中,Pandas是最常用的Python库之一,熟练掌握pandas是每一个数据科学家的必备技能,本文将用代码+图片详解Pandas中的四个实用函数!
shift()
假设我们有一组股票数据,需要对所有的行进行移动,或者获得前一天的股价,又或是计算最近三天的平均股价。
面对这样的需求我们可以选择自己写一个函数完成,但是使用pandas中的shift()可能是最好的选择,它可以将数据按照指定方式进行移动!
下面我们用代码进行演示,首先导入相关库并创建示例DataFrame
import pandas as pd
import numpy as np
df = pd.DataFrame({'DATE': [1, 2, 3, 4, 5],
'VOLUME': [100, 200, 300,400,500],
'PRICE': [214, 234, 253,272,291]})
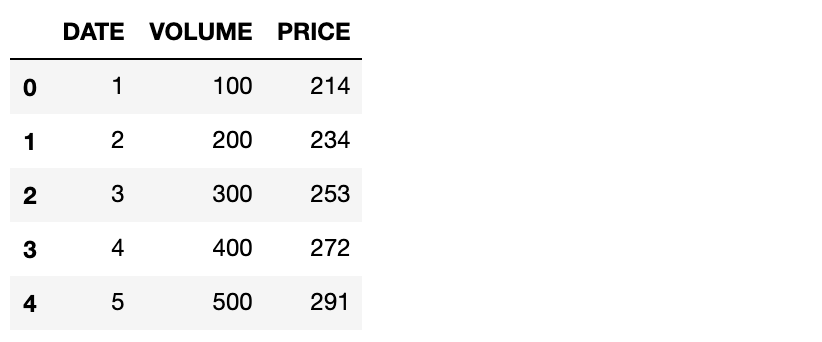
现在,当我们执行df.shift(1,fill_value=0)即可将数据往下移动一行,并用0填充空值
现在,如果我们需要将前一天的股价作为新的列,则可以使用下面的代码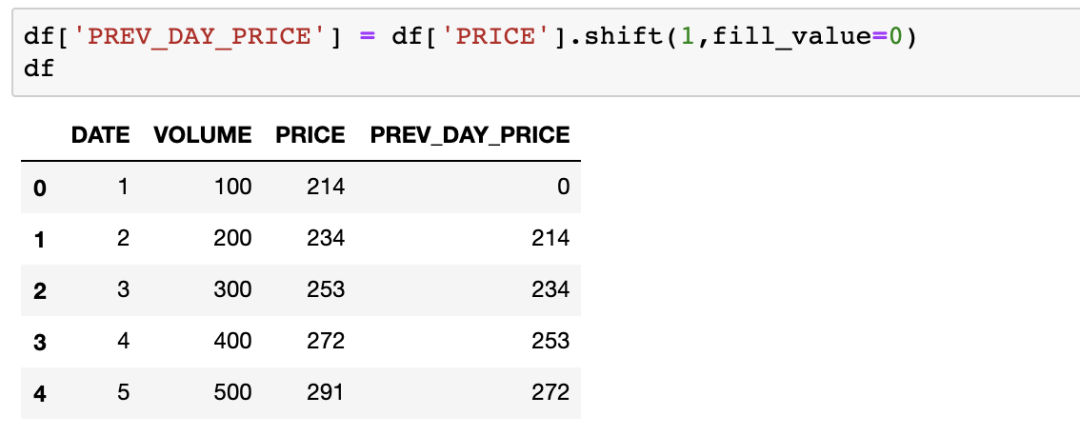
我们可以如下轻松地计算最近三天的平均股价,并创建一个新的列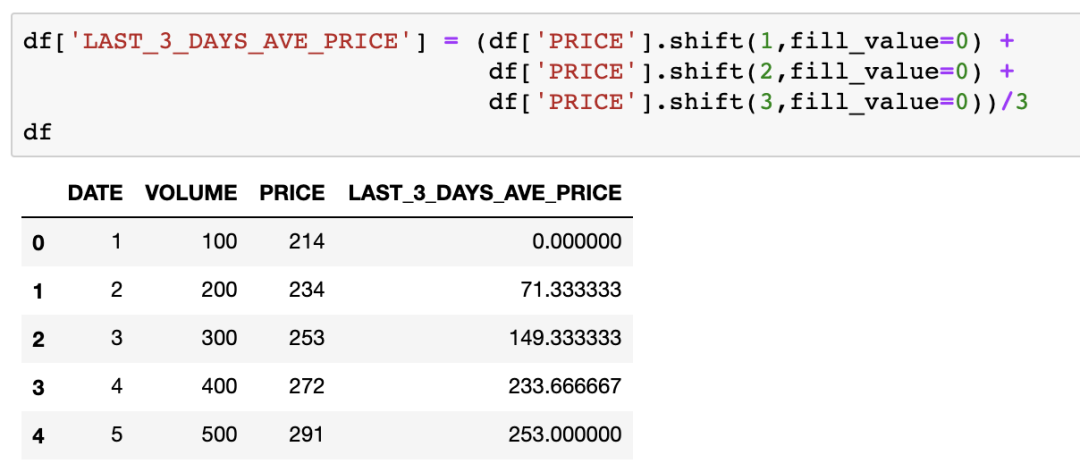
向前移动数据也是很轻松的,使用-1即可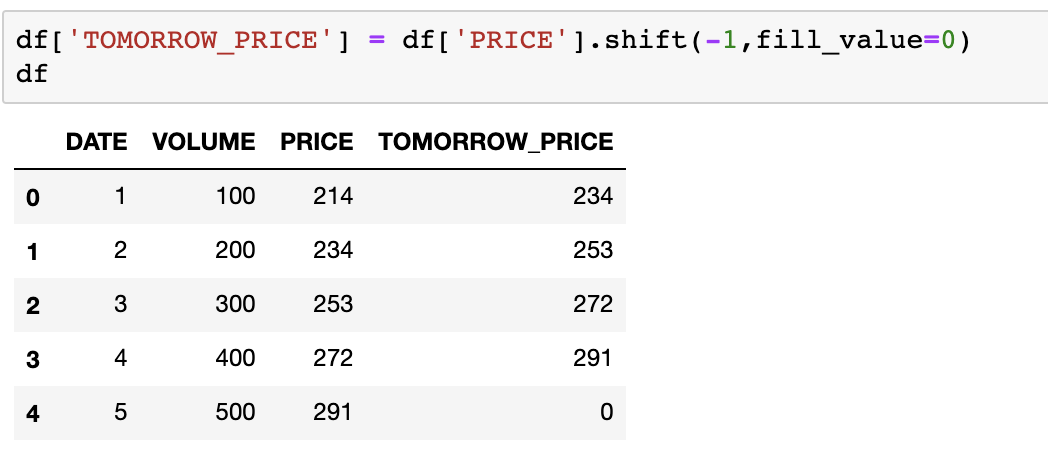
更多有关shift函数可以查阅官方文档,总之在涉及到数据移动时,你需要想到shift!
value_counts()
pandas中的value_counts()用于统计dataframe或series中不同数或字符串出现的次数,并可以通过降序或升序对结果对象进行排序,下图可以方便理解。
现在让我们用代码示例,首先是Index对象
下面是Series对象
同时可以对bin参数将结果划分为区间
更多的细节与参数设置,可以阅读pandas官方文档。
mask()
pandas中的mask方法比较冷门,和np.where比较类似,将对cond条件进行判断,如果cond为False,请保留原始值。如果为True,则用other中的相应值替换。
现在我们看下面的DataFrame,在这里我们要更改所有可以被二整除的元素的符号,就可以使用mask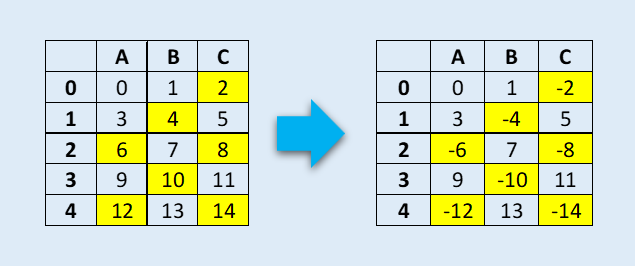
下面是代码实现过程
nlargest()
在很多情况下,我们会遇到需要查找Series或DataFrame的前3名或后5名值的情况,例如,总得分最高的3名学生,或选举中获得的总票数的3名最低候选人
pandas中的nlargest()和nsmallest()是满足此类数据处理要求的最佳答案,下面就是从10个观测值中取最大的三个图解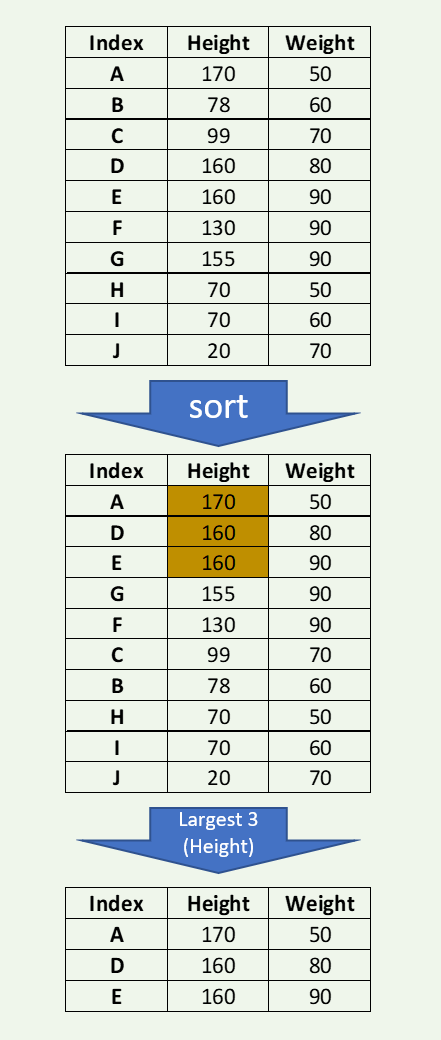
下面是代码实现过程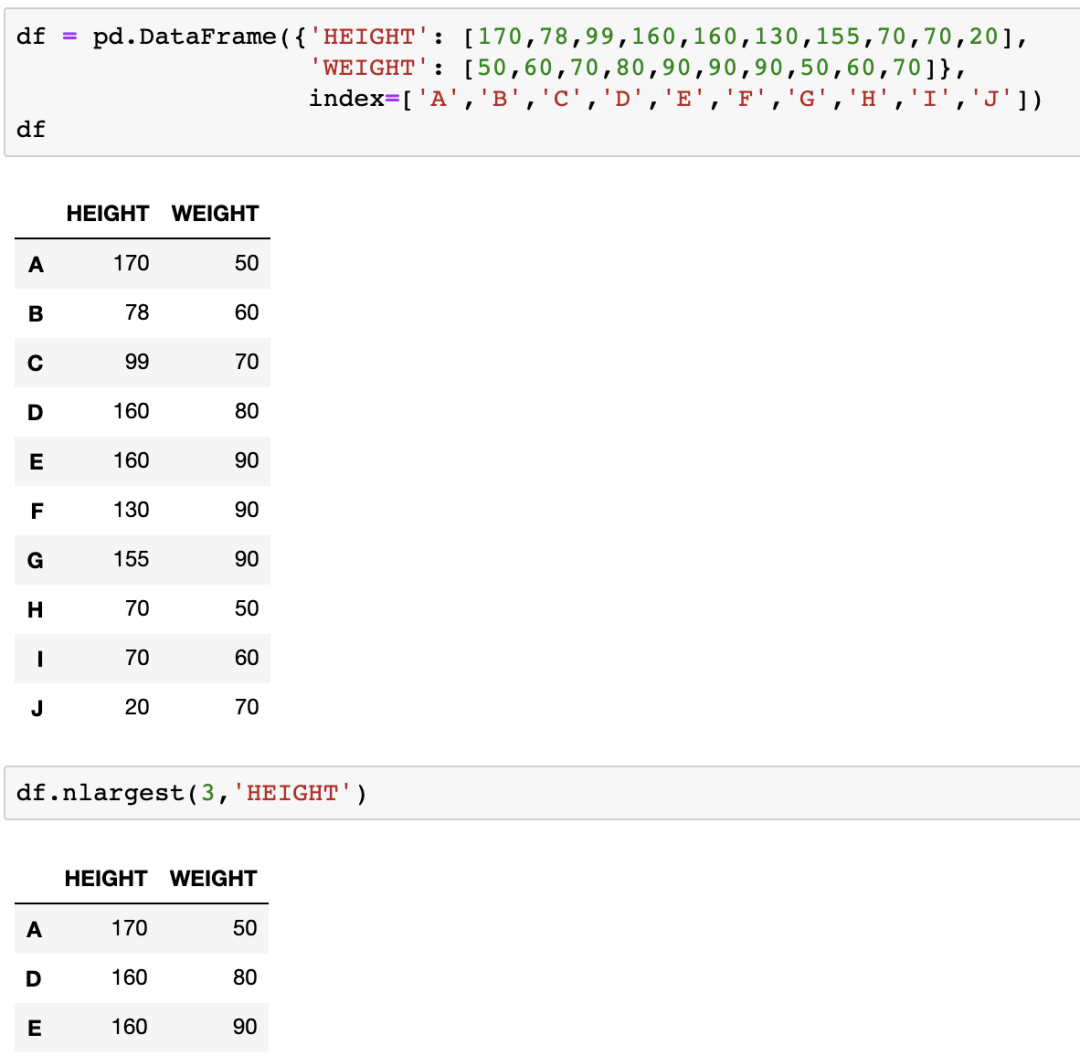
但如果有相等的情况出现,那么可以使用first,last,all来进行保留
了解了nlargest()的使用方法后,nsmallest()就显得十分简单,本文就不再赘述,如果还有疑问可以查阅官方文档!
近期文章
Python网络爬虫与文本数据分析 bsite库 | 采集B站视频信息、评论数据 rpy2库 | 在jupyter中调用R语言代码 tidytext | 耳目一新的R-style文本分析库 reticulate包 | 在Rmarkdown中调用Python代码 plydata库 | 数据操作管道操作符>> plotnine: Python版的ggplot2作图库 七夕礼物 | 全网最火的钉子绕线图制作教程 读完本文你就了解什么是文本分析 文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用 plotnine: Python版的ggplot2作图库 小案例: Pandas的apply方法 stylecloud:简洁易用的词云库 用Python绘制近20年地方财政收入变迁史视频 Wow~70G上市公司定期报告数据集 漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G

