
PyTorch Lightning 1.0 正式发布!从0到1,有这9大特点

极市导读
PyTorch可以构建复杂的AI模型,但一旦研究变得复杂,就很可能会引入错误。PyTorch Lightning完全解决了这个问题。本文译自Pytorch官方团队,介绍了PyTorch Lightning V1.0.0的九大特点。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
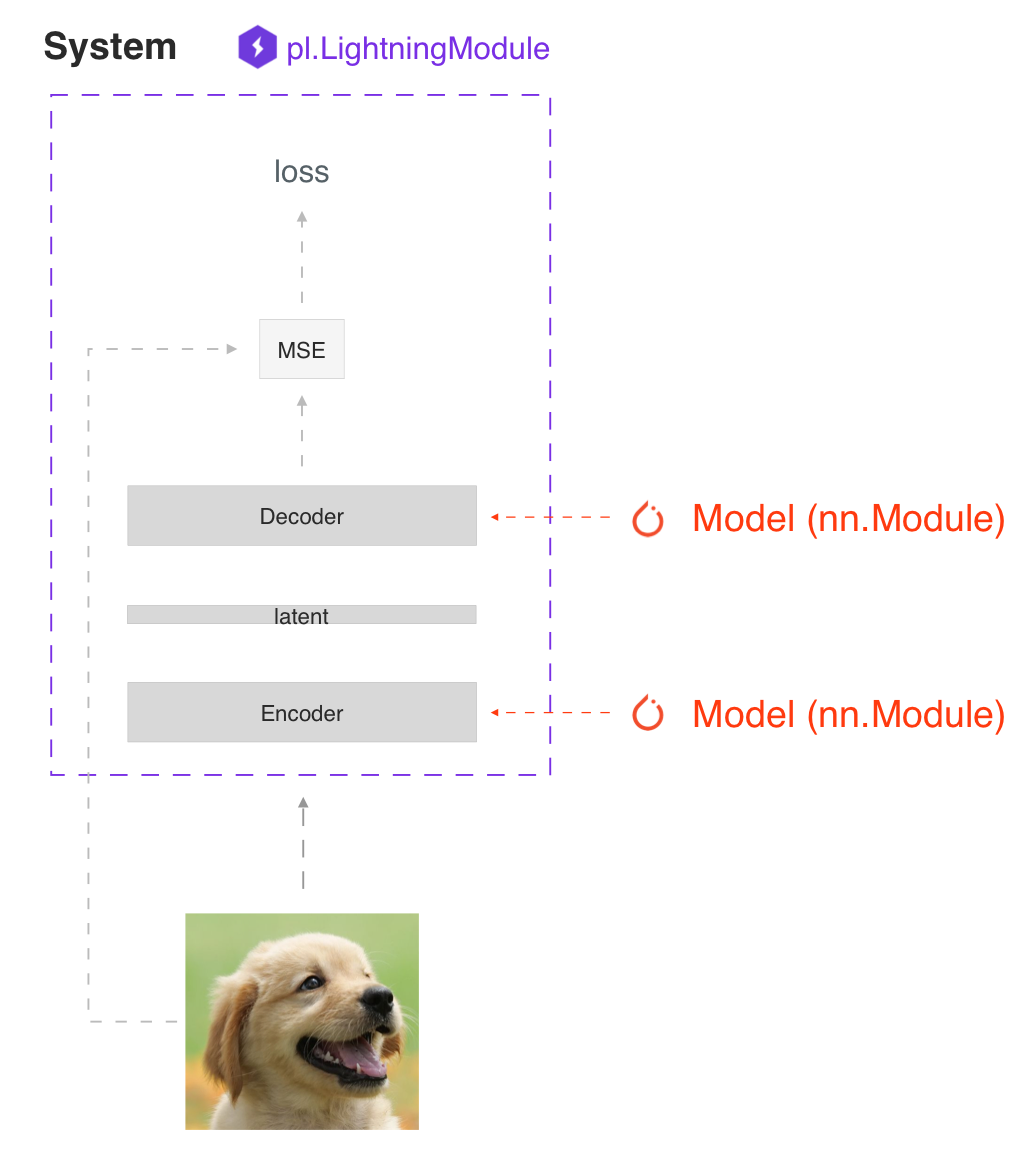
Lightning DNA
Lightning DNA

1.0.0的新功能
1.0.0的新功能
研究 + 生产
研究 + 生产
# ----------------------------------# torchscript# ----------------------------------autoencoder = LitAutoEncoder()torch.jit.save(autoencoder.to_torchscript(), "model.pt")os.path.isfile("model.pt")# ----------------------------------# onnx# ----------------------------------with tempfile.NamedTemporaryFile(suffix='.onnx', delete=False) as tmpfile:autoencoder = LitAutoEncoder()input_sample = torch.randn((1, 28 * 28))autoencoder.to_onnx(tmpfile.name, input_sample, export_params=True)os.path.isfile(tmpfile.name)
网站
网站
度量(Metrics)
度量(Metrics)
class LitModel(pl.LightningModule):def __init__(self):...self.train_acc = pl.metrics.Accuracy()self.valid_acc = pl.metrics.Accuracy()def training_step(self, batch, batch_idx):logits = self(x)...self.train_acc(logits, y)# log step metricself.log('train_acc_step', self.train_acc)def validation_step(self, batch, batch_idx):logits = self(x)...self.valid_acc(logits, y)# logs epoch metricsself.log('valid_acc', self.valid_acc)
from pytorch_lightning.metrics import Metricclass MyAccuracy(Metric):def __init__(self, dist_sync_on_step=False):super().__init__(dist_sync_on_step=dist_sync_on_step)self.add_state("correct", default=torch.tensor(0), dist_reduce_fx="sum")self.add_state("total", default=torch.tensor(0), dist_reduce_fx="sum")def update(self, preds: torch.Tensor, target: torch.Tensor):preds, target = self._input_format(preds, target)assert preds.shape == target.shapeself.correct += torch.sum(preds == target)self.total += target.numel()def compute(self):return self.correct.float() / self.total
手动优化与自动优化
手动优化与自动优化
def training_step(self, batch, batch_idx):loss = self.encoder(batch[0])return loss
trainer = Trainer(automatic_optimization=False)from pytorch_lightning.metrics import Metricclass MyAccuracy(Metric):def __init__(self, dist_sync_on_step=False):super().__init__(dist_sync_on_step=dist_sync_on_step)self.add_state("correct", default=torch.tensor(0), dist_reduce_fx="sum")self.add_state("total", default=torch.tensor(0), dist_reduce_fx="sum")def update(self, preds: torch.Tensor, target: torch.Tensor):preds, target = self._input_format(preds, target)assert preds.shape == target.shapeself.correct += torch.sum(preds == target)self.total += target.numel()def compute(self):return self.correct.float() / self.total
日志(Logging)
日志(Logging)
def training_step(self, batch, batch_idx):self.log('my_metric', x)
def training_step(self, batch, batch_idx):self.log('my_loss', loss, on_step=True, on_epoch=True, prog_bar=True, logger=True)
数据流
x_step
x_step_end
x_epoch_end
outs = []for batch in data:out = training_step(batch)outs.append(out)training_epoch_end(outs)
def training_step(self, batch, batch_idx):prediction = …return {'loss': loss, 'preds': prediction}def training_epoch_end(self, training_step_outputs):for out in training_step_outputs:prediction = out['preds']# do something with these
Checkpointing
Checkpointing
计算你希望监控的任何指标或其他数量,例如验证集损失。
使用 log() 方法记录数量,并用一个键如 val_loss。
初始化 ModelCheckpoint 回调,并设置监视器为你的数量的键。
回调传递给 checkpoint_callback Trainer flag。
from pytorch_lightning.callbacks import ModelCheckpointclass LitAutoEncoder(pl.LightningModule):def validation_step(self, batch, batch_idx):x, y = batchy_hat = self.backbone(x)# 1. calculate lossloss = F.cross_entropy(y_hat, y)# 2. log `val_loss`self.log('val_loss', loss)# 3. Init ModelCheckpoint callback, monitoring 'val_loss'checkpoint_callback = ModelCheckpoint(monitor='val_loss')# 4. Pass your callback to checkpoint_callback trainer flagtrainer = Trainer(checkpoint_callback=checkpoint_callback)
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!

评论