
全球AI芯片技术选型:云端推理篇
共 3717字,需浏览 8分钟
· 2020-09-26


第四部分:终端计算芯片
一、云端推理芯片
1、赛灵思Alveo
赛灵思 Alveo数据中心加速器卡专为现代数据中心多样的应用需求而设计。赛灵思推出的Vitis 统一软件平台为各类软件和AI 推理应用开发提供统一编程模型,实现从C/C++、Python、Caffe、Tensorflow 到差异化应用落地的开发过程。
赛灵思Alveo 数据中心加速器卡基于Xilinx16nm UltraScale 架构,使用赛灵思堆叠硅片互联(SSI) 技术来实现FPGA 容量、带宽和功耗效率,通过结合多个超逻辑区域(SLR) 来增大密度。Alveo 加速卡旨在加速服务器或工作站中的机器学习、数据分析和视频处理等计算密集型应用。
AlveoU50 卡采用 XCU50 FPGA 包括 2个 SLR,配备PCIe Gen4 和 8G HBM2,每秒100G 网络连接,以高效能 75 瓦、小尺寸形式为金融计算、机器学习、计算存储以及数据搜索与分析工作负载提供优化加速。
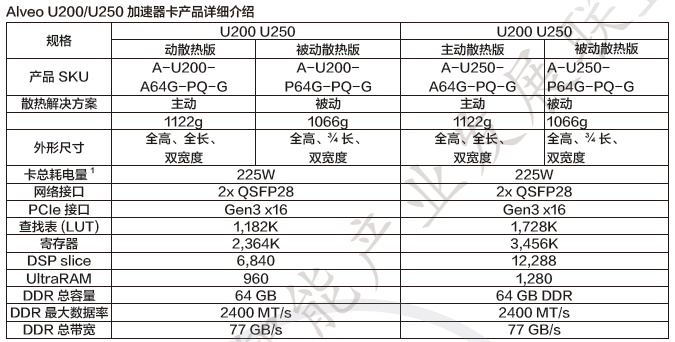
Alveo U200 卡采用XCU200 FPGA 包括 3个 SLR,Alveo U250 卡使用XCU250 FPGA 包括 4 个 SLR。二者均可连接到PCI Express 的16 个通道,最高运行速度8GT/s(Gen3),也可以连接到 4 根 DDR4 16 GB 2400 MT/s 64 位含纠错码 (ECC) 的 DIMM,总计64 GB 的DDR4。
ALveo U280 加速卡采用XCU280 包括三个SLR,底部 SLR (SLR0) 集成一个 HBM 控制器,与相邻的 8 GB HBM2 内存接口连接。底部 SLR还连接到 PCI Express 的 16 个通道,这些通道可以最高 16 GT/s (Gen4) 的速度运行。SLR0和 SLR1 都连接到 DDR4 16 GB 2400 MT/s 64位含纠错码 (ECC) 的 DIMM, 总计 32 GB 的DDR4。
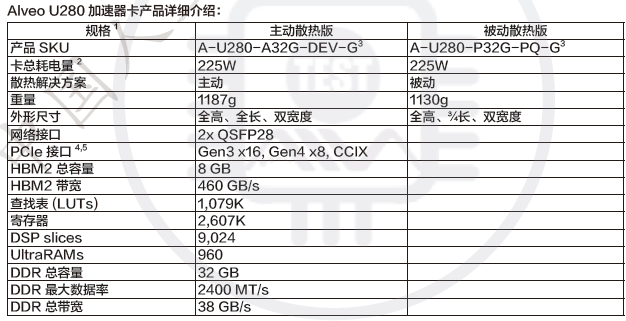
Alveo U280 数据中心加速器卡专为计算和存储工作负载而设计,拥有 8GB HBM2 + 32GBDDR4 内存、1.1M LUT、8.5k DSP 片、每秒100G 双网络连接,并支持第四代 PCIe 和 CCIX 互联标准。
2、寒武纪思元100/270
思元100为云端推理提供运算能力支撑。INT8 算力32TOPS, 内置硬件编解码引擎,应用于计算机视觉、语音识别、自然语言处理。
1.通用智能,支持计算机视觉、语音识别、自然语言处理等多模态智能处理;
2.针对深度学习定制的指令集和处理器架构,具有更优的能效比;
3.完善软件开发环境NeuWare,包括应用开发、功能调试、性能调优等。

思元270为高能效比AI 推理设计的数据中心级PCIe智能加速卡。支持多种精度,比上一代加速芯片计算能力提高4 倍,INT8 算力128TOPS。

广泛支持视觉、语音、自然语言处理以及传统机器学习等高度多样化的人工智能应用,帮助AI推理平台实现高能效比。
1.支持INT16、INT8、INT4、FP32、FP16 多种精度;
2.内置视频和图片编解码器,有效降低CPU 前处理负载和PCIe 带宽占用;
3.计算弹性,支持多类神经网络,寒武纪Neuware 软件栈部署推理环境;
4.可编程,基于Bang 语言编程环境可对计算资源定制,满足多样化需求。
3、比特大陆算丰TPU芯片BM1684
BM1684 是比特大陆面向深度学习领域自主研发的第三代张量处理器(TPU),是聚焦视频图像分析的云端及边缘的人工智能推理芯片。
1. 芯片:BM1684 聚焦视频图像分析,是云端及边缘的人工智能推理芯片;
2. AI 算力:17.6TOPS INT8,Winograd 卷积加速下最高可达35.2TOPS,实测推理性能较上一代提升约5 倍以上;
3. AI 架构:本芯片基于自主研发的TPU 架构;
4. 典型功耗:16W;
5. 视频解码:支持H264/H265 解码,最大分辨率8192x8192,支持4K/8K。H264 和H265 解码都支持32 路高清30FPS @1080P,可处理数十路视频智能分析全流程;
6. 图像解码:支持JPEG 解码和编码,均可支持480 张/秒@1080P;
7. CPU:八核A53,主频2.3GHz;
8. 内存:LPDDR4X,带宽68.3GB/s;
9. AI 框架支持:Caffe, Tensorflow, PyTorch,MXNet,PaddlePaddle 飞桨等;

BM1684 芯片技术特点是:
1)TPU 芯片架构自主研发,相关专利申请达到270 项以上;
2)性能功耗比高,在16W 情况下,最高可达到35.2T 性能(Winograd 加速);
3)视频解码路数多,支持32 路H264和H265 高清30FPS @1080P 硬解码;
4)视频全流程处理能力强,可达到16~32 路典型视频结构化/ 人脸分析路数;
5)AI 工具链完备,Caffe, Tensorflow、PyTorch,MXNet,PaddlePaddle 都支持;
6)部署场景灵活,云端和边缘均可部署;
7)使用灵活,可工作于PCIE 从设备模式或者SOC 主设备模式;
星空X3加速卡为鲲云推出的面向边缘端和数据中心进行深度学习推断的AI 计算加速卡,搭载鲲云自研的定制数据流CAISA 芯片,采用无指令集的架构方式,为支持深度学习的边缘和数据中心服务器提供计算加速方案。
1.支持 ResNet、VGG、YOLO 等多个主流CNN 算法模型
2. 提供RainBuilder 编译工具链,支持端到端算法开发和部署
3. 支持 TensorFlow、Caffe 、PyTorch 及ONNX (MXNet) 等主流深度学习框架开发的算法模型
4. 其宣称芯片利用率可达95.4%
鲲云与合作方通过研究适用于电力无人机巡检的目标检测深度学习算法,实现基于人工智能技术的电力无人机智能巡检、数据采集,并在服务器端进行高质量的图片数据分析,提高巡检效率,降低巡检工作量。
1 其宣称芯片利用率可达95.4%;
2 时延:3ms 分类延时;
3 支持分类、目标检测以及语义分割类深度学习算法;
4 Batch size 不敏感;
5 温度范围:-20℃ ~70℃
6 实测Benchmark:


5、昇腾310AI 处理器
昇腾AI 处理器的主要架构组成:
■ 芯片系统控制CPU(Control CPU)
■ AI 计算引擎(包括AI Core 和AI CPU)
■ 多层级的片上系统缓存(Cache)或缓冲区(Buffer)
■ 数字视觉预处理模块(Digital Vision Pre-Processing,DVPP)等
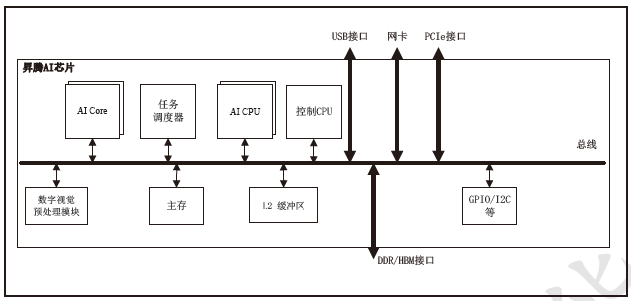
华为针对其昇腾AI 芯片的计算架构专门构建了完整的软件栈,兼容各个深度学习框架并能够高效运行在昇腾AI 芯片上,让开发者能够快速开发推理应用,为开发者提供便利的解决方案。当前主流的深度学习应用,包括图像分类、人脸识别、目标检测、光学字符识别、视频处理和自然语言处理领域的各个模型,均可以在昇腾310 处理器上得到很好的技术支持。

达芬奇架构主要由计算单元、存储系统和控制单元三部分构成。其中计算单元又分为:矩阵计算单元、向量计算单元、标量计算单元,分别对应矩阵、向量和标量三种常见的计算模式。
■ 矩阵计算单元(Cube Unit):
矩阵计算单元和累加器主要完成矩阵相关运算。一拍完成一个FP16 的 16x16 与16x16 矩阵乘(4096);如果是INT8 输入,则一拍完成16*32 与 32*16 矩阵乘(8192);
实现向量和标量,或双向量之间的计算,功能覆盖各种基本的计算类型和许多定制的计算类型,主要包括FP16/FP32/INT32/INT8 等数据类型的计算;
相当于一个微型CPU,控制整个AI Core 的运行,完成整个程序的循环控制、分支判断,可以为Cube/Vector提供数据地址和相关参数的计算,以及基本的算术运算。

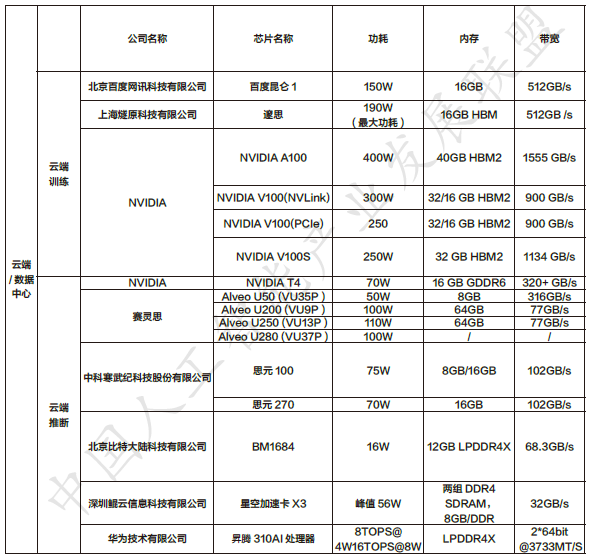
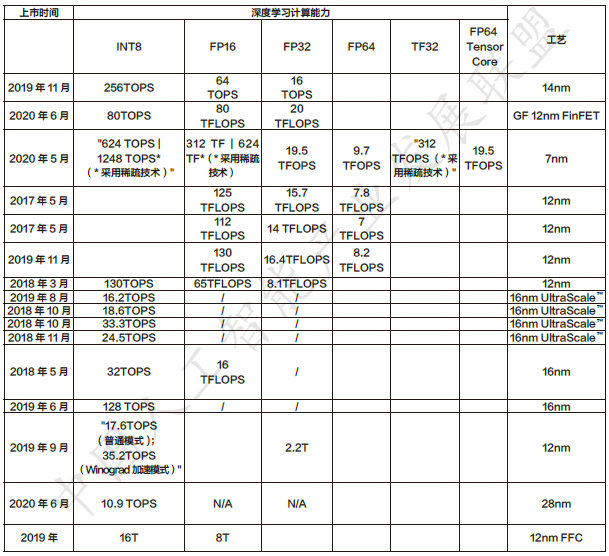
数据中心云端训练、云端推理芯片总结:
下载方式:关注微信,回复“全球AI选型”关键字,获取全文下载地址。
申明:感谢原创作者的辛勤付出。本号转载的文章均会在文中注明,若遇到版权问题请联系我们处理。
推荐阅读
更多架构相关技术知识总结请参考“架构师技术全联盟书店”相关电子书(32本技术资料打包汇总详情可通过“阅读原文”获取)。
内容持续更新,现在下单“架构师技术全店打包汇总(全)”,后续可享全店内容更新“免费”赠阅,疫情活动期间价格仅168元(原总价240元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
