你的神经网络会忘了学到的东西?
极市平台
共 5844字,需浏览 12分钟
· 2020-09-25

极市导读
本文主要介绍了正则化、重播、提醒、双层持续学习等4种可用于对抗神经网络灾难性遗忘问题的策略,并提出了一个新的研究方向——在更真实的流场景下,训练实例流有可变分布的在线学习。>>加入极市CV技术交流群,走在计算机视觉的最前沿

什么是灾难性遗忘(Catastrophic Forgetting)?
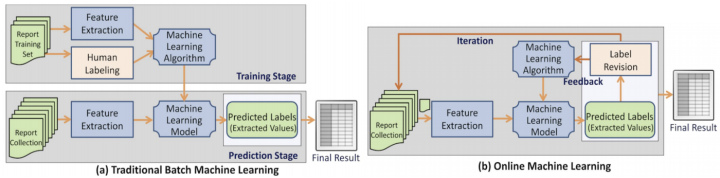

记忆的策略
正则化(Regularization)
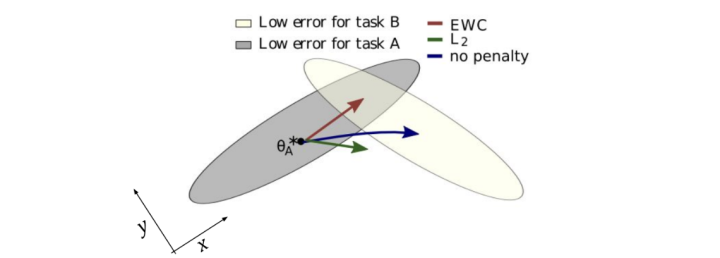
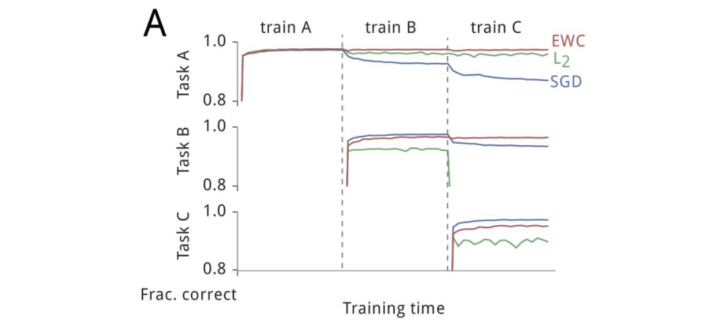
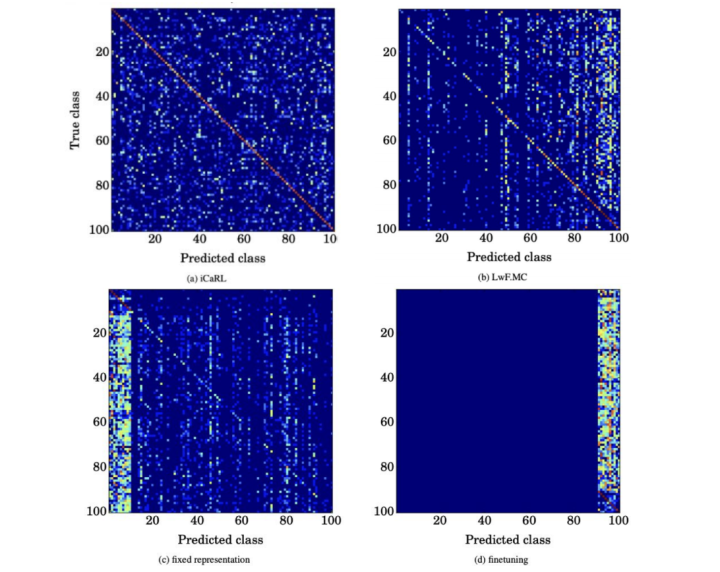
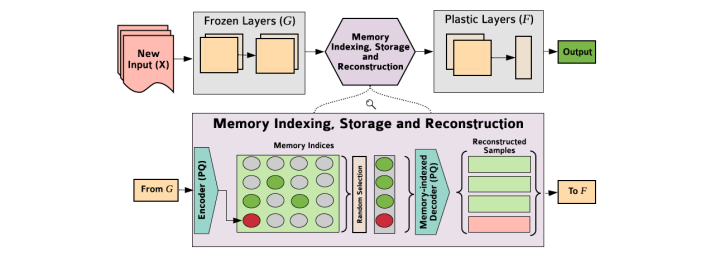
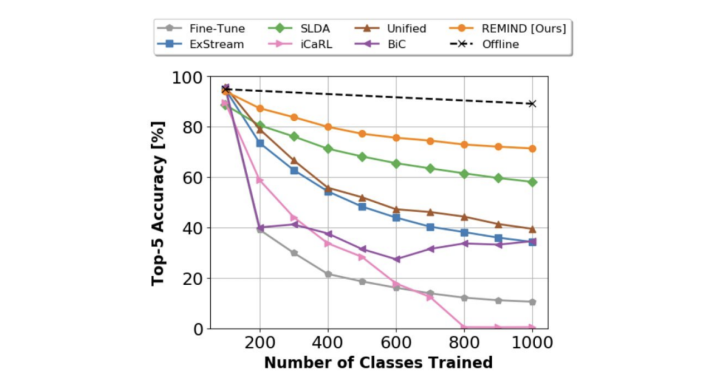
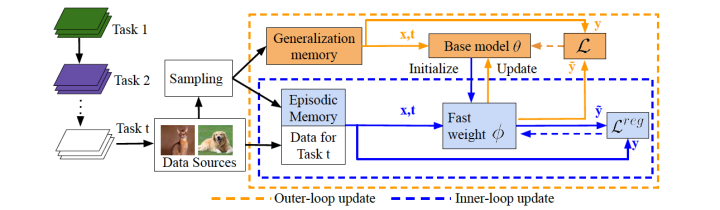
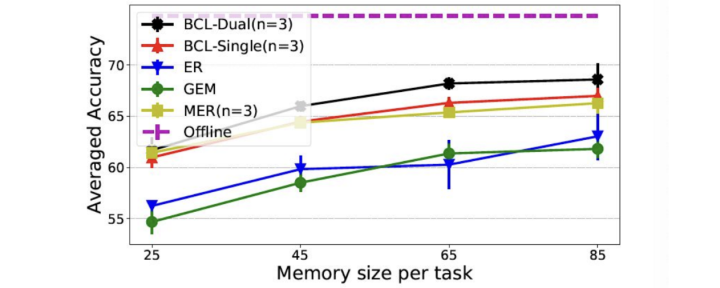
总结
推荐阅读

评论

共 5844字,需浏览 12分钟
· 2020-09-25
极市导读
本文主要介绍了正则化、重播、提醒、双层持续学习等4种可用于对抗神经网络灾难性遗忘问题的策略,并提出了一个新的研究方向——在更真实的流场景下,训练实例流有可变分布的在线学习。>>加入极市CV技术交流群,走在计算机视觉的最前沿
推荐阅读