
史上最火 ECCV 已开幕,这些论文都太有意思了
共 5358字,需浏览 11分钟
· 2020-08-27
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
By 超神经
来源:HyperAI超神经
内容提要:计算机视觉领域三大国际顶级会议之一的 ECCV 2020,于 8 月 23 日至 27 日在线召开。今年 ECCV 共接受论文 1361 篇,我们从中筛选出了 15 篇最受关注的论文,与读者分享。
关键词:ECCV 2020 精选论文
受疫情影响,今年 ECCV 2020 和其它顶会一样,由线下转至线上举办,已于 8 月 23 日拉开了帷幕。

23 日主要为工作坊与教程,主议程于 24 日开始
ECCV,全称 European Conference on Computer Vision(欧洲计算机视觉国际会议) ,是计算机视觉三大国际顶级会议之一(另外两大顶会为 CVPR 和 ICCV),每两年举办一次。
虽然今年的疫情打乱了人们的很多计划,但是大家对科研以及论文投稿的热情却依然有增无减。据统计,ECCV 2020 共收到有效投稿 5025 篇,是上一届(2018 年)投稿量的两倍还多,因此被认为是「史上最火 ECCV」。
最终被接收发表论文 1361 篇,接收率为 27%。在接收论文中,oral 的论文数为 104 篇,占有效投稿总数的 2%,spotlight 的数目为 161 篇,比例约为 3%。其余论文为 poster。
姿态估计、3D 点云,优秀论文一览
这场计算机视觉领域的盛会,今年为我们带来了哪些精彩研究成果?
我们从入选论文中,精选出 15 篇,分别涉及 3D 目标检测、姿态估计、图像分类、人脸识别等多个方向。
行人重识别 《请别打扰我:
在其他行人干扰下的行人重识别》

单位:华中科技大学,中山大学,腾讯优图实验室
摘要:
传统的行人重识别假设裁剪的图像只包含单人。然而,在拥挤的场景中,现成的检测器可能会生成多人的边界框,并且其中背景行人占很大比例,或者存在人体遮挡。
从这些带有行人干扰的图像中提取的特征可能包含干扰信息,这将导致错误的检索结果。
为了解决这一问题,本文提出了一种新的深层网络(PISNet)。PISNet 首先利用 Query 图片引导的注意力模块来增强图片中目标的特征。
此外,我们提出了反向注意模块和多人分离损失函数促进了注意力模块来抑制其他行人的干扰。我们的方法在两个新的行人干扰数据集上进行了评估,结果表明,该方法优于现有的 Re-ID 方法。

论文地址:https://arxiv.org/pdf/2008.06963
姿态估计 《在拥挤场景中基于
多视点几何的对多人三维姿态估计》

单位:约翰斯·霍普金斯大学,新加坡国立大学
摘要:
外极约束是目前多机三维人体姿态估计方法中特征匹配和深度估计的核心问题。尽管该公式在稀疏人群场景中的表现令人满意,但在密集人群场景中,其有效性经常受到挑战,主要是由于两个来源的模糊性。
首先是由于关节和对极线之间的欧几里得距离所提供的简单线索而导致的人类关节不匹配。第二个问题是,由于天真地将问题最小化为最小平方,因此缺乏鲁棒性。
在本文中,我们脱离了多人三维姿态估计公式,将其重新定义为人群姿态估计。我们的方法包括两个关键部分:一个用于快速跨视图匹配的图模型和一个用于三维人体姿态重建的最大后验(MAP)估计器。我们在四个基准数据集上证明了该方法的有效性和优越性。

论文地址:https://arxiv.org/pdf/2007.10986
描述图像 《基于场景图分解的自然语言描述生成》

单位:腾讯 AI Lab,威斯康星大学麦迪逊分校
摘要:
本文提出了一种基于场景图分解的自然语言描述生成方法。
使用自然语言来描述图像是一项颇具挑战性的任务,本文通过重新回顾图像场景图表达,提出了一种基于场景图分解的图像自然语言描述生成方法。该方法的核心是把一张图片对应的场景图分解成多个子图,其中每个子图对应描述图像的一部分内容或一部分区域。通过神经网络选择重要的子图来生成一个描述图像的完整句子,该方法可以生成准确、多样化、可控的自然语言描述。研究者也进行了广泛的实验,实验结果展现了这一新模型的优势。
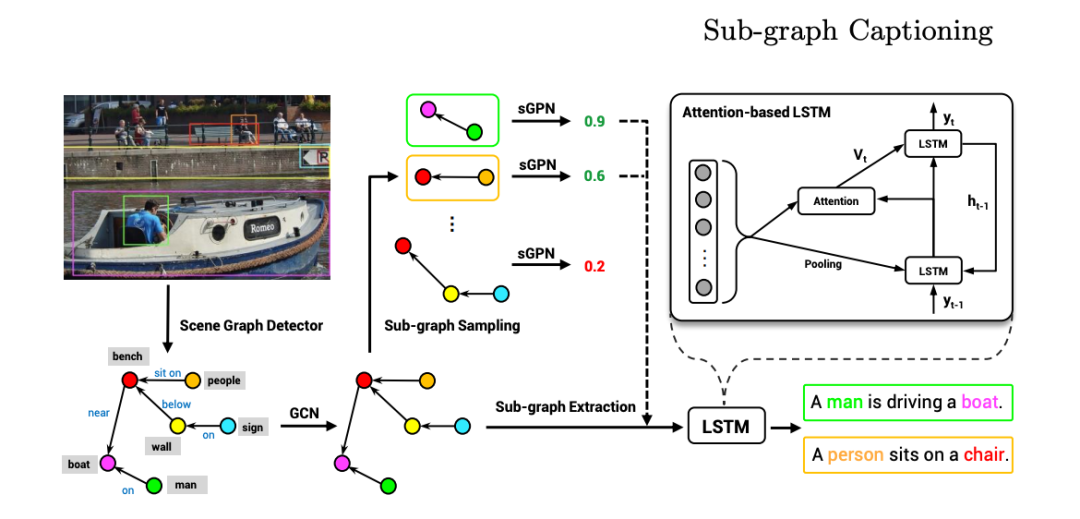
论文地址:https://arxiv.org/abs/2007.11731
3D 点云 《用于 3D 点云的四元数等变胶囊网络》

单位:斯坦福大学,多特蒙德工业大学,帕多瓦大学
摘要:
我们提出了一种处理点云的三维胶囊架构,它与无序输入集的 SO(3)旋转组、平移和排列等价。
该网络在局部参考帧的稀疏集上运行,该局部参考帧是从输入点云计算而来的。该网络通过一种新的三维四元数群胶囊层建立端到端方差,其中包括一种等方差动态路由过程。
胶囊层使我们能够从姿势中解开几何图形,为获得更多信息描述和结构化的潜在空间铺平了道路。在此过程中,我们从理论上将胶囊之间的动态路由过程与著名的 Weiszfeld 算法联系起来,该解决方案用于解决具有可证明的收敛特性的迭代重加权最小二乘(IRLS)问题,从而实现了胶囊层间鲁棒姿态估计。
由于稀疏的等变四元数胶囊,我们的体系结构允许进行联合对象分类和方向估计,我们可以在常见基准数据集上进行实证验证。
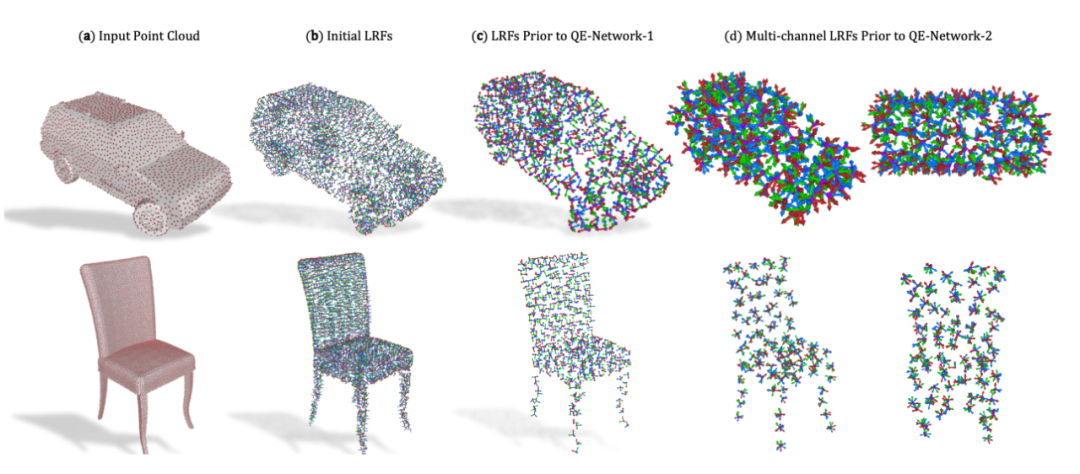
论文地址:https://arxiv.org/pdf/1912.12098.pdf
人脸识别 《可解释的人脸识别》

单位:Systems & Technology Research, Visym Labs
摘要:
可解释的人脸识别(简称 XFR)是一个解释人脸匹配器返回的匹配结果的问题,以便深入了解为什么一个探测器会匹配一个身份而不是另一个身份。了解该原理,能够帮助人们去信任和解释人脸识别。
在本文中,我们提供了第一个全面的基准和基线评估 XFR。我们定义了一种新的评估方案,叫做「修复游戏」(inpainting game),它是一套由 95 个受试者组成的 3648 个 triplets(probe, mate, nonmate)的精选集合,通过对选定的面部特征(如鼻子、眉毛或嘴)进行合成修复,从而创造出一个被修补的 nonmate。
XFR 算法的任务是生成一个网络注意力图,该图可以最好地指出 probe 图像中哪些区域与配对的图像相匹配,而不是与每个 triplet 被修复的未匹配的区域。这为量化哪些图像区域有助于人脸匹配提供了依据。
最后,我们在此数据集上提供了一个全面的基准,在三个面部匹配器上,比较了五种最先进的算法。这一基准测试包括两种新的算法,分别称为子树 EBP和基于密度的输入采样解释(DISE),它们的性能远远优于现有的最先进的技术。
我们还在新颖的图像上显示了这些网络注意力技术的定性可视化,并探讨了这些可解释的人脸识别模型如何提高人脸匹配者的透明度和信任度。

论文地址:https://arxiv.org/pdf/2008.00916
年龄估计 《寿命年龄转化合成》

单位:华盛顿大学,斯坦福大学,Adobe Research
摘要:
我们解决了单张照片年龄的递进和回归问题——预测一个人在未来或过去的样子。
现有的老化方法大多局限于改变纹理,忽略了人类老化和生长过程中头部形状的变化。这就限制了以前的方法对年龄稍大的成年人的适用性,而这些方法对儿童照片的应用并不能产生高质量的结果。
我们提出了一种新的多领域图像对图像生成对抗网络结构,其学习的潜在空间模拟了一个持续的双向老化过程。网络在 FFHQ 数据集上进行训练,我们根据年龄、性别和语义分割对其进行标记。使用固定年龄类作为锚点来近似连续年龄变换。我们的框架可以仅根据一张照片,预测出完整的 0-70 岁的头像,并修改纹理和头部的形状。我们在各种各样的照片和数据集上展示了结果,并显示了在技术水平上的显著改进。

论文地址:https://arxiv.org/abs/2003.09764
传送门:论文、代码,通通一键即达
以上只是 ECCV 2020 上千篇入选论文中的冰山一角,但是面对 1361 篇海量论文,想要找到自己感兴趣的论文以及原文链接、代码等,着实不是件轻松的事情。
不过,一个叫做 Paper Digest Team 的团队,已经为广大读者铺好了路,找论文、找代码都不再是问题。
该团队最近发布了一份《一句话点评 ECCV 2020 论文亮点》的总结,对每篇论文都只用一句话进行了总结,言简意赅,并且都附上了论文地址,让读者快速找到自己最想读的论文。

内容中包括了论文标题、地址、作者和亮点总结
地址拿走不谢:
https://www.paperdigest.org/wp-content/uploads/2020/08/ECCV-2020-Paper-Digests.pdf
此外,他们还贴心地将 170 篇公布了代码的论文做了整理,读者可直接点击相应链接查看代码:
https://www.paperdigest.org/2020/08/eccv-2020-papers-with-code-data/
另外,crossminds.ai 还将 oral 论文的演示文稿整理出来,读者能够通过其 demo 演示,更加清晰、直观地了解论文中的技术,非常有趣:
https://crossminds.ai/category/eccv%202020/
下载1:动手学深度学习
在「AI算法与图像处理」公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
