
语义分割之dice loss深度分析
作者:皮特潘
编辑: 致新
dice loss 来自文章VNet(V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation),旨在应对语义分割中正负样本强烈不平衡的场景。本文通过理论推导和实验验证的方式对dice loss进行解析,帮助大家去更好的理解和使用。
dice loss 定义
dice loss 来自 dice coefficient,是一种用于评估两个样本的相似性的度量函数,取值范围在0到1之间,取值越大表示越相似。dice coefficient定义如下:
其中其中 是和之间的交集,和分表表示和的元素的个数,分子乘为了保证分母重复计算后取值范围在之间。
因此dice loss可以写为:
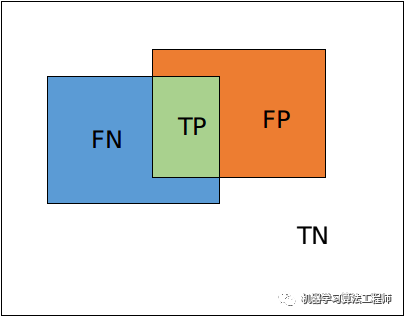
对于二分类问题,一般预测值分为以下几种:
TP: true positive,真阳性,预测是阳性,预测对了,实际也是正例。
TN: true negative,真阴性,预测是阴性,预测对了,实际也是负例。
FP: false positive,假阳性,预测是阳性,预测错了,实际是负例。
FN: false negative,假阴性,预测是阴性,预测错了,实际是正例。
这里dice coefficient可以写成如下形式:
而我们知道:
可见dice coefficient是等同「F1 score」,直观上dice coefficient是计算与的相似性,本质上则同时隐含precision和recall两个指标。可见dice loss是直接优化「F1 score」。
这里考虑通用的实现方式来表达,定义:
其中为为网络预测值,是经过sigmoid或softmax的值,取值在之间。为target值,取值非0即1。
dice loss 有以下几种形式:
「形式1」:
「形式2(原论文形式)」:
「形式3」:
为加平方的方式获取:
为一个极小的数,一般称为平滑系数,有两个作用:
防止分母预测为0。值得说明的是,一般分割网络输出经过sigmoid 或 softmax,是不存在输出为绝对0的情况。这里加平滑系数主要防止一些极端情况,输出位数太小而导致编译器丢失数位的情况。
平滑系数可以起到平滑loss和梯度的操作。
不同实现形式计算不同,但本质并无太大区别,本文主要讨论形式1。下面为pytorch的实现方式:
def dice_loss(target,predictive,ep=1e-8):intersection = 2 * torch.sum(predictive * target) + epunion = torch。sum(predictive) + torch.sum(target) + eploss = 1 - intersection / unionreturn loss
梯度分析
从dice loss的定义可以看出,dice loss 是一种「区域相关」的loss。意味着某像素点的loss以及梯度值不仅和该点的label以及预测值相关,和其他点的label以及预测值也相关,这点和ce (交叉熵cross entropy) loss 不同。因此分析起来比较复杂,这里我们简化一下,首先从loss曲线和求导曲线对单点输出方式分析。然后对于多点输出的情况,利用模拟预测输出来分析其梯度。而多分类softmax是sigmoid的一种推广,本质一样,所以这里只考虑sigmoid输出的二分类问题,首先sigmoid函数定义如下:
求导:
单点输出的形式
单点输出的情况是网络输出的是一个数值而一个map,单点输出的dice loss公式如下:
绘制曲线图如下,其中蓝色的为ce loss,橙色的为dice loss。

当 时,在一个较大的范围内,loss的值都很大接近1。只有预测非常小,接近于0(和 量级相近)时loss才会变小,而这种情况出现的概率也较小。一般情况下,在正常范围内,预测不管为任何值,都无差别对待,loss 都统一非常大。 当时,在0左右较小的范围内,保持不错的特性。但随着远离0点,loss呈现饱和现象。
计算梯度:
绘图如下:
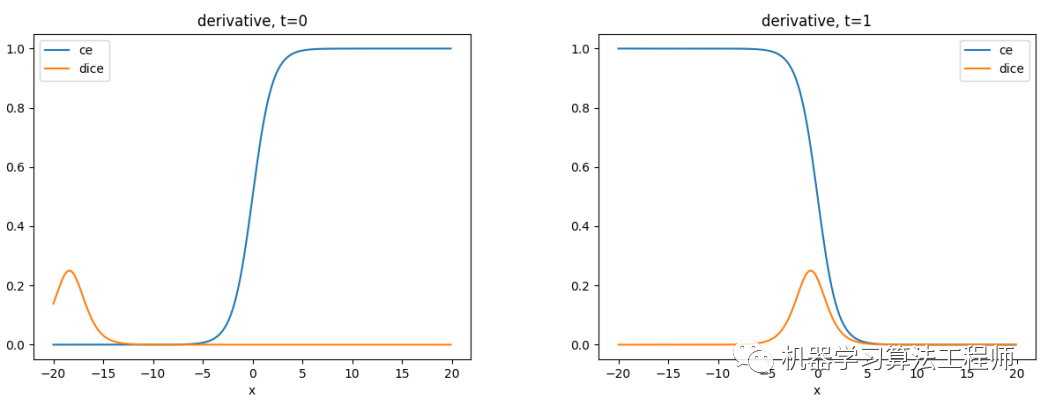
梯度正负符号代表梯度的方向,网络采用梯度下降法更新参数,当梯度为正时,参数更新变小,当梯度为负时参数更新变大。这里为了讨论正负样本的梯度关系,所以取了绝对值操作。
当 时,同样在的正常范围内,的梯度值接近0 。实际上,由于平滑系数的存在,该梯度不为0,而是一个非常小的值 。该值过于小,对网络的贡献也非常有限。 当时,在0点附近存在一个峰值,此时接近0.5。随着预测值越接近1或0,梯度越小,出现梯度饱和的现象。
一般神经网络训练之前都会采取权重初始化,不管是Xavier初始化还是Kaiming初始化(或者其他初始化的方法), 输出是接近于0的。再回到上面的图,可见此时正样本()的监督是远远大于负样本()的监督,可以认为网络前期会重点挖掘正样本。而ce loss 是平等对待两种样本的。
多点情况分析
dice loss 是应用于语义分割而不是分类任务,并且是一个区域相关的loss,因此更适合针对多点的情况进行分析。由于多点输出的情况比较难用曲线呈现,这里使用模拟预测值的形式观察梯度的变化。
下图为原始图片和对应的label:

为了便于梯度可视化,这里对梯度求绝对值操作,因为我们关注的是梯度的大小而非方向。另外梯度值都乘以保证在容易辨认的范围。
首先定义如下热图,值越大,颜色越亮,反之亦然:

预测值变化(值,图上的数字为预测值区间):

dice loss 对应值的梯度:

ce loss 对应值的梯度:

可以看出:
一般情况下,dice loss 正样本的梯度大于背景样本的; 尤其是刚开始网络预测接近0.5的时候,这点和单点输出的现象一致。说明 dice loss 更具有指向性,更加偏向于正样本,保证有较低的FN。 负样本(背景区域)也会产生梯度。 极端情况下,网络预测接近0或1时,对应点梯度值极小,dice loss 存在梯度饱和现象。此时预测失败(FN,FP)的情况很难扭转回来。不过该情况出现的概率较低,因为网络初始化输出接近0.5,此时具有较大的梯度值。而网络通过梯度下降的方式更新参数,只会逐渐削弱预测失败的像素点。 对于ce loss,当前的点的梯度仅和当前预测值与label的距离相关,预测越接近label,梯度越小。当网络预测接近0或1时,梯度依然保持该特性。 对比发现, 训练前中期,dice loss下正样本的梯度值相对于ce loss,颜色更亮,值更大。说明dice loss 对挖掘正样本更加有优势。
「dice loss为何能够解决正负样本不平衡问题?」
因为dice loss是一个区域相关的loss。区域相关的意思就是,当前像素的loss不光和当前像素的预测值相关,和其他点的值也相关。dice loss的求交的形式可以理解为mask掩码操作,因此不管图片有多大,固定大小的正样本的区域计算的loss是一样的,对网络起到的监督贡献不会随着图片的大小而变化。从上图可视化也发现,训练更倾向于挖掘前景区域,正负样本不平衡的情况就是前景占比较小。而ce loss 会公平处理正负样本,当出现正样本占比较小时,就会被更多的负样本淹没。
「dice loss背景区域能否起到监督作用?」
可以的,但是会小于前景区域。和直观理解不同的是,随着训练的进行,背景区域也能产生较为可观的梯度。这点和单点的情况分析不同。这里求偏导,当时:
可以看出, 背景区域的梯度是存在的,只有预测值命中的区域极小时, 背景梯度才会很小.
「dice loss 为何训练会很不稳定?」
在使用dice loss时,一般正样本为小目标时会产生严重的震荡。因为在只有前景和背景的情况下,小目标一旦有部分像素预测错误,那么就会导致loss值大幅度的变动,从而导致梯度变化剧烈。可以假设极端情况,只有一个像素为正样本,如果该像素预测正确了,不管其他像素预测如何,loss 就接近0,预测错误了,loss 接近1。而对于ce loss,loss的值是总体求平均的,更多会依赖负样本的地方。
总结
dice loss 对正负样本严重不平衡的场景有着不错的性能,训练过程中更侧重对前景区域的挖掘。但训练loss容易不稳定,尤其是小目标的情况下。另外极端情况会导致梯度饱和现象。因此有一些改进操作,主要是结合ce loss等改进,比如: dice+ce loss,dice + focal loss等,本文不再论述。
机器学习算法工程师
一个用心的公众号
