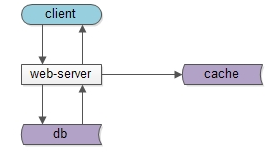
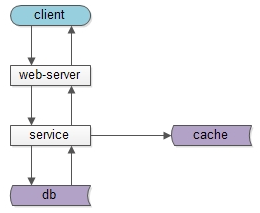
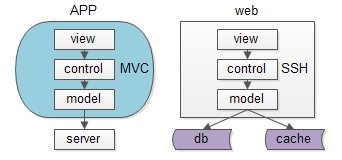
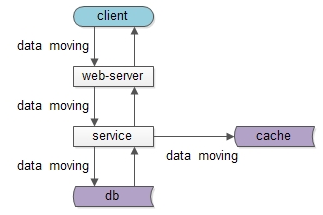
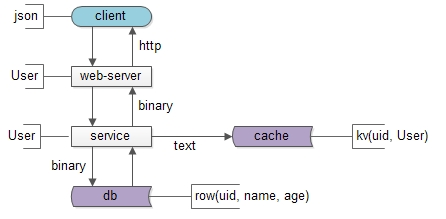
互联网分层架构的本质架构师之路共 1546字,需浏览 4分钟 · 2020-08-12 经常有朋友问我,为什么要做分层架构,什么时候架构要抽象一层,今天来聊一聊这个问题。上图是一个典型的互联网分层架构:(1)客户端层:典型调用方是browser或者APP;(2)站点应用层:实现核心业务逻辑,从下游获取数据,对上游返回html或者json;(3)数据-缓存层:加速访问存储;(4)数据-数据库层:固化数据存储;如果实施了服务化,这个分层架构图可能是这样:中间多了一个服务层。同一个层次的内部,例如端上的APP,以及web-server,也都有进行MVC分层:(1)view层:展现;(2)control层:逻辑;(3)model层:数据;可以看到,每个工程师骨子里,都潜移默化的实施着分层架构。那么,互联网分层架构的本质究竟是什么呢?如果我们仔细思考会发现,不管是跨进程的分层架构,还是进程内的MVC分层,都是一个“数据移动”,然后“被处理”和“被呈现”的过程,归根结底一句话:互联网分层架构,是一个数据移动,处理,呈现的过程,其中数据移动是整个过程的核心。如上图所示,数据处理和呈现要CPU计算,CPU是固定不动的:(1)db/service/web-server都部署在固定的集群上;(2)端上,不管是browser还是APP,也有固定的CPU处理;数据是移动的:(1)跨进程移动:数据从数据库和缓存里,转移到service层,到web-server层,到client层;(2)同进程移动:数据从model层,转移到control层,转移到view层;数据要移动,所以有两个东西很重要:(1)数据传输的格式;(2)数据在各层次的形态;先看数据传输的格式,即协议很重要:(1)service与db/cache之间,二进制协议/文本协议是数据传输的载体;(2)web-server与service之间,RPC的二进制协议是数据传输的载体;(3)client和web-server之间,http协议是数据传输的载体;再看数据在各层次的形态,以用户数据为例:(1)db层,数据是以“行”为单位存在的row(uid, name, age);(2)cache层,数据是以kv的形式存在的kv(uid -> User);(3)service层,会把row或者kv转化为对程序友好的User对象;(4)web-server层,会把对程序友好的User对象转化为对http友好的json对象;(5)client层:最终端上拿到的是json对象;结论:互联网分层架构的本质,是数据的移动。为什么要说这个,这将会引出“分层架构演进”的核心原则与方法:(1)让上游更高效的获取与处理数据,复用;(2)让下游能屏蔽数据的获取细节,封装;有了上面的铺垫,水友经常问的这些问题:(1)是否需要引入DAO层,什么时机引入;(2)是否需要服务化,什么时机服务化;(3)是否需要抽取通用中台业务,什么时机抽取;(4)是否需要前后端分离,什么时机分离;就非常好回答了,下期和大家深究。画外音:网友们的这些提问,其实很难回答。在不了解业务发展阶段,业务规模,数据量并发量的情况下,妄下YES或NO的结论,本身就是不负责任的。总结(1)互联网分层架构的本质,是数据的移动;(2)互联网分层架构中,数据的传输格式(协议)与数据在各层次的形态很重要;(3)互联网分层架构演进的核心原则与方法:封装与复用;架构师之路训练营,一起玩架构希望能引发大家的思考。阅读原文,更多收获。 浏览 11点赞 评论 收藏 分享 手机扫一扫分享举报评论图片表情视频评价全部评论推荐一文读懂互联网的架构本质【引子】谈到互联网,很多人脑海中会出现各种各样的术语和服务,但是互联网是如何设计并构建的呢?作为一个喔家ArchiSelf0什么是架构和架构的本质?开源Linux0三层架构到DDD分层架构的演变跟着阿笨一起玩NET0标准Web系统的架构分层跟着阿笨一起玩NET0互联网架构:屡试不爽的架构三马车互联网架构师0单体分层应用架构剖析京东科技开发者0阿里开源的整洁面向对象分层架构公众号程序猿DD0实时数仓项目架构分层肉眼品世界0还在搞三层架构?DDD 分层架构了解下!小哈学Java0还在搞三层架构?DDD 分层架构了解下!互联网架构师0点赞 评论 收藏 分享 手机扫一扫分享举报