
如何用「逻辑回归」构建金融评分卡模型?(上)
共 3219字,需浏览 7分钟
· 2020-07-28
市面上关于lr 的书籍和文章大部分的讲解都是针对 lr一些基本理论或者一些推导公式。掌握这些还远远不够,要想让lr发挥其最大效果,必须要有一套科学的、严密的数据预处理流程。
和市面上对lr算法的讲解不同,本文将以金融评分卡模型为例,讲解一整套lr配套的数据处理流程,包括数据获取,EDA (探索性数据分析),数据预处理,到变量筛选,lr模型的开发和评估,生成评分卡模型。希望大家在阅读本篇文章之后能够轻松驾驭lr算法。
1. 评分卡模型的背景知识
风控顾名思义就是风险控制,指风险管理者采取各种措施和方法,消灭或减少风险事件发生的各种可能性,或风险事件发生时造成的损失。
信用评分卡模型是最常见的金融风控手段之一,它是指根据客户的各种属性和行为数据,利用一定的信用评分模型,对客户进行信用评分,据此决定是否给予授信以及授信的额度和利率,从而识别和减少在金融交易中存在的交易风险。
评分卡模型在不同的业务阶段体现的方式和功能也不一样。按照借贷用户的借贷时间,评分卡模型可以划分为以下三种:
贷前:申请评分卡(Application score card),又称为A卡
贷中:行为评分卡(Behavior score card),又称为B卡
贷后:催收评分卡(Collection score card),又称为C卡
以下为评分卡模型的示意图:
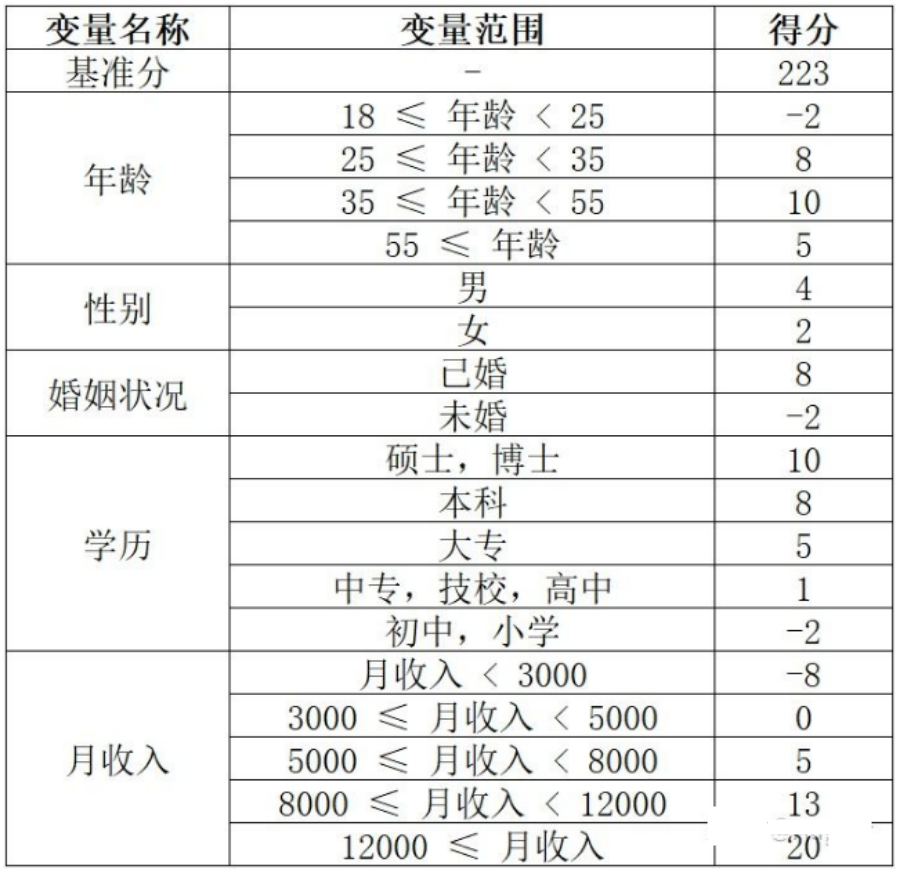
那么怎么利用评分卡对用户进行评分呢?一个用户总的评分等于基准分加上对客户各个属性的评分。以上面的评分卡为例:
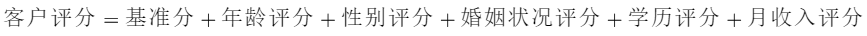
举个例子某客户年龄为27岁,性别为男,婚姻状况为已婚,学历为本科,月收入为10000,那么他的评分为:
Q1: 请计算以上评分卡模型的最低分和最高分
最低分为基准分与每个字段最低分相加:
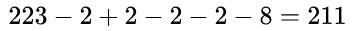
最高分为基准分与每个字段最高分相加:
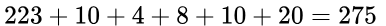
以上我们基本了解了评分卡模型的具体用法,看到以上评分卡案例之后,相信很多人肯定会有以下三个疑问:
用户的属性有千千万万个维度,而评分卡模型所选用的字段在30个以下,那么怎样挑选这些字段呢?
评分法卡模型采用的是对每个字段的分段进行评分,那么怎样对评分卡进行有效分段呢?
最关键的,也是大家最关心的问题是怎样对字段的每个分段进行评分呢?这个评分是怎么来的?
2.评分卡模型的开发
1.总体流程介绍
信用评分卡的开发有一套科学的、严密的流程,包括数据获取,EDA,数据预处理,到变量筛选,lr模型的开发和评估,生成评分卡模型以及布置上线和模型监测。典型的开发流程如下图所示:
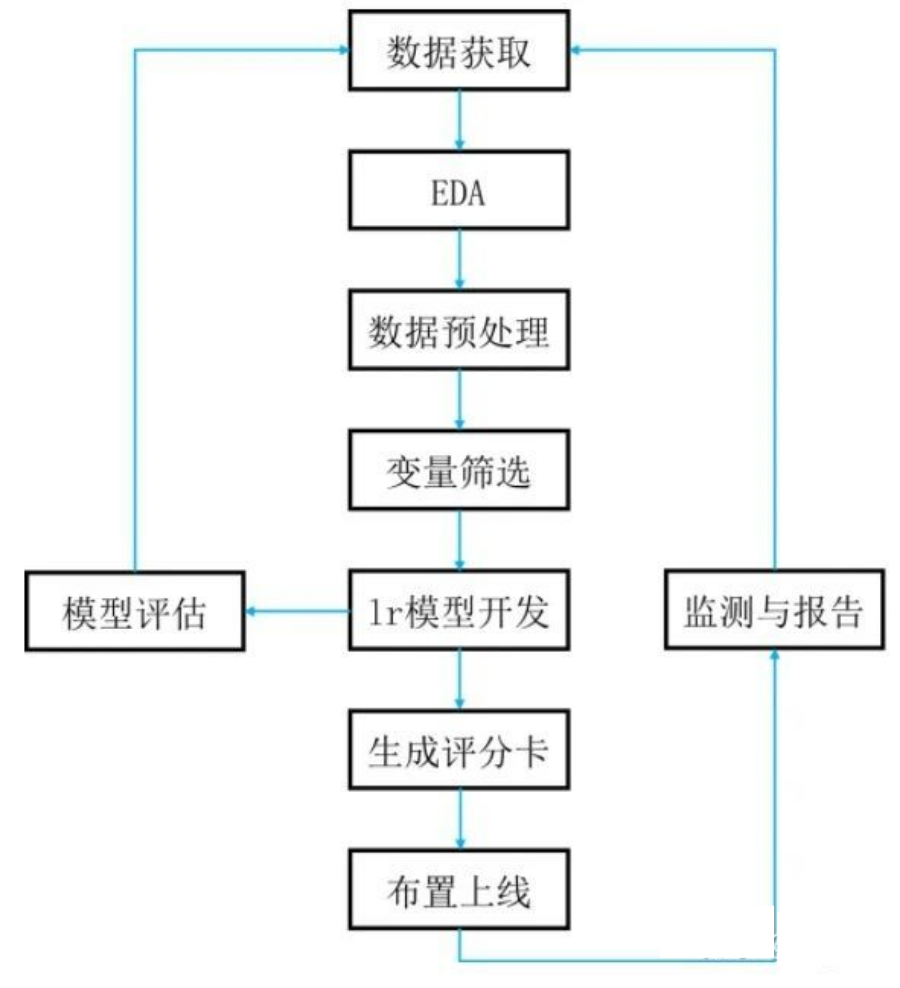
本文仅介绍线下评分卡模型的开发,即数据获取,EDA, 数据预处理,变量筛选,lr模型开发,模型评估和生成评分卡。
2.数据获取
数据的获取途径主要有两个:
金融机构自身字段:例用户的年龄,户籍,性别,收入,负债比,在本机构的借款和还款行为等
第三方机构的数据:如用户在其他机构的借贷行为,用户的消费行为数据等
3.EDA(探索性数据分析)
该步骤主要是获取数据的大概情况,例如每个字段的缺失值情况、异常值情况、平均值、中位数、最大值、最小值、分布情况等。以便制定合理的数据预处理方案。
4.数据预处理
数据预处理主要包括数据清洗,变量分箱和 WOE 编码三个步骤。
4.1数据清洗
数据清洗主要是对原始数据中脏数据,缺失值,异常值进行处理。关于对缺失值和异常值的处理,我们采用的方法非常简单粗暴,即删除缺失率超过某一阈值(阈值自行设定,可以为30%,50%,90%等)的变量,将剩余变量中的缺失值和异常值作为一种状态 。
4.2变量分箱
在这里我们回答第二个问题评分卡是怎样对变量进行分段的,评分卡模型通过对变量进行分箱来实现变量的分段。那么什么是分箱呢?以下为分箱的定义:
对连续变量进行分段离散化
将多状态的离散变量进行合并,减少离散变量的状态数
常见的分箱类型有以下几种,下面将一一讲解:
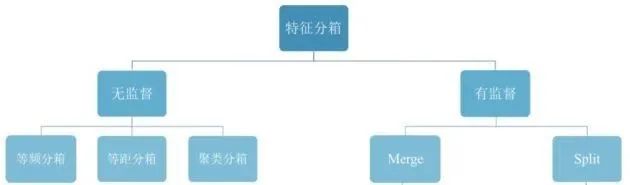
1. 无监督分箱
无监督的分箱主要包括以下几类:
等频分箱:把自变量按从小到大的顺序排列,根据自变量的个数等分为k部分,每部分作为一个分箱
等距分箱:把自变量按从小到大的顺序排列,将自变量的取值范围分为k个等距的区间,每个区间作为一个分箱
聚类分箱:用k-means聚类法将自变量聚为k类,但在聚类过程中需要保证分箱的有序性
由于无监督分箱仅仅考虑了各个变量自身的数据结构,并没有考虑自变量与目标变量之间的关系,因此无监督分箱不一定会带来模型性能的提升。
2. 有监督分箱
包括 Split 分箱和 Merge 分箱。
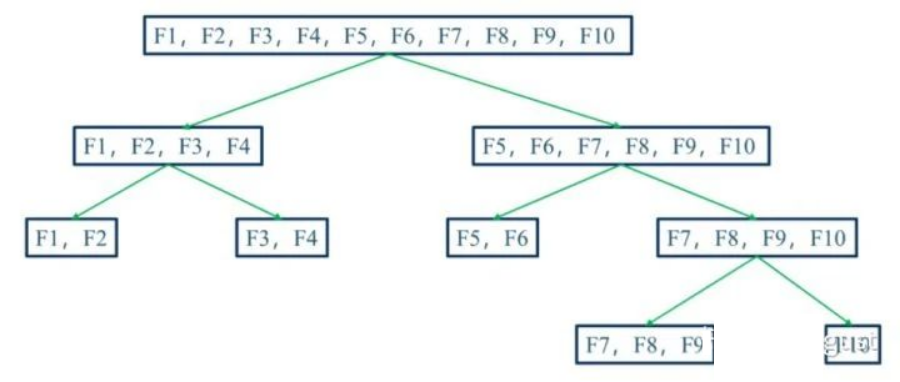
1)Split 分箱是一种自上而下(即基于分裂)的数据分段方法。如下图所示,Split 分箱和决策树比较相似,切分点的选择指标主要有 entropy,gini 指数和 IV 值等。
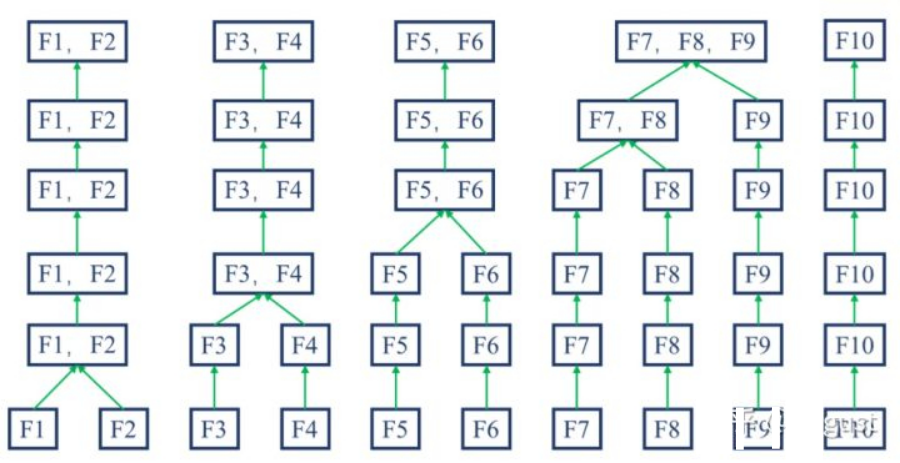
2)Merge 分箱,是一种自底向上(即基于合并)的数据离散化方法。如下图所示为Merge 分箱的示意图,Merge 分箱常见的类型为Chimerge分箱。
3)Chimerge 分箱是目前最流行的分箱方式之一,其基本思想是如果两个相邻的区间具有类似的类分布,则这两个区间合并;否则,它们应保持分开。Chimerge通常采用卡方值来衡量两相邻区间的类分布情况。
3. Chimerge的具体算法如下
1)输入:分箱的最大区间数n
2)初始化
连续值按升序排列,离散值先转化为坏客户的比率,然后再按升序排列
为了减少计算量,对于状态数大于某一阈值 (建议为100) 的变量,利用等频分箱进行粗分箱
若有缺失值,则缺失值单独作为一个分箱
3)合并区间
计算每一对相邻区间的卡方值
将卡方值最小的一对区间合并
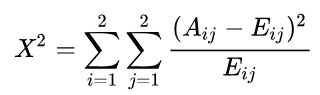

重复以上两个步骤,直到分箱数量不大于n
4)分箱后处理
对于坏客户比例为 0 或 1 的分箱进行合并 (一个分箱内不能全为好客户或者全为坏客户)
对于分箱后某一箱样本占比超过 95% 的箱子进行删除
检查缺失分箱的坏客户比例是否和非缺失分箱相等,如果相等,进行合并
5)输出:分箱后的数据和分箱区间
Q2: 一般一个评分卡模型的有效持续时间是 1个月左右甚至更长时间,中间也许会有一些客户的数据发生变化,比如一个月之内突然换工作,工资上涨等等,针对这种情况,我们该怎样处理呢?
这里我们需要假设客户在短期内属性变化不会太大,即使客户的属性变化,只要在同一分箱中,依然会给这个客户相同的分数。举例来说:对于工资我们可以划分为5箱,即<3000, 3000-5000, 5000-8000, 8000-12000, >12000,假设一个客户的工资为9000,在一个月内工资上涨,那我们就假设这个客户的工资上涨之后不会超过12000,也就是说依然在8000-12000分箱中。
这样在考虑客户工资变化的前提下,不会因为客户工资的发生变化而变成了另外一个人,保证了模型的稳定性。
Q3:上文说到将变量中的缺失值作为一种状态是什么意思?
这里的意思是说让缺失值单独分为一箱。
Q4:比如年龄变量中出现“500岁”这种异常字段该怎样处理?
对于年龄特征我们划分为4段,即18-25, 25-35, 35-55, > 55,我们可以直接把500划分到>55这一个分箱中。另外我们也可以通过一些手段检测出异常值,将异常值单独分为一箱。
总结一下特征分箱的优势:
特征分箱可以有效处理特征中的缺失值和异常值
特征分箱后,数据和模型会更稳定
特征分箱可以简化逻辑回归模型,降低模型过拟合的风险,提高模型的泛化能力
将所有特征统一变换为类别型变量
分箱后变量才可以使用标准的评分卡格式,即对不同的分段进行评分
End. 作者:August 来源:知乎专栏 本文为转载分享,如侵权请联系后台删除